Guangtao Zheng, Julia Rymuza, Erfaneh Gharavi, Nathan J LeRoy, Aidong Zhang, Nathan C Sheffield
{"title":"Methods for evaluating unsupervised vector representations of genomic regions.","authors":"Guangtao Zheng, Julia Rymuza, Erfaneh Gharavi, Nathan J LeRoy, Aidong Zhang, Nathan C Sheffield","doi":"10.1093/nargab/lqae086","DOIUrl":null,"url":null,"abstract":"<p><p>Representation learning models have become a mainstay of modern genomics. These models are trained to yield vector representations, or embeddings, of various biological entities, such as cells, genes, individuals, or genomic regions. Recent applications of unsupervised embedding approaches have been shown to learn relationships among genomic regions that define functional elements in a genome. Unsupervised representation learning of genomic regions is free of the supervision from curated metadata and can condense rich biological knowledge from publicly available data to region embeddings. However, there exists no method for evaluating the quality of these embeddings in the absence of metadata, making it difficult to assess the reliability of analyses based on the embeddings, and to tune model training to yield optimal results. To bridge this gap, we propose four evaluation metrics: the cluster tendency score (CTS), the reconstruction score (RCS), the genome distance scaling score (GDSS), and the neighborhood preserving score (NPS). The CTS and RCS statistically quantify how well region embeddings can be clustered and how well the embeddings preserve information in training data. The GDSS and NPS exploit the biological tendency of regions close in genomic space to have similar biological functions; they measure how much such information is captured by individual region embeddings in a set. We demonstrate the utility of these statistical and biological scores for evaluating unsupervised genomic region embeddings and provide guidelines for learning reliable embeddings.</p>","PeriodicalId":33994,"journal":{"name":"NAR Genomics and Bioinformatics","volume":"6 3","pages":"lqae086"},"PeriodicalIF":2.8000,"publicationDate":"2024-08-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11316252/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"NAR Genomics and Bioinformatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/nargab/lqae086","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"GENETICS & HEREDITY","Score":null,"Total":0}
引用次数: 0
Abstract
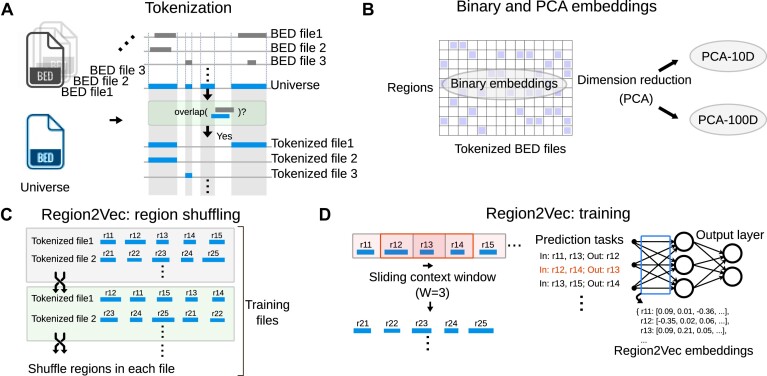
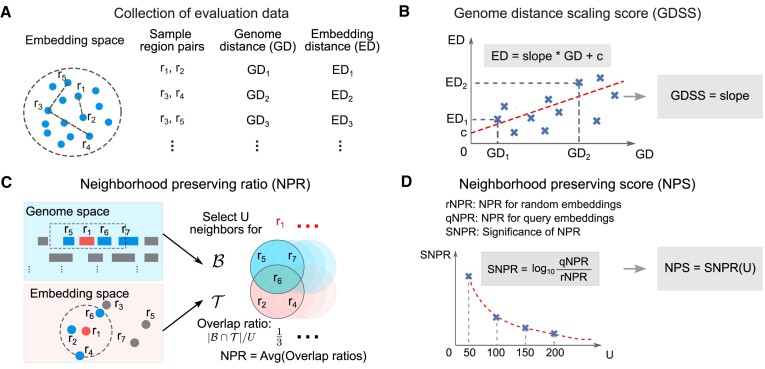
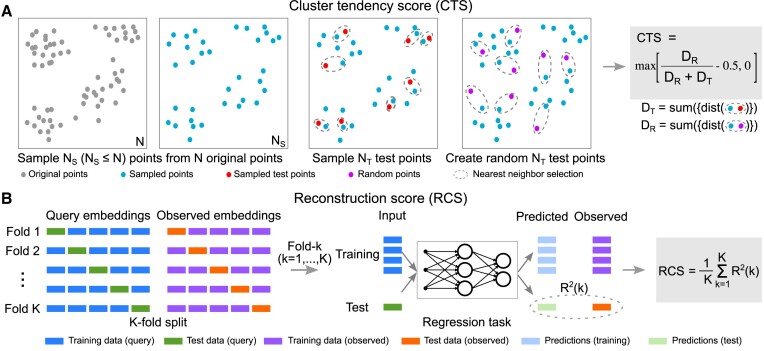
Representation learning models have become a mainstay of modern genomics. These models are trained to yield vector representations, or embeddings, of various biological entities, such as cells, genes, individuals, or genomic regions. Recent applications of unsupervised embedding approaches have been shown to learn relationships among genomic regions that define functional elements in a genome. Unsupervised representation learning of genomic regions is free of the supervision from curated metadata and can condense rich biological knowledge from publicly available data to region embeddings. However, there exists no method for evaluating the quality of these embeddings in the absence of metadata, making it difficult to assess the reliability of analyses based on the embeddings, and to tune model training to yield optimal results. To bridge this gap, we propose four evaluation metrics: the cluster tendency score (CTS), the reconstruction score (RCS), the genome distance scaling score (GDSS), and the neighborhood preserving score (NPS). The CTS and RCS statistically quantify how well region embeddings can be clustered and how well the embeddings preserve information in training data. The GDSS and NPS exploit the biological tendency of regions close in genomic space to have similar biological functions; they measure how much such information is captured by individual region embeddings in a set. We demonstrate the utility of these statistical and biological scores for evaluating unsupervised genomic region embeddings and provide guidelines for learning reliable embeddings.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
