{"title":"Self-supervised learning for fine-grained monocular 3D face reconstruction in the wild","authors":"Dongjin Huang, Yongsheng Shi, Jinhua Liu, Wen Tang","doi":"10.1007/s00530-024-01436-3","DOIUrl":null,"url":null,"abstract":"<p>Reconstructing 3D face from monocular images is a challenging computer vision task, due to the limitations of traditional 3DMM (3D Morphable Model) and the lack of high-fidelity 3D facial scanning data. To solve this issue, we propose a novel coarse-to-fine self-supervised learning framework for reconstructing fine-grained 3D faces from monocular images in the wild. In the coarse stage, face parameters extracted from a single image are used to reconstruct a coarse 3D face through a 3DMM. In the refinement stage, we design a wavelet transform perception model to extract facial details in different frequency domains from an input image. Furthermore, we propose a depth displacement module based on the wavelet transform perception model to generate a refined displacement map from the unwrapped UV textures of the input image and rendered coarse face, which can be used to synthesize detailed 3D face geometry. Moreover, we propose a novel albedo map module based on the wavelet transform perception model to capture high-frequency texture information and generate a detailed albedo map consistent with face illumination. The detailed face geometry and albedo map are used to reconstruct a fine-grained 3D face without any labeled data. We have conducted extensive experiments that demonstrate the superiority of our method over existing state-of-the-art approaches for 3D face reconstruction on four public datasets including CelebA, LS3D, LFW, and NoW benchmark. The experimental results indicate that our method achieved higher accuracy and robustness, particularly of under the challenging conditions such as occlusion, large poses, and varying illuminations.</p>","PeriodicalId":51138,"journal":{"name":"Multimedia Systems","volume":"23 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-08-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Multimedia Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00530-024-01436-3","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
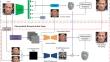
Reconstructing 3D face from monocular images is a challenging computer vision task, due to the limitations of traditional 3DMM (3D Morphable Model) and the lack of high-fidelity 3D facial scanning data. To solve this issue, we propose a novel coarse-to-fine self-supervised learning framework for reconstructing fine-grained 3D faces from monocular images in the wild. In the coarse stage, face parameters extracted from a single image are used to reconstruct a coarse 3D face through a 3DMM. In the refinement stage, we design a wavelet transform perception model to extract facial details in different frequency domains from an input image. Furthermore, we propose a depth displacement module based on the wavelet transform perception model to generate a refined displacement map from the unwrapped UV textures of the input image and rendered coarse face, which can be used to synthesize detailed 3D face geometry. Moreover, we propose a novel albedo map module based on the wavelet transform perception model to capture high-frequency texture information and generate a detailed albedo map consistent with face illumination. The detailed face geometry and albedo map are used to reconstruct a fine-grained 3D face without any labeled data. We have conducted extensive experiments that demonstrate the superiority of our method over existing state-of-the-art approaches for 3D face reconstruction on four public datasets including CelebA, LS3D, LFW, and NoW benchmark. The experimental results indicate that our method achieved higher accuracy and robustness, particularly of under the challenging conditions such as occlusion, large poses, and varying illuminations.
期刊介绍:
This journal details innovative research ideas, emerging technologies, state-of-the-art methods and tools in all aspects of multimedia computing, communication, storage, and applications. It features theoretical, experimental, and survey articles.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
