{"title":"Face attribute translation with multiple feature perceptual reconstruction assisted by style translator","authors":"Shuqi Zhu, Jiuzhen Liang, Hao Liu","doi":"10.1002/cav.2273","DOIUrl":null,"url":null,"abstract":"<p>Improving the accuracy and disentanglement of attribute translation, and maintaining the consistency of face identity have been hot topics in face attribute translation. Recent approaches employ attention mechanisms to enable attribute translation in facial images. However, due to the lack of accuracy in the extraction of style code, the attention mechanism alone is not precise enough for the translation of attributes. To tackle this, we introduce a style translator module, which partitions the style code into attribute-related and unrelated components, enhancing latent space disentanglement for more accurate attribute manipulation. Additionally, many current methods use per-pixel loss functions to preserve face identity. However, this can sacrifice crucial high-level features and textures in the target image. To address this limitation, we propose a multiple-perceptual reconstruction loss to better maintain image fidelity. Extensive qualitative and quantitative experiments in this article demonstrate significant improvements over state-of-the-art methods, validating the effectiveness of our approach.</p>","PeriodicalId":50645,"journal":{"name":"Computer Animation and Virtual Worlds","volume":"35 3","pages":""},"PeriodicalIF":1.7000,"publicationDate":"2024-05-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computer Animation and Virtual Worlds","FirstCategoryId":"94","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/cav.2273","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
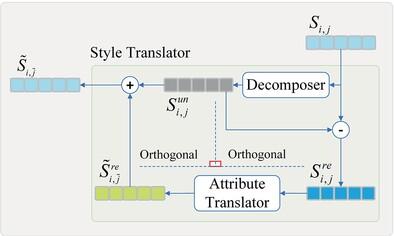
Improving the accuracy and disentanglement of attribute translation, and maintaining the consistency of face identity have been hot topics in face attribute translation. Recent approaches employ attention mechanisms to enable attribute translation in facial images. However, due to the lack of accuracy in the extraction of style code, the attention mechanism alone is not precise enough for the translation of attributes. To tackle this, we introduce a style translator module, which partitions the style code into attribute-related and unrelated components, enhancing latent space disentanglement for more accurate attribute manipulation. Additionally, many current methods use per-pixel loss functions to preserve face identity. However, this can sacrifice crucial high-level features and textures in the target image. To address this limitation, we propose a multiple-perceptual reconstruction loss to better maintain image fidelity. Extensive qualitative and quantitative experiments in this article demonstrate significant improvements over state-of-the-art methods, validating the effectiveness of our approach.
期刊介绍:
With the advent of very powerful PCs and high-end graphics cards, there has been an incredible development in Virtual Worlds, real-time computer animation and simulation, games. But at the same time, new and cheaper Virtual Reality devices have appeared allowing an interaction with these real-time Virtual Worlds and even with real worlds through Augmented Reality. Three-dimensional characters, especially Virtual Humans are now of an exceptional quality, which allows to use them in the movie industry. But this is only a beginning, as with the development of Artificial Intelligence and Agent technology, these characters will become more and more autonomous and even intelligent. They will inhabit the Virtual Worlds in a Virtual Life together with animals and plants.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
