{"title":"An efficient cross-view image fusion method based on selected state space and hashing for promoting urban perception","authors":"Peng Han , Chao Chen","doi":"10.1016/j.inffus.2024.102737","DOIUrl":null,"url":null,"abstract":"<div><div>In the field of cross-view image geolocation, traditional convolutional neural network (CNN)-based learning models generate unsatisfactory fusion performance due to their inability to model global correlations. The Transformer-based fusion methods can well compensate for the above problems, however, the Transformer has quadratic computational complexity and huge GPU memory consumption. The recent Mamba model based on the selection state space has a strong ability to model long sequences, lower GPU memory occupancy, and fewer GFLOPs. It is thus attractive and worth studying to apply Mamba to the cross-view image geolocation task. In addition, in the image-matching process (i.e., fusion of satellite/aerial and street view data.), we found that the storage occupancy of similarity measures based on floating-point features is high. Efficiently converting floating-point features into hash codes is a possible solution. In this study, we propose a cross-view image geolocation method (S6HG) based purely on Vision Mamba and hashing. S6HG fully utilizes the advantages of Vision Mamba in global information modeling and explicit location information encoding and the low storage occupancy of hash codes. Our method consists of two stages. In the first stage, we use a Siamese network based purely on vision Mamba to embed features for street view images and satellite images respectively. Our first-stage model is called S6G. In the second stage, we construct a cross-view autoencoder to further refine and compress the embedded features, and then simply map the refined features to hash codes. Comprehensive experiments show that S6G has achieved superior results on the CVACT dataset and comparable results to the most advanced methods on the CVUSA dataset. It is worth noting that other floating-point feature-based methods (4096-dimension) are 170.59 times faster than S6HG (768-bit) in storing 90,618 retrieval gallery data. Furthermore, the inference efficiency of S6G is higher than ViT-based computational methods.</div></div>","PeriodicalId":50367,"journal":{"name":"Information Fusion","volume":"115 ","pages":"Article 102737"},"PeriodicalIF":15.5000,"publicationDate":"2024-10-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Information Fusion","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1566253524005153","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
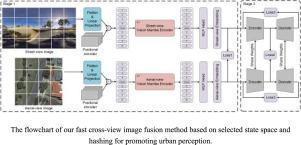
Abstract
In the field of cross-view image geolocation, traditional convolutional neural network (CNN)-based learning models generate unsatisfactory fusion performance due to their inability to model global correlations. The Transformer-based fusion methods can well compensate for the above problems, however, the Transformer has quadratic computational complexity and huge GPU memory consumption. The recent Mamba model based on the selection state space has a strong ability to model long sequences, lower GPU memory occupancy, and fewer GFLOPs. It is thus attractive and worth studying to apply Mamba to the cross-view image geolocation task. In addition, in the image-matching process (i.e., fusion of satellite/aerial and street view data.), we found that the storage occupancy of similarity measures based on floating-point features is high. Efficiently converting floating-point features into hash codes is a possible solution. In this study, we propose a cross-view image geolocation method (S6HG) based purely on Vision Mamba and hashing. S6HG fully utilizes the advantages of Vision Mamba in global information modeling and explicit location information encoding and the low storage occupancy of hash codes. Our method consists of two stages. In the first stage, we use a Siamese network based purely on vision Mamba to embed features for street view images and satellite images respectively. Our first-stage model is called S6G. In the second stage, we construct a cross-view autoencoder to further refine and compress the embedded features, and then simply map the refined features to hash codes. Comprehensive experiments show that S6G has achieved superior results on the CVACT dataset and comparable results to the most advanced methods on the CVUSA dataset. It is worth noting that other floating-point feature-based methods (4096-dimension) are 170.59 times faster than S6HG (768-bit) in storing 90,618 retrieval gallery data. Furthermore, the inference efficiency of S6G is higher than ViT-based computational methods.
期刊介绍:
Information Fusion serves as a central platform for showcasing advancements in multi-sensor, multi-source, multi-process information fusion, fostering collaboration among diverse disciplines driving its progress. It is the leading outlet for sharing research and development in this field, focusing on architectures, algorithms, and applications. Papers dealing with fundamental theoretical analyses as well as those demonstrating their application to real-world problems will be welcome.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
