{"title":"On the Mathematical Relationship Between Contextual Probability and N400 Amplitude.","authors":"James A Michaelov, Benjamin K Bergen","doi":"10.1162/opmi_a_00150","DOIUrl":null,"url":null,"abstract":"<p><p>Accounts of human language comprehension propose different mathematical relationships between the contextual probability of a word and how difficult it is to process, including linear, logarithmic, and super-logarithmic ones. However, the empirical evidence favoring any of these over the others is mixed, appearing to vary depending on the index of processing difficulty used and the approach taken to calculate contextual probability. To help disentangle these results, we focus on the mathematical relationship between corpus-derived contextual probability and the N400, a neural index of processing difficulty. Specifically, we use 37 contemporary transformer language models to calculate the contextual probability of stimuli from 6 experimental studies of the N400, and test whether N400 amplitude is best predicted by a linear, logarithmic, super-logarithmic, or sub-logarithmic transformation of the probabilities calculated using these language models, as well as combinations of these transformed metrics. We replicate the finding that on some datasets, a combination of linearly and logarithmically-transformed probability can predict N400 amplitude better than either metric alone. In addition, we find that overall, the best single predictor of N400 amplitude is sub-logarithmically-transformed probability, which for almost all language models and datasets explains all the variance in N400 amplitude otherwise explained by the linear and logarithmic transformations. This is a novel finding that is not predicted by any current theoretical accounts, and thus one that we argue is likely to play an important role in increasing our understanding of how the statistical regularities of language impact language comprehension.</p>","PeriodicalId":32558,"journal":{"name":"Open Mind","volume":"8 ","pages":"859-897"},"PeriodicalIF":0.0000,"publicationDate":"2024-06-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11285424/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Open Mind","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1162/opmi_a_00150","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"Social Sciences","Score":null,"Total":0}
引用次数: 0
Abstract
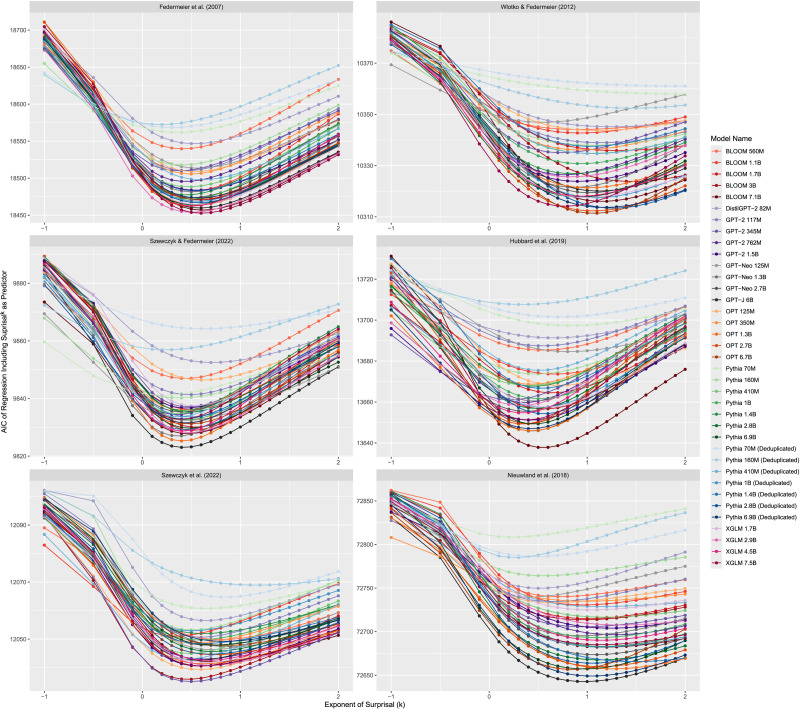
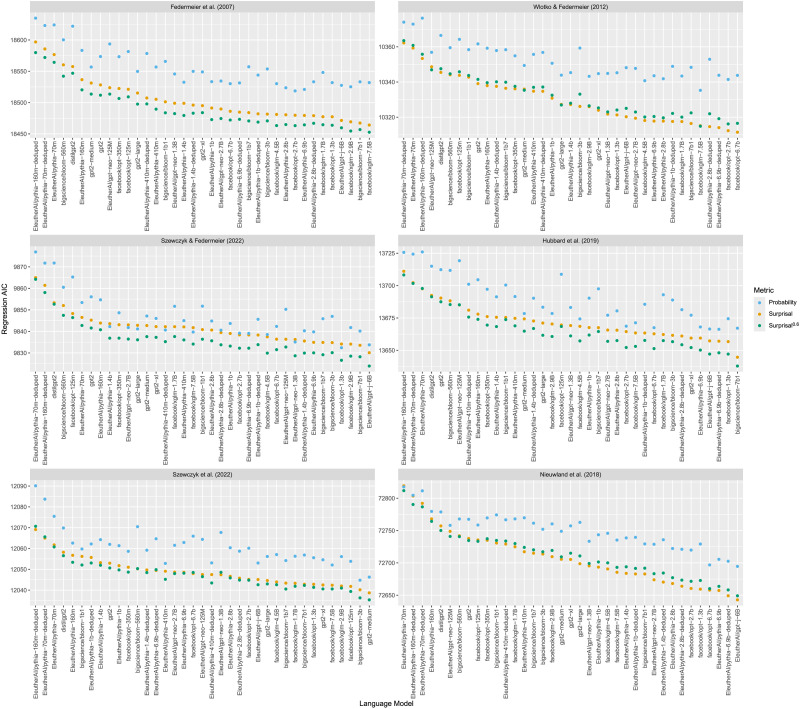
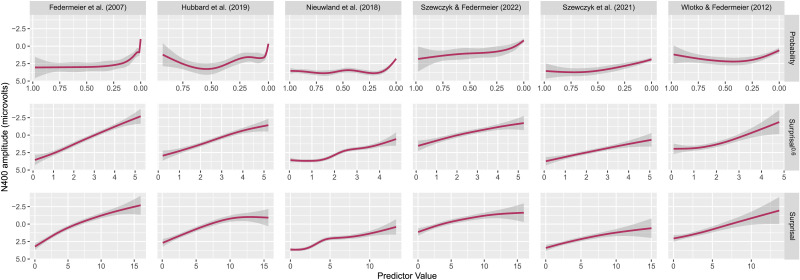
Accounts of human language comprehension propose different mathematical relationships between the contextual probability of a word and how difficult it is to process, including linear, logarithmic, and super-logarithmic ones. However, the empirical evidence favoring any of these over the others is mixed, appearing to vary depending on the index of processing difficulty used and the approach taken to calculate contextual probability. To help disentangle these results, we focus on the mathematical relationship between corpus-derived contextual probability and the N400, a neural index of processing difficulty. Specifically, we use 37 contemporary transformer language models to calculate the contextual probability of stimuli from 6 experimental studies of the N400, and test whether N400 amplitude is best predicted by a linear, logarithmic, super-logarithmic, or sub-logarithmic transformation of the probabilities calculated using these language models, as well as combinations of these transformed metrics. We replicate the finding that on some datasets, a combination of linearly and logarithmically-transformed probability can predict N400 amplitude better than either metric alone. In addition, we find that overall, the best single predictor of N400 amplitude is sub-logarithmically-transformed probability, which for almost all language models and datasets explains all the variance in N400 amplitude otherwise explained by the linear and logarithmic transformations. This is a novel finding that is not predicted by any current theoretical accounts, and thus one that we argue is likely to play an important role in increasing our understanding of how the statistical regularities of language impact language comprehension.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
