Eyal Klang, Donald Apakama, Ethan E. Abbott, Akhil Vaid, Joshua Lampert, Ankit Sakhuja, Robert Freeman, Alexander W. Charney, David Reich, Monica Kraft, Girish N. Nadkarni, Benjamin S. Glicksberg
{"title":"A strategy for cost-effective large language model use at health system-scale","authors":"Eyal Klang, Donald Apakama, Ethan E. Abbott, Akhil Vaid, Joshua Lampert, Ankit Sakhuja, Robert Freeman, Alexander W. Charney, David Reich, Monica Kraft, Girish N. Nadkarni, Benjamin S. Glicksberg","doi":"10.1038/s41746-024-01315-1","DOIUrl":null,"url":null,"abstract":"Large language models (LLMs) can optimize clinical workflows; however, the economic and computational challenges of their utilization at the health system scale are underexplored. We evaluated how concatenating queries with multiple clinical notes and tasks simultaneously affects model performance under increasing computational loads. We assessed ten LLMs of different capacities and sizes utilizing real-world patient data. We conducted >300,000 experiments of various task sizes and configurations, measuring accuracy in question-answering and the ability to properly format outputs. Performance deteriorated as the number of questions and notes increased. High-capacity models, like Llama-3–70b, had low failure rates and high accuracies. GPT-4-turbo-128k was similarly resilient across task burdens, but performance deteriorated after 50 tasks at large prompt sizes. After addressing mitigable failures, these two models can concatenate up to 50 simultaneous tasks effectively, with validation on a public medical question-answering dataset. An economic analysis demonstrated up to a 17-fold cost reduction at 50 tasks using concatenation. These results identify the limits of LLMs for effective utilization and highlight avenues for cost-efficiency at the enterprise scale.","PeriodicalId":19349,"journal":{"name":"NPJ Digital Medicine","volume":" ","pages":"1-12"},"PeriodicalIF":18.0000,"publicationDate":"2024-11-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s41746-024-01315-1.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"NPJ Digital Medicine","FirstCategoryId":"3","ListUrlMain":"https://www.nature.com/articles/s41746-024-01315-1","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
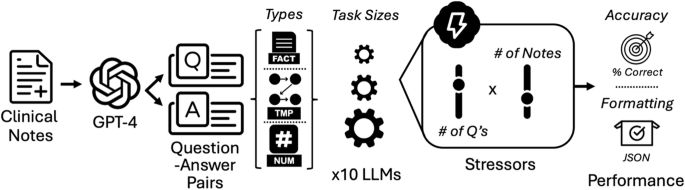
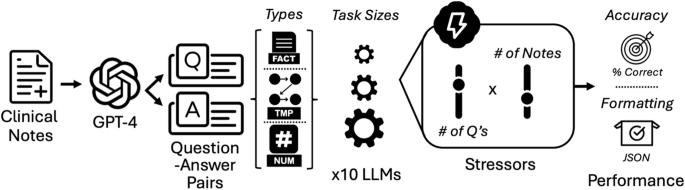
Large language models (LLMs) can optimize clinical workflows; however, the economic and computational challenges of their utilization at the health system scale are underexplored. We evaluated how concatenating queries with multiple clinical notes and tasks simultaneously affects model performance under increasing computational loads. We assessed ten LLMs of different capacities and sizes utilizing real-world patient data. We conducted >300,000 experiments of various task sizes and configurations, measuring accuracy in question-answering and the ability to properly format outputs. Performance deteriorated as the number of questions and notes increased. High-capacity models, like Llama-3–70b, had low failure rates and high accuracies. GPT-4-turbo-128k was similarly resilient across task burdens, but performance deteriorated after 50 tasks at large prompt sizes. After addressing mitigable failures, these two models can concatenate up to 50 simultaneous tasks effectively, with validation on a public medical question-answering dataset. An economic analysis demonstrated up to a 17-fold cost reduction at 50 tasks using concatenation. These results identify the limits of LLMs for effective utilization and highlight avenues for cost-efficiency at the enterprise scale.
期刊介绍:
npj Digital Medicine is an online open-access journal that focuses on publishing peer-reviewed research in the field of digital medicine. The journal covers various aspects of digital medicine, including the application and implementation of digital and mobile technologies in clinical settings, virtual healthcare, and the use of artificial intelligence and informatics.
The primary goal of the journal is to support innovation and the advancement of healthcare through the integration of new digital and mobile technologies. When determining if a manuscript is suitable for publication, the journal considers four important criteria: novelty, clinical relevance, scientific rigor, and digital innovation.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
