Gábor Simon, Tímea Bajzát, Júlia Ballagó, Zsuzsanna Havasi, Emese K. Molnár, Eszter Szlávich
{"title":"When MIPVU goes to no man’s land: a new language resource for hybrid, morpheme-based metaphor identification in Hungarian","authors":"Gábor Simon, Tímea Bajzát, Júlia Ballagó, Zsuzsanna Havasi, Emese K. Molnár, Eszter Szlávich","doi":"10.1007/s10579-023-09705-9","DOIUrl":null,"url":null,"abstract":"<p>The aim of the article is to present a new language resource for metaphor analysis in corpora that is (i) a MIPVU-inspired, morpheme-based process for identifying metaphor in Hungarian and (ii) the refinement and innovative version of metaphor identification extending the scope of the process to multi-word expressions. The elaboration of language-specific protocols in metaphor identification has become one of the central endeavors in contemporary cross-linguistic research on metaphor, but there is a gap in the field regarding languages with rich morphology, especially in the case of Hungarian. To fill this gap, we developed a hybrid, morpheme-based version of the original method, which can handle morphologically complex metaphorical expressions. Additional innovations of our protocol are the measurement and tagging of idiomaticity in metaphors based on collocation analysis and the identification of semantic relationships between the components of metaphorical expressions. The present paper discusses both the theoretical motivation and the practical details of the adapted method for metaphor identification. As a conclusion, the presented protocol can provide new answers to the questions of metaphor identification in languages with rich morphology and shed new light on the internal semantic organization of linguistic metaphors.</p>","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"9 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2023-12-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10579-023-09705-9","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
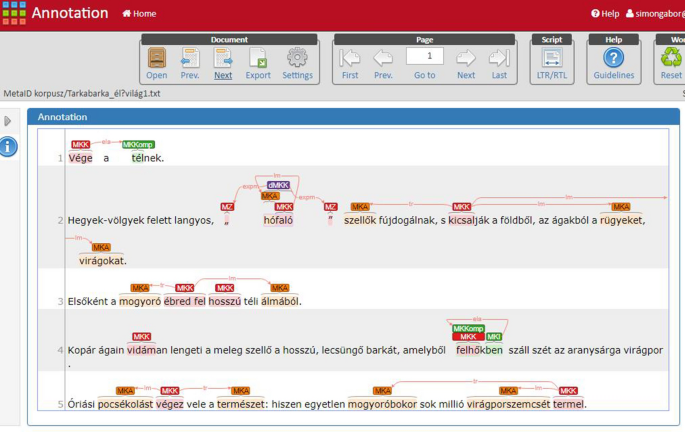
The aim of the article is to present a new language resource for metaphor analysis in corpora that is (i) a MIPVU-inspired, morpheme-based process for identifying metaphor in Hungarian and (ii) the refinement and innovative version of metaphor identification extending the scope of the process to multi-word expressions. The elaboration of language-specific protocols in metaphor identification has become one of the central endeavors in contemporary cross-linguistic research on metaphor, but there is a gap in the field regarding languages with rich morphology, especially in the case of Hungarian. To fill this gap, we developed a hybrid, morpheme-based version of the original method, which can handle morphologically complex metaphorical expressions. Additional innovations of our protocol are the measurement and tagging of idiomaticity in metaphors based on collocation analysis and the identification of semantic relationships between the components of metaphorical expressions. The present paper discusses both the theoretical motivation and the practical details of the adapted method for metaphor identification. As a conclusion, the presented protocol can provide new answers to the questions of metaphor identification in languages with rich morphology and shed new light on the internal semantic organization of linguistic metaphors.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
