{"title":"Toxic comment classification and rationale extraction in code-mixed text leveraging co-attentive multi-task learning","authors":"Kiran Babu Nelatoori, Hima Bindu Kommanti","doi":"10.1007/s10579-023-09708-6","DOIUrl":null,"url":null,"abstract":"<p>Detecting toxic comments and rationale for the offensiveness of a social media post promotes moderation of social media content. For this purpose, we propose a Co-Attentive Multi-task Learning (CA-MTL) model through transfer learning for low-resource Hindi-English (commonly known as Hinglish) toxic texts. Together, the cooperative tasks of rationale/span detection and toxic comment classification create a strong multi-task learning objective. A task collaboration module is designed to leverage the bi-directional attention between the classification and span prediction tasks. The combined loss function of the model is constructed using the individual loss functions of these two tasks. Although an English toxic span detection dataset exists, one for Hinglish code-mixed text does not exist as of today. Hence, we developed a dataset with toxic span annotations for Hinglish code-mixed text. The proposed CA-MTL model is compared against single-task and multi-task learning models that lack the co-attention mechanism, using multilingual and Hinglish BERT variants. The F1 scores of the proposed CA-MTL model with HingRoBERTa encoder for both tasks are significantly higher than the baseline models. <i>Caution:</i> This paper may contain words disturbing to some readers.</p>","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"27 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-01-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10579-023-09708-6","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
Abstract
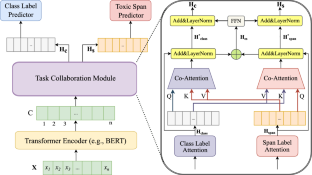
Detecting toxic comments and rationale for the offensiveness of a social media post promotes moderation of social media content. For this purpose, we propose a Co-Attentive Multi-task Learning (CA-MTL) model through transfer learning for low-resource Hindi-English (commonly known as Hinglish) toxic texts. Together, the cooperative tasks of rationale/span detection and toxic comment classification create a strong multi-task learning objective. A task collaboration module is designed to leverage the bi-directional attention between the classification and span prediction tasks. The combined loss function of the model is constructed using the individual loss functions of these two tasks. Although an English toxic span detection dataset exists, one for Hinglish code-mixed text does not exist as of today. Hence, we developed a dataset with toxic span annotations for Hinglish code-mixed text. The proposed CA-MTL model is compared against single-task and multi-task learning models that lack the co-attention mechanism, using multilingual and Hinglish BERT variants. The F1 scores of the proposed CA-MTL model with HingRoBERTa encoder for both tasks are significantly higher than the baseline models. Caution: This paper may contain words disturbing to some readers.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
