{"title":"A comprehensive evaluation of deep models and optimizers for Indian sign language recognition","authors":"Prachi Sharma, Radhey Shyam Anand","doi":"10.1016/j.gvc.2021.200032","DOIUrl":null,"url":null,"abstract":"<div><p>Deep Learning has become popular among researchers for a long time, and still, new deep convolution neural networks come into the picture very frequently. However, it is challenging to select the best amongst such networks due to their dependence on the tuning of optimization hyperparameters, which is a trivial task. This situation motivates the current study, in which we perform a systematic evaluation and statistical analysis of pre-trained deep models. It is the first comprehensive analysis of pre-trained deep models, gradient-based optimizers and optimization hyperparameters for static Indian sign language recognition. A three-layered CNN model is also proposed and trained from scratch, which attained the best recognition accuracy of 99.0% and 97.6% on numerals and alphabets of a public ISL dataset. Among pre-trained models, ResNet152V2 performed better than other models with a recognition accuracy of 96.2% on numerals and 90.8% on alphabets of the ISL dataset. Our results reinforce the hypothesis for pre-trained deep models that, in general, a pre-trained deep network adequately tuned can yield results way more than the state-of-the-art machine learning techniques without having to train the whole model but only a few top layers for ISL recognition. The effect of hyperparameters like learning rate, batch size and momentum is also analyzed and presented in the paper.</p></div>","PeriodicalId":100592,"journal":{"name":"Graphics and Visual Computing","volume":"5 ","pages":"Article 200032"},"PeriodicalIF":0.0000,"publicationDate":"2021-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1016/j.gvc.2021.200032","citationCount":"12","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Graphics and Visual Computing","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2666629421000152","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/8/4 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 12
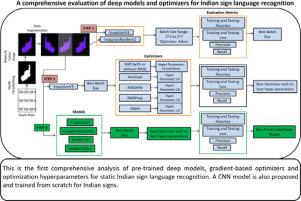
Abstract
Deep Learning has become popular among researchers for a long time, and still, new deep convolution neural networks come into the picture very frequently. However, it is challenging to select the best amongst such networks due to their dependence on the tuning of optimization hyperparameters, which is a trivial task. This situation motivates the current study, in which we perform a systematic evaluation and statistical analysis of pre-trained deep models. It is the first comprehensive analysis of pre-trained deep models, gradient-based optimizers and optimization hyperparameters for static Indian sign language recognition. A three-layered CNN model is also proposed and trained from scratch, which attained the best recognition accuracy of 99.0% and 97.6% on numerals and alphabets of a public ISL dataset. Among pre-trained models, ResNet152V2 performed better than other models with a recognition accuracy of 96.2% on numerals and 90.8% on alphabets of the ISL dataset. Our results reinforce the hypothesis for pre-trained deep models that, in general, a pre-trained deep network adequately tuned can yield results way more than the state-of-the-art machine learning techniques without having to train the whole model but only a few top layers for ISL recognition. The effect of hyperparameters like learning rate, batch size and momentum is also analyzed and presented in the paper.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
