Alon Hafri, Michael F Bonner, Barbara Landau, Chaz Firestone
{"title":"A Phone in a Basket Looks Like a Knife in a Cup: Role-Filler Independence in Visual Processing.","authors":"Alon Hafri, Michael F Bonner, Barbara Landau, Chaz Firestone","doi":"10.1162/opmi_a_00146","DOIUrl":null,"url":null,"abstract":"<p><p>When a piece of fruit is in a bowl, and the bowl is on a table, we appreciate not only the individual objects and their features, but also the relations <i>containment</i> and <i>support</i>, which abstract away from the particular objects involved. Independent representation of roles (e.g., containers vs. supporters) and \"fillers\" of those roles (e.g., bowls vs. cups, tables vs. chairs) is a core principle of language and higher-level reasoning. But does such role-filler independence also arise in automatic visual processing? Here, we show that it does, by exploring a surprising error that such independence can produce. In four experiments, participants saw a stream of images containing different objects arranged in force-dynamic relations-e.g., a phone contained in a basket, a marker resting on a garbage can, or a knife sitting in a cup. Participants had to respond to a single target image (e.g., a phone in a basket) within a stream of distractors presented under time constraints. Surprisingly, even though participants completed this task quickly and accurately, they false-alarmed more often to images matching the target's relational category than to those that did not-even when those images involved completely different objects. In other words, participants searching for a phone in a basket were more likely to mistakenly respond to a knife in a cup than to a marker on a garbage can. Follow-up experiments ruled out strategic responses and also controlled for various confounding image features. We suggest that visual processing represents relations abstractly, in ways that separate roles from fillers.</p>","PeriodicalId":32558,"journal":{"name":"Open Mind","volume":"8 ","pages":"766-794"},"PeriodicalIF":0.0000,"publicationDate":"2024-06-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11219067/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Open Mind","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1162/opmi_a_00146","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"Social Sciences","Score":null,"Total":0}
引用次数: 0
Abstract
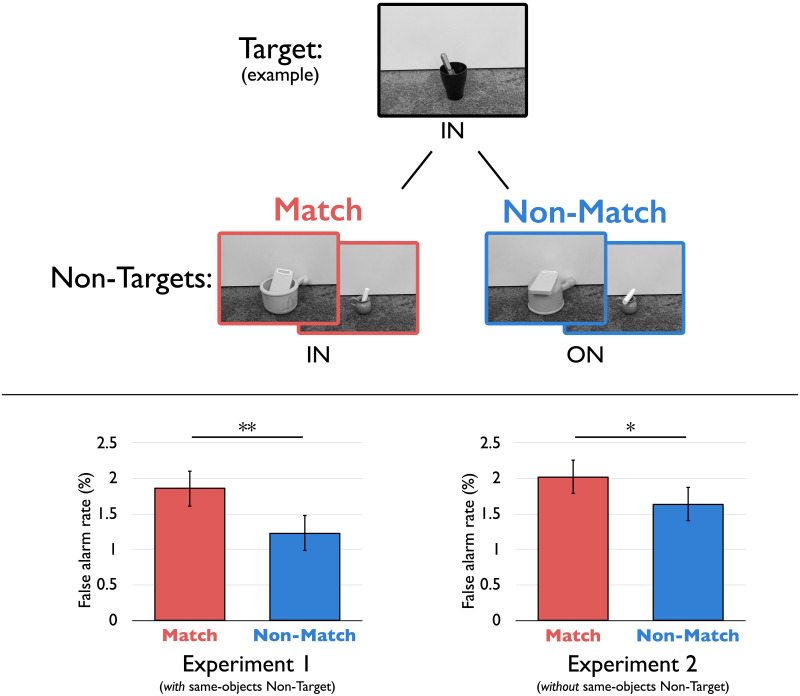
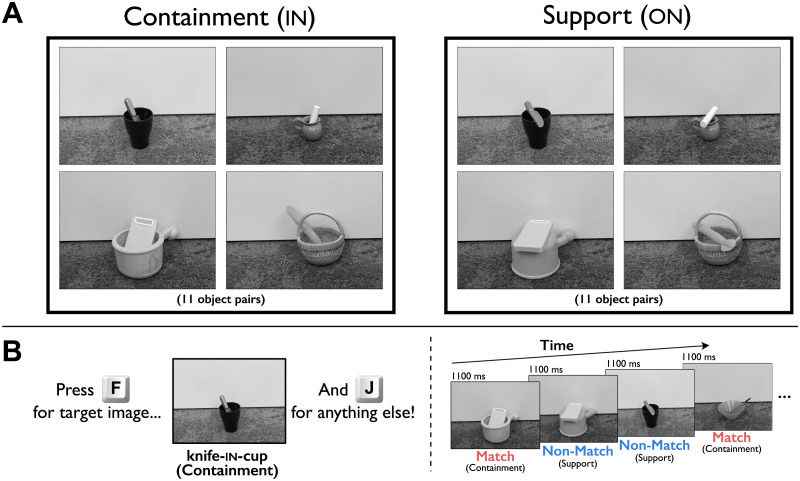
When a piece of fruit is in a bowl, and the bowl is on a table, we appreciate not only the individual objects and their features, but also the relations containment and support, which abstract away from the particular objects involved. Independent representation of roles (e.g., containers vs. supporters) and "fillers" of those roles (e.g., bowls vs. cups, tables vs. chairs) is a core principle of language and higher-level reasoning. But does such role-filler independence also arise in automatic visual processing? Here, we show that it does, by exploring a surprising error that such independence can produce. In four experiments, participants saw a stream of images containing different objects arranged in force-dynamic relations-e.g., a phone contained in a basket, a marker resting on a garbage can, or a knife sitting in a cup. Participants had to respond to a single target image (e.g., a phone in a basket) within a stream of distractors presented under time constraints. Surprisingly, even though participants completed this task quickly and accurately, they false-alarmed more often to images matching the target's relational category than to those that did not-even when those images involved completely different objects. In other words, participants searching for a phone in a basket were more likely to mistakenly respond to a knife in a cup than to a marker on a garbage can. Follow-up experiments ruled out strategic responses and also controlled for various confounding image features. We suggest that visual processing represents relations abstractly, in ways that separate roles from fillers.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
