{"title":"Mixture models for simultaneous classification and reduction of three-way data","authors":"Roberto Rocci, Maurizio Vichi, Monia Ranalli","doi":"10.1007/s00180-024-01478-1","DOIUrl":null,"url":null,"abstract":"<p>Finite mixture of Gaussians are often used to classify two- (units and variables) or three- (units, variables and occasions) way data. However, two issues arise: model complexity and capturing the true cluster structure. Indeed, a large number of variables and/or occasions implies a large number of model parameters; while the existence of noise variables (and/or occasions) could mask the true cluster structure. The approach adopted in the present paper is to reduce the number of model parameters by identifying a sub-space containing the information needed to classify the observations. This should also help in identifying noise variables and/or occasions. The maximum likelihood model estimation is carried out through an EM-like algorithm. The effectiveness of the proposal is assessed through a simulation study and an application to real data.</p>","PeriodicalId":55223,"journal":{"name":"Computational Statistics","volume":"62 1","pages":""},"PeriodicalIF":1.4000,"publicationDate":"2024-05-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Statistics","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1007/s00180-024-01478-1","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"STATISTICS & PROBABILITY","Score":null,"Total":0}
引用次数: 0
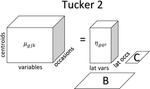
Abstract
Finite mixture of Gaussians are often used to classify two- (units and variables) or three- (units, variables and occasions) way data. However, two issues arise: model complexity and capturing the true cluster structure. Indeed, a large number of variables and/or occasions implies a large number of model parameters; while the existence of noise variables (and/or occasions) could mask the true cluster structure. The approach adopted in the present paper is to reduce the number of model parameters by identifying a sub-space containing the information needed to classify the observations. This should also help in identifying noise variables and/or occasions. The maximum likelihood model estimation is carried out through an EM-like algorithm. The effectiveness of the proposal is assessed through a simulation study and an application to real data.
有限高斯混合物通常用于对双向(单位和变量)或三向(单位、变量和场合)数据进行分类。然而,这就产生了两个问题:模型的复杂性和捕捉真实的聚类结构。事实上,大量的变量和/或场合意味着大量的模型参数;而噪声变量(和/或场合)的存在可能会掩盖真实的聚类结构。本文采用的方法是通过识别包含观测分类所需信息的子空间来减少模型参数的数量。这也有助于识别噪声变量和/或场合。最大似然模型估计是通过类似 EM 的算法进行的。通过模拟研究和对真实数据的应用,对该建议的有效性进行了评估。
期刊介绍:
Computational Statistics (CompStat) is an international journal which promotes the publication of applications and methodological research in the field of Computational Statistics. The focus of papers in CompStat is on the contribution to and influence of computing on statistics and vice versa. The journal provides a forum for computer scientists, mathematicians, and statisticians in a variety of fields of statistics such as biometrics, econometrics, data analysis, graphics, simulation, algorithms, knowledge based systems, and Bayesian computing. CompStat publishes hardware, software plus package reports.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
