Run Shao , Zhaoyang Zhang , Chao Tao , Yunsheng Zhang , Chengli Peng , Haifeng Li
{"title":"Homogeneous tokenizer matters: Homogeneous visual tokenizer for remote sensing image understanding","authors":"Run Shao , Zhaoyang Zhang , Chao Tao , Yunsheng Zhang , Chengli Peng , Haifeng Li","doi":"10.1016/j.isprsjprs.2024.09.009","DOIUrl":null,"url":null,"abstract":"<div><p>On the basis of the transformer architecture and the pretext task of “next-token prediction”, multimodal large language models (MLLMs) are revolutionizing the paradigm in the field of remote sensing image understanding. However, the tokenizer, as one of the fundamental components of MLLMs, has long been overlooked or even misunderstood in visual tasks. A key factor contributing to the great comprehension power of large language models is that natural language tokenizers utilize meaningful words or subwords as the basic elements of language. In contrast, mainstream visual tokenizers, represented by patch-based methods such as Patch Embed, rely on meaningless rectangular patches as basic elements of vision. Analogous to words or subwords in language, we define semantically independent regions (SIRs) for vision and then propose two properties that an ideal visual tokenizer should possess: (1) homogeneity, where SIRs serve as the basic elements of vision, and (2) adaptivity, which allows for a flexible number of tokens to accommodate images of any size and tasks of any granularity. On this basis, we design a simple HOmogeneous visual tOKenizer: HOOK. HOOK consists of two modules: an object perception module (OPM) and an object vectorization module (OVM). To achieve homogeneity, the OPM splits the image into 4 × 4 pixel seeds and then uses a self-attention mechanism to identify SIRs. The OVM employs cross-attention to merge seeds within the same SIR. To achieve adaptability, the OVM predefines a variable number of learnable vectors as cross-attention queries, allowing for the adjustment of the token quantity. We conducted experiments on the NWPU-RESISC45, WHU-RS19, and NaSC-TG2 classification datasets for sparse tasks and the GID5 and DGLCC segmentation datasets for dense tasks. The results show that the visual tokens obtained by HOOK correspond to individual objects, thereby verifying their homogeneity. Compared with randomly initialized or pretrained Patch Embed, which required more than one hundred tokens per image, HOOK required only 6 and 8 tokens for sparse and dense tasks, respectively, resulting in performance improvements of 2% to 10% and efficiency improvements of 1.5 to 2.8 times. The homogeneity and adaptability of the proposed approach provide new perspectives for the study of visual tokenizers. Guided by these principles, the developed HOOK has the potential to replace traditional Patch Embed. The code is available at <span><span>https://github.com/GeoX-Lab/Hook</span><svg><path></path></svg></span>.</p></div>","PeriodicalId":50269,"journal":{"name":"ISPRS Journal of Photogrammetry and Remote Sensing","volume":"218 ","pages":"Pages 294-310"},"PeriodicalIF":12.2000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"ISPRS Journal of Photogrammetry and Remote Sensing","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0924271624003472","RegionNum":1,"RegionCategory":"地球科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/9/21 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"GEOGRAPHY, PHYSICAL","Score":null,"Total":0}
引用次数: 0
Abstract
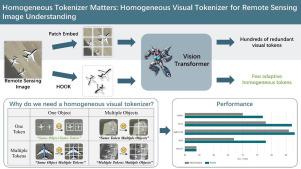
On the basis of the transformer architecture and the pretext task of “next-token prediction”, multimodal large language models (MLLMs) are revolutionizing the paradigm in the field of remote sensing image understanding. However, the tokenizer, as one of the fundamental components of MLLMs, has long been overlooked or even misunderstood in visual tasks. A key factor contributing to the great comprehension power of large language models is that natural language tokenizers utilize meaningful words or subwords as the basic elements of language. In contrast, mainstream visual tokenizers, represented by patch-based methods such as Patch Embed, rely on meaningless rectangular patches as basic elements of vision. Analogous to words or subwords in language, we define semantically independent regions (SIRs) for vision and then propose two properties that an ideal visual tokenizer should possess: (1) homogeneity, where SIRs serve as the basic elements of vision, and (2) adaptivity, which allows for a flexible number of tokens to accommodate images of any size and tasks of any granularity. On this basis, we design a simple HOmogeneous visual tOKenizer: HOOK. HOOK consists of two modules: an object perception module (OPM) and an object vectorization module (OVM). To achieve homogeneity, the OPM splits the image into 4 × 4 pixel seeds and then uses a self-attention mechanism to identify SIRs. The OVM employs cross-attention to merge seeds within the same SIR. To achieve adaptability, the OVM predefines a variable number of learnable vectors as cross-attention queries, allowing for the adjustment of the token quantity. We conducted experiments on the NWPU-RESISC45, WHU-RS19, and NaSC-TG2 classification datasets for sparse tasks and the GID5 and DGLCC segmentation datasets for dense tasks. The results show that the visual tokens obtained by HOOK correspond to individual objects, thereby verifying their homogeneity. Compared with randomly initialized or pretrained Patch Embed, which required more than one hundred tokens per image, HOOK required only 6 and 8 tokens for sparse and dense tasks, respectively, resulting in performance improvements of 2% to 10% and efficiency improvements of 1.5 to 2.8 times. The homogeneity and adaptability of the proposed approach provide new perspectives for the study of visual tokenizers. Guided by these principles, the developed HOOK has the potential to replace traditional Patch Embed. The code is available at https://github.com/GeoX-Lab/Hook.
期刊介绍:
The ISPRS Journal of Photogrammetry and Remote Sensing (P&RS) serves as the official journal of the International Society for Photogrammetry and Remote Sensing (ISPRS). It acts as a platform for scientists and professionals worldwide who are involved in various disciplines that utilize photogrammetry, remote sensing, spatial information systems, computer vision, and related fields. The journal aims to facilitate communication and dissemination of advancements in these disciplines, while also acting as a comprehensive source of reference and archive.
P&RS endeavors to publish high-quality, peer-reviewed research papers that are preferably original and have not been published before. These papers can cover scientific/research, technological development, or application/practical aspects. Additionally, the journal welcomes papers that are based on presentations from ISPRS meetings, as long as they are considered significant contributions to the aforementioned fields.
In particular, P&RS encourages the submission of papers that are of broad scientific interest, showcase innovative applications (especially in emerging fields), have an interdisciplinary focus, discuss topics that have received limited attention in P&RS or related journals, or explore new directions in scientific or professional realms. It is preferred that theoretical papers include practical applications, while papers focusing on systems and applications should include a theoretical background.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
