{"title":"从Twitter聊天中早期检测欺诈性COVID-19产品:使用异常检测的数据集和基线方法","authors":"Abeed Sarker, Sahithi Lakamana, Ruqi Liao, Aamir Abbas, Yuan-Chi Yang, Mohammed Al-Garadi","doi":"10.2196/43694","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Social media has served as a lucrative platform for spreading misinformation and for promoting fraudulent products for the treatment, testing, and prevention of COVID-19. This has resulted in the issuance of many warning letters by the US Food and Drug Administration (FDA). While social media continues to serve as the primary platform for the promotion of such fraudulent products, it also presents the opportunity to identify these products early by using effective social media mining methods.</p><p><strong>Objective: </strong>Our objectives were to (1) create a data set of fraudulent COVID-19 products that can be used for future research and (2) propose a method using data from Twitter for automatically detecting heavily promoted COVID-19 products early.</p><p><strong>Methods: </strong>We created a data set from FDA-issued warnings during the early months of the COVID-19 pandemic. We used natural language processing and time-series anomaly detection methods for automatically detecting fraudulent COVID-19 products early from Twitter. Our approach is based on the intuition that increases in the popularity of fraudulent products lead to corresponding anomalous increases in the volume of chatter regarding them. We compared the anomaly signal generation date for each product with the corresponding FDA letter issuance date. We also performed a brief manual analysis of chatter associated with 2 products to characterize their contents.</p><p><strong>Results: </strong>FDA warning issue dates ranged from March 6, 2020, to June 22, 2021, and 44 key phrases representing fraudulent products were included. From 577,872,350 posts made between February 19 and December 31, 2020, which are all publicly available, our unsupervised approach detected 34 out of 44 (77.3%) signals about fraudulent products earlier than the FDA letter issuance dates, and an additional 6 (13.6%) within a week following the corresponding FDA letters. Content analysis revealed <i>misinformation</i>, <i>information</i>, <i>political,</i> and <i>conspiracy theories</i> to be prominent topics.</p><p><strong>Conclusions: </strong>Our proposed method is simple, effective, easy to deploy, and does not require high-performance computing machinery unlike deep neural network-based methods. The method can be easily extended to other types of signal detection from social media data. The data set may be used for future research and the development of more advanced methods.</p>","PeriodicalId":73554,"journal":{"name":"JMIR infodemiology","volume":"3 ","pages":"e43694"},"PeriodicalIF":2.3000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10131818/pdf/","citationCount":"0","resultStr":"{\"title\":\"The Early Detection of Fraudulent COVID-19 Products From Twitter Chatter: Data Set and Baseline Approach Using Anomaly Detection.\",\"authors\":\"Abeed Sarker, Sahithi Lakamana, Ruqi Liao, Aamir Abbas, Yuan-Chi Yang, Mohammed Al-Garadi\",\"doi\":\"10.2196/43694\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Social media has served as a lucrative platform for spreading misinformation and for promoting fraudulent products for the treatment, testing, and prevention of COVID-19. This has resulted in the issuance of many warning letters by the US Food and Drug Administration (FDA). While social media continues to serve as the primary platform for the promotion of such fraudulent products, it also presents the opportunity to identify these products early by using effective social media mining methods.</p><p><strong>Objective: </strong>Our objectives were to (1) create a data set of fraudulent COVID-19 products that can be used for future research and (2) propose a method using data from Twitter for automatically detecting heavily promoted COVID-19 products early.</p><p><strong>Methods: </strong>We created a data set from FDA-issued warnings during the early months of the COVID-19 pandemic. We used natural language processing and time-series anomaly detection methods for automatically detecting fraudulent COVID-19 products early from Twitter. Our approach is based on the intuition that increases in the popularity of fraudulent products lead to corresponding anomalous increases in the volume of chatter regarding them. We compared the anomaly signal generation date for each product with the corresponding FDA letter issuance date. We also performed a brief manual analysis of chatter associated with 2 products to characterize their contents.</p><p><strong>Results: </strong>FDA warning issue dates ranged from March 6, 2020, to June 22, 2021, and 44 key phrases representing fraudulent products were included. From 577,872,350 posts made between February 19 and December 31, 2020, which are all publicly available, our unsupervised approach detected 34 out of 44 (77.3%) signals about fraudulent products earlier than the FDA letter issuance dates, and an additional 6 (13.6%) within a week following the corresponding FDA letters. Content analysis revealed <i>misinformation</i>, <i>information</i>, <i>political,</i> and <i>conspiracy theories</i> to be prominent topics.</p><p><strong>Conclusions: </strong>Our proposed method is simple, effective, easy to deploy, and does not require high-performance computing machinery unlike deep neural network-based methods. The method can be easily extended to other types of signal detection from social media data. The data set may be used for future research and the development of more advanced methods.</p>\",\"PeriodicalId\":73554,\"journal\":{\"name\":\"JMIR infodemiology\",\"volume\":\"3 \",\"pages\":\"e43694\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10131818/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR infodemiology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/43694\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR infodemiology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/43694","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
The Early Detection of Fraudulent COVID-19 Products From Twitter Chatter: Data Set and Baseline Approach Using Anomaly Detection.
Background: Social media has served as a lucrative platform for spreading misinformation and for promoting fraudulent products for the treatment, testing, and prevention of COVID-19. This has resulted in the issuance of many warning letters by the US Food and Drug Administration (FDA). While social media continues to serve as the primary platform for the promotion of such fraudulent products, it also presents the opportunity to identify these products early by using effective social media mining methods.
Objective: Our objectives were to (1) create a data set of fraudulent COVID-19 products that can be used for future research and (2) propose a method using data from Twitter for automatically detecting heavily promoted COVID-19 products early.
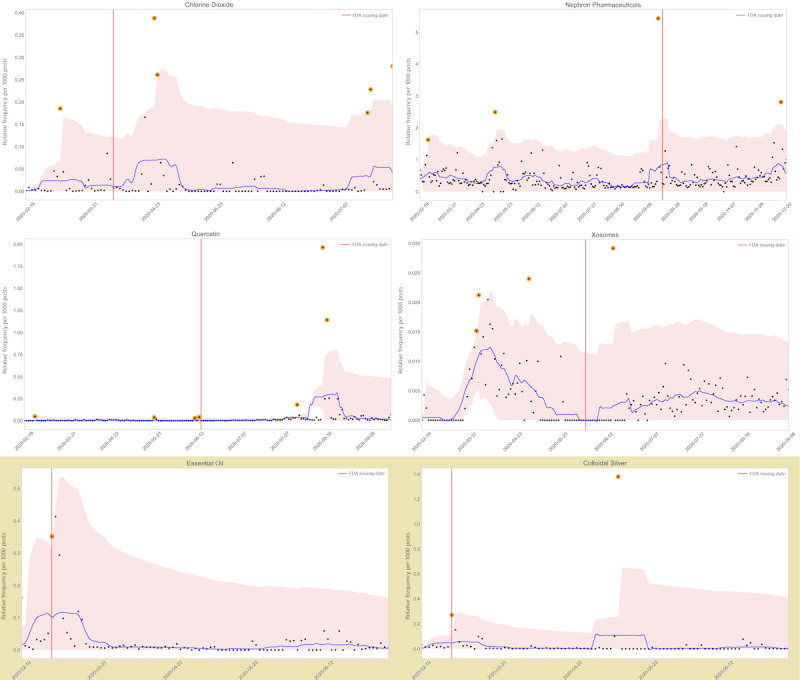
Methods: We created a data set from FDA-issued warnings during the early months of the COVID-19 pandemic. We used natural language processing and time-series anomaly detection methods for automatically detecting fraudulent COVID-19 products early from Twitter. Our approach is based on the intuition that increases in the popularity of fraudulent products lead to corresponding anomalous increases in the volume of chatter regarding them. We compared the anomaly signal generation date for each product with the corresponding FDA letter issuance date. We also performed a brief manual analysis of chatter associated with 2 products to characterize their contents.
Results: FDA warning issue dates ranged from March 6, 2020, to June 22, 2021, and 44 key phrases representing fraudulent products were included. From 577,872,350 posts made between February 19 and December 31, 2020, which are all publicly available, our unsupervised approach detected 34 out of 44 (77.3%) signals about fraudulent products earlier than the FDA letter issuance dates, and an additional 6 (13.6%) within a week following the corresponding FDA letters. Content analysis revealed misinformation, information, political, and conspiracy theories to be prominent topics.
Conclusions: Our proposed method is simple, effective, easy to deploy, and does not require high-performance computing machinery unlike deep neural network-based methods. The method can be easily extended to other types of signal detection from social media data. The data set may be used for future research and the development of more advanced methods.
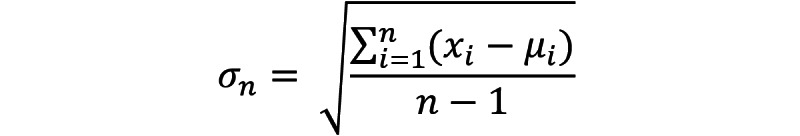
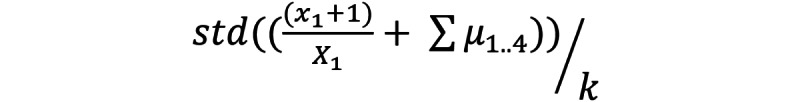


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
