Tom Strating, Leila Shafiee Hanjani, Ida Tornvall, Ruth Hubbard, Ian A Scott
{"title":"机器学习管道导航:住院病人谵妄预测模型范围综述。","authors":"Tom Strating, Leila Shafiee Hanjani, Ida Tornvall, Ruth Hubbard, Ian A Scott","doi":"10.1136/bmjhci-2023-100767","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Early identification of inpatients at risk of developing delirium and implementing preventive measures could avoid up to 40% of delirium cases. Machine learning (ML)-based prediction models may enable risk stratification and targeted intervention, but establishing their current evolutionary status requires a scoping review of recent literature.</p><p><strong>Methods: </strong>We searched ten databases up to June 2022 for studies of ML-based delirium prediction models. Eligible criteria comprised: use of at least one ML prediction method in an adult hospital inpatient population; published in English; reporting at least one performance measure (area under receiver-operator curve (AUROC), sensitivity, specificity, positive or negative predictive value). Included models were categorised by their stage of maturation and assessed for performance, utility and user acceptance in clinical practice.</p><p><strong>Results: </strong>Among 921 screened studies, 39 met eligibility criteria. In-silico performance was consistently high (median AUROC: 0.85); however, only six articles (15.4%) reported external validation, revealing degraded performance (median AUROC: 0.75). Three studies (7.7%) of models deployed within clinical workflows reported high accuracy (median AUROC: 0.92) and high user acceptance.</p><p><strong>Discussion: </strong>ML models have potential to identify inpatients at risk of developing delirium before symptom onset. However, few models were externally validated and even fewer underwent prospective evaluation in clinical settings.</p><p><strong>Conclusion: </strong>This review confirms a rapidly growing body of research into using ML for predicting delirium risk in hospital settings. Our findings offer insights for both developers and clinicians into strengths and limitations of current ML delirium prediction applications aiming to support but not usurp clinician decision-making.</p>","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"30 1","pages":""},"PeriodicalIF":4.4000,"publicationDate":"2023-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/ec/23/bmjhci-2023-100767.PMC10335592.pdf","citationCount":"0","resultStr":"{\"title\":\"Navigating the machine learning pipeline: a scoping review of inpatient delirium prediction models.\",\"authors\":\"Tom Strating, Leila Shafiee Hanjani, Ida Tornvall, Ruth Hubbard, Ian A Scott\",\"doi\":\"10.1136/bmjhci-2023-100767\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>Early identification of inpatients at risk of developing delirium and implementing preventive measures could avoid up to 40% of delirium cases. Machine learning (ML)-based prediction models may enable risk stratification and targeted intervention, but establishing their current evolutionary status requires a scoping review of recent literature.</p><p><strong>Methods: </strong>We searched ten databases up to June 2022 for studies of ML-based delirium prediction models. Eligible criteria comprised: use of at least one ML prediction method in an adult hospital inpatient population; published in English; reporting at least one performance measure (area under receiver-operator curve (AUROC), sensitivity, specificity, positive or negative predictive value). Included models were categorised by their stage of maturation and assessed for performance, utility and user acceptance in clinical practice.</p><p><strong>Results: </strong>Among 921 screened studies, 39 met eligibility criteria. In-silico performance was consistently high (median AUROC: 0.85); however, only six articles (15.4%) reported external validation, revealing degraded performance (median AUROC: 0.75). Three studies (7.7%) of models deployed within clinical workflows reported high accuracy (median AUROC: 0.92) and high user acceptance.</p><p><strong>Discussion: </strong>ML models have potential to identify inpatients at risk of developing delirium before symptom onset. However, few models were externally validated and even fewer underwent prospective evaluation in clinical settings.</p><p><strong>Conclusion: </strong>This review confirms a rapidly growing body of research into using ML for predicting delirium risk in hospital settings. Our findings offer insights for both developers and clinicians into strengths and limitations of current ML delirium prediction applications aiming to support but not usurp clinician decision-making.</p>\",\"PeriodicalId\":9050,\"journal\":{\"name\":\"BMJ Health & Care Informatics\",\"volume\":\"30 1\",\"pages\":\"\"},\"PeriodicalIF\":4.4000,\"publicationDate\":\"2023-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/ec/23/bmjhci-2023-100767.PMC10335592.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMJ Health & Care Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1136/bmjhci-2023-100767\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2023-100767","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
摘要
目的:早期识别有谵妄风险的住院病人并采取预防措施可避免高达 40% 的谵妄病例。基于机器学习(ML)的预测模型可实现风险分层和有针对性的干预,但要确定其目前的发展状况,需要对近期文献进行范围界定:我们检索了截至 2022 年 6 月的十个数据库,以了解基于 ML 的谵妄预测模型的研究情况。合格标准包括:在成人住院患者中至少使用了一种ML预测方法;以英语发表;至少报告了一项性能指标(接收者-操作者曲线下面积(AUROC)、灵敏度、特异性、阳性或阴性预测值)。对纳入的模型按其成熟阶段进行分类,并对临床实践中的性能、实用性和用户接受度进行评估:结果:在筛选出的 921 项研究中,有 39 项符合资格标准。研究结果表明:在筛选出的 921 项研究中,有 39 项研究符合资格标准,其中的硅学性能一直很高(中位数 AUROC:0.85);然而,只有 6 篇文章(15.4%)报告了外部验证,显示出性能下降(中位数 AUROC:0.75)。三项关于在临床工作流程中部署模型的研究(7.7%)报告了较高的准确性(中位数AUROC:0.92)和较高的用户接受度:讨论:ML 模型具有在症状出现前识别有谵妄风险的住院患者的潜力。然而,经过外部验证的模型很少,在临床环境中进行前瞻性评估的模型更少:本综述证实了在医院环境中使用 ML 预测谵妄风险的研究正在迅速发展。我们的研究结果为开发人员和临床医生提供了有关当前 ML 谵妄预测应用的优势和局限性的见解,这些应用旨在支持而非取代临床医生的决策。
Navigating the machine learning pipeline: a scoping review of inpatient delirium prediction models.
Objectives: Early identification of inpatients at risk of developing delirium and implementing preventive measures could avoid up to 40% of delirium cases. Machine learning (ML)-based prediction models may enable risk stratification and targeted intervention, but establishing their current evolutionary status requires a scoping review of recent literature.
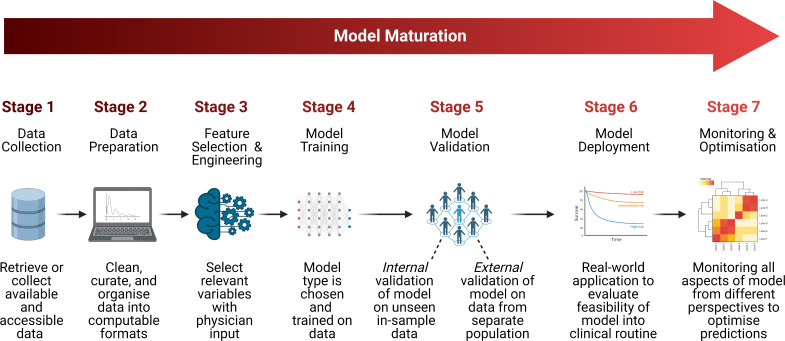
Methods: We searched ten databases up to June 2022 for studies of ML-based delirium prediction models. Eligible criteria comprised: use of at least one ML prediction method in an adult hospital inpatient population; published in English; reporting at least one performance measure (area under receiver-operator curve (AUROC), sensitivity, specificity, positive or negative predictive value). Included models were categorised by their stage of maturation and assessed for performance, utility and user acceptance in clinical practice.
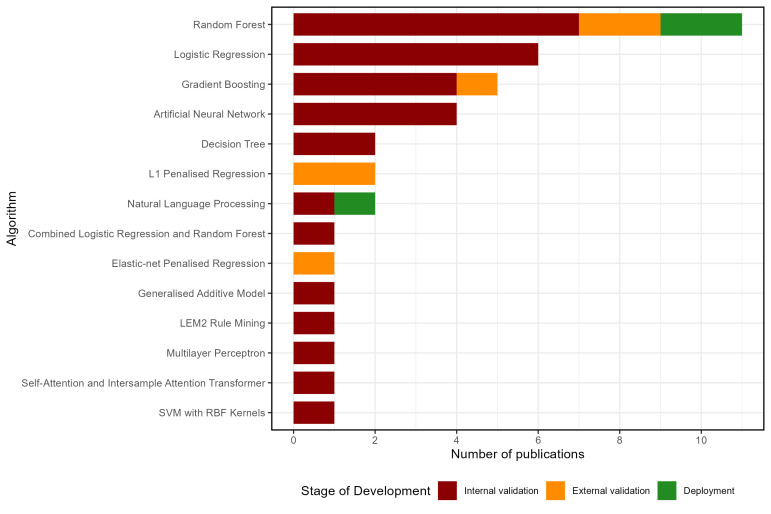
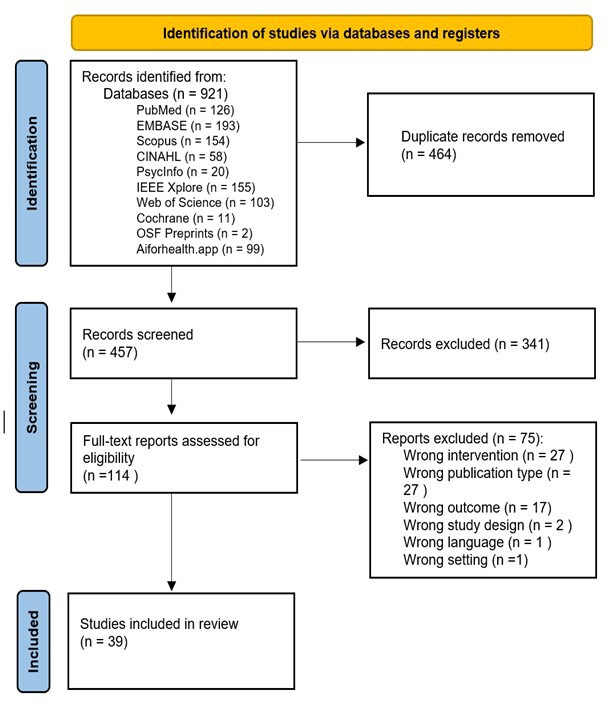
Results: Among 921 screened studies, 39 met eligibility criteria. In-silico performance was consistently high (median AUROC: 0.85); however, only six articles (15.4%) reported external validation, revealing degraded performance (median AUROC: 0.75). Three studies (7.7%) of models deployed within clinical workflows reported high accuracy (median AUROC: 0.92) and high user acceptance.
Discussion: ML models have potential to identify inpatients at risk of developing delirium before symptom onset. However, few models were externally validated and even fewer underwent prospective evaluation in clinical settings.
Conclusion: This review confirms a rapidly growing body of research into using ML for predicting delirium risk in hospital settings. Our findings offer insights for both developers and clinicians into strengths and limitations of current ML delirium prediction applications aiming to support but not usurp clinician decision-making.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
