{"title":"Lifelike agility and play in quadrupedal robots using reinforcement learning and generative pre-trained models","authors":"Lei Han, Qingxu Zhu, Jiapeng Sheng, Chong Zhang, Tingguang Li, Yizheng Zhang, He Zhang, Yuzhen Liu, Cheng Zhou, Rui Zhao, Jie Li, Yufeng Zhang, Rui Wang, Wanchao Chi, Xiong Li, Yonghui Zhu, Lingzhu Xiang, Xiao Teng, Zhengyou Zhang","doi":"10.1038/s42256-024-00861-3","DOIUrl":null,"url":null,"abstract":"Knowledge from animals and humans inspires robotic innovations. Numerous efforts have been made to achieve agile locomotion in quadrupedal robots through classical controllers or reinforcement learning approaches. These methods usually rely on physical models or handcrafted rewards to accurately describe the specific system, rather than on a generalized understanding like animals do. Here we propose a hierarchical framework to construct primitive-, environmental- and strategic-level knowledge that are all pre-trainable, reusable and enrichable for legged robots. The primitive module summarizes knowledge from animal motion data, where, inspired by large pre-trained models in language and image understanding, we introduce deep generative models to produce motor control signals stimulating legged robots to act like real animals. Then, we shape various traversing capabilities at a higher level to align with the environment by reusing the primitive module. Finally, a strategic module is trained focusing on complex downstream tasks by reusing the knowledge from previous levels. We apply the trained hierarchical controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles and play in a designed challenging multi-agent chase tag game, where lifelike agility and strategy emerge in the robots. A key challenge in robotics is leveraging pre-training as a form of knowledge to generate movements. The authors propose a general learning framework for reusing pre-trained knowledge across different perception and task levels. The deployed robots exhibit lifelike agility and sophisticated game-playing strategies.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"6 7","pages":"787-798"},"PeriodicalIF":23.9000,"publicationDate":"2024-07-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-024-00861-3","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
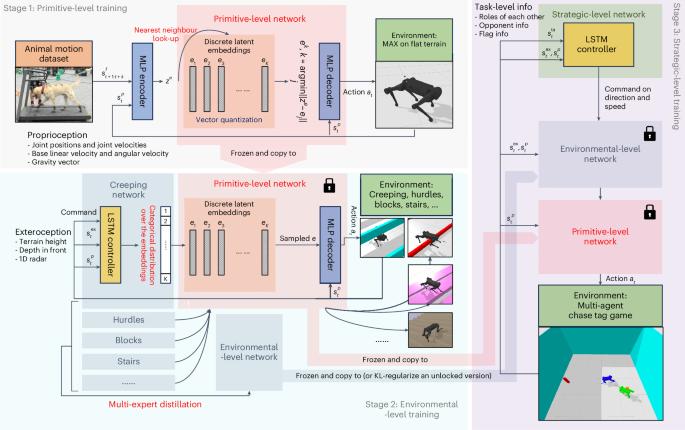
Knowledge from animals and humans inspires robotic innovations. Numerous efforts have been made to achieve agile locomotion in quadrupedal robots through classical controllers or reinforcement learning approaches. These methods usually rely on physical models or handcrafted rewards to accurately describe the specific system, rather than on a generalized understanding like animals do. Here we propose a hierarchical framework to construct primitive-, environmental- and strategic-level knowledge that are all pre-trainable, reusable and enrichable for legged robots. The primitive module summarizes knowledge from animal motion data, where, inspired by large pre-trained models in language and image understanding, we introduce deep generative models to produce motor control signals stimulating legged robots to act like real animals. Then, we shape various traversing capabilities at a higher level to align with the environment by reusing the primitive module. Finally, a strategic module is trained focusing on complex downstream tasks by reusing the knowledge from previous levels. We apply the trained hierarchical controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles and play in a designed challenging multi-agent chase tag game, where lifelike agility and strategy emerge in the robots. A key challenge in robotics is leveraging pre-training as a form of knowledge to generate movements. The authors propose a general learning framework for reusing pre-trained knowledge across different perception and task levels. The deployed robots exhibit lifelike agility and sophisticated game-playing strategies.
来自动物和人类的知识激发了机器人的创新。为了通过经典控制器或强化学习方法实现四足机器人的敏捷运动,人们做出了许多努力。这些方法通常依赖物理模型或手工制作的奖励来准确描述特定系统,而不是像动物那样依赖广义的理解。在这里,我们提出了一个分层框架,用于构建原始、环境和策略层面的知识,这些知识都是可预先训练、可重复使用和可丰富的,适用于有腿机器人。原始模块总结了来自动物运动数据的知识,受语言和图像理解方面的大型预训练模型的启发,我们引入了深度生成模型,以产生运动控制信号,刺激有腿机器人像真实动物一样行动。然后,我们在更高层次上塑造各种穿越能力,通过重复使用原始模块与环境保持一致。最后,通过重复使用前几级的知识,训练出一个战略模块,专注于复杂的下游任务。我们将训练好的分层控制器应用于 MAX 机器人(一种自主开发的四足机器人),让它模仿动物,穿越复杂的障碍物,并参与设计好的具有挑战性的多代理追逐游戏,在游戏中,机器人表现出栩栩如生的敏捷性和策略性。
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
