{"title":"Ingress: an automated incremental graph processing system","authors":"Shufeng Gong, Chao Tian, Qiang Yin, Zhengdong Wang, Song Yu, Yanfeng Zhang, Wenyuan Yu, Liang Geng, Chong Fu, Ge Yu, Jingren Zhou","doi":"10.1007/s00778-024-00838-z","DOIUrl":null,"url":null,"abstract":"<p>The graph data keep growing over time in real life. The ever-growing amount of dynamic graph data demands efficient techniques of incremental graph computation. However, incremental graph algorithms are challenging to develop. Existing approaches usually require users to manually design nontrivial incremental operators, or choose different memoization strategies for certain specific types of computation, limiting the usability and generality. In light of these challenges, we propose <span>\\(\\textsf{Ingress}\\)</span>, an automated system for <i><u>in</u></i><i>cremental</i> <i><u>gr</u></i><i>aph proc</i> <i><u>ess</u></i><i>ing</i>. <span>\\(\\textsf{Ingress}\\)</span> is able to deduce the incremental counterpart of a batch vertex-centric algorithm, without the need of redesigned logic or data structures from users. Underlying <span>\\(\\textsf{Ingress}\\)</span> is an automated incrementalization framework equipped with four different memoization policies, to support all kinds of vertex-centric computations with optimized memory utilization. We identify sufficient conditions for the applicability of these policies. <span>\\(\\textsf{Ingress}\\)</span> chooses the best-fit policy for a given algorithm automatically by verifying these conditions. In addition to the ease-of-use and generalization, <span>\\(\\textsf{Ingress}\\)</span> outperforms state-of-the-art incremental graph systems by <span>\\(12.14\\times \\)</span> on average (up to <span>\\(49.23\\times \\)</span>) in efficiency.\n</p>","PeriodicalId":501532,"journal":{"name":"The VLDB Journal","volume":"50 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-02-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"The VLDB Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00778-024-00838-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
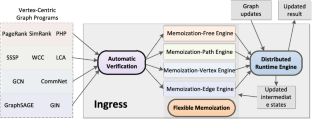
The graph data keep growing over time in real life. The ever-growing amount of dynamic graph data demands efficient techniques of incremental graph computation. However, incremental graph algorithms are challenging to develop. Existing approaches usually require users to manually design nontrivial incremental operators, or choose different memoization strategies for certain specific types of computation, limiting the usability and generality. In light of these challenges, we propose \(\textsf{Ingress}\), an automated system for incrementalgraph processing. \(\textsf{Ingress}\) is able to deduce the incremental counterpart of a batch vertex-centric algorithm, without the need of redesigned logic or data structures from users. Underlying \(\textsf{Ingress}\) is an automated incrementalization framework equipped with four different memoization policies, to support all kinds of vertex-centric computations with optimized memory utilization. We identify sufficient conditions for the applicability of these policies. \(\textsf{Ingress}\) chooses the best-fit policy for a given algorithm automatically by verifying these conditions. In addition to the ease-of-use and generalization, \(\textsf{Ingress}\) outperforms state-of-the-art incremental graph systems by \(12.14\times \) on average (up to \(49.23\times \)) in efficiency.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
