Ruizhe Chen , Chunyan Li , Longyue Wang , Mingquan Liu , Shugao Chen , Jiahao Yang , Xiangxiang Zeng
{"title":"Pretraining graph transformer for molecular representation with fusion of multimodal information","authors":"Ruizhe Chen , Chunyan Li , Longyue Wang , Mingquan Liu , Shugao Chen , Jiahao Yang , Xiangxiang Zeng","doi":"10.1016/j.inffus.2024.102784","DOIUrl":null,"url":null,"abstract":"<div><div>Molecular representation learning (MRL) is essential in certain applications including drug discovery and life science. Despite advancements in multiview and multimodal learning in MRL, existing models have explored only a limited range of perspectives, and the fusion of different views and modalities in MRL remains underexplored. Besides, obtaining the geometric conformer of molecules is not feasible in many tasks due to the high computational cost. Designing a general-purpose pertaining model for MRL is worthwhile yet challenging. This paper proposes a novel graph Transformer pretraining framework with fusion of node and graph views, along with the 2D topology and 3D geometry modalities of molecules, called MolGT. This MolGT model integrates node-level and graph-level pretext tasks on 2D topology and 3D geometry, leveraging a customized modality-shared graph Transformer that has versatility regarding parameter efficiency and knowledge sharing across modalities. Moreover, MolGT can produce implicit 3D geometry by leveraging contrastive learning between 2D topological and 3D geometric modalities. We provide extensive experiments and in-depth analyses, verifying that MolGT can (1) indeed leverage multiview and multimodal information to represent molecules accurately, and (2) infer nearly identical results using 2D molecules without requiring the expensive computation of generating conformers. Code is available on GitHub<span><span><sup>1</sup></span></span>.</div></div>","PeriodicalId":50367,"journal":{"name":"Information Fusion","volume":"115 ","pages":"Article 102784"},"PeriodicalIF":15.5000,"publicationDate":"2025-03-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Information Fusion","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1566253524005621","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/11/14 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
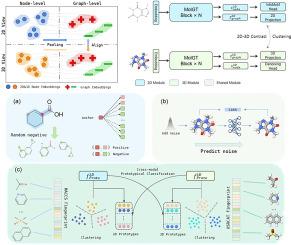
Molecular representation learning (MRL) is essential in certain applications including drug discovery and life science. Despite advancements in multiview and multimodal learning in MRL, existing models have explored only a limited range of perspectives, and the fusion of different views and modalities in MRL remains underexplored. Besides, obtaining the geometric conformer of molecules is not feasible in many tasks due to the high computational cost. Designing a general-purpose pertaining model for MRL is worthwhile yet challenging. This paper proposes a novel graph Transformer pretraining framework with fusion of node and graph views, along with the 2D topology and 3D geometry modalities of molecules, called MolGT. This MolGT model integrates node-level and graph-level pretext tasks on 2D topology and 3D geometry, leveraging a customized modality-shared graph Transformer that has versatility regarding parameter efficiency and knowledge sharing across modalities. Moreover, MolGT can produce implicit 3D geometry by leveraging contrastive learning between 2D topological and 3D geometric modalities. We provide extensive experiments and in-depth analyses, verifying that MolGT can (1) indeed leverage multiview and multimodal information to represent molecules accurately, and (2) infer nearly identical results using 2D molecules without requiring the expensive computation of generating conformers. Code is available on GitHub1.
期刊介绍:
Information Fusion serves as a central platform for showcasing advancements in multi-sensor, multi-source, multi-process information fusion, fostering collaboration among diverse disciplines driving its progress. It is the leading outlet for sharing research and development in this field, focusing on architectures, algorithms, and applications. Papers dealing with fundamental theoretical analyses as well as those demonstrating their application to real-world problems will be welcome.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
