{"title":"Flexible Bayesian Product Mixture Models for Vector Autoregressions.","authors":"Suprateek Kundu, Joshua Lukemire","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Bayesian non-parametric methods based on Dirichlet process mixtures have seen tremendous success in various domains and are appealing in being able to borrow information by clustering samples that share identical parameters. However, such methods can face hurdles in heterogeneous settings where objects are expected to cluster only along a subset of axes or where clusters of samples share only a subset of identical parameters. We overcome such limitations by developing a novel class of product of Dirichlet process location-scale mixtures that enables independent clustering at multiple scales, which results in varying levels of information sharing across samples. First, we develop the approach for independent multivariate data. Subsequently we generalize it to multivariate time-series data under the framework of multi-subject Vector Autoregressive (VAR) models that is our primary focus, which go beyond parametric single-subject VAR models. We establish posterior consistency and develop efficient posterior computation for implementation. Extensive numerical studies involving VAR models show distinct advantages over competing methods in terms of estimation, clustering, and feature selection accuracy. Our resting state fMRI analysis from the Human Connectome Project reveals biologically interpretable connectivity differences between distinct intelligence groups, while another air pollution application illustrates the superior forecasting accuracy compared to alternate methods.</p>","PeriodicalId":50161,"journal":{"name":"Journal of Machine Learning Research","volume":"25 ","pages":""},"PeriodicalIF":5.2000,"publicationDate":"2024-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11646655/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Machine Learning Research","FirstCategoryId":"94","ListUrlMain":"","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
引用次数: 0
Abstract
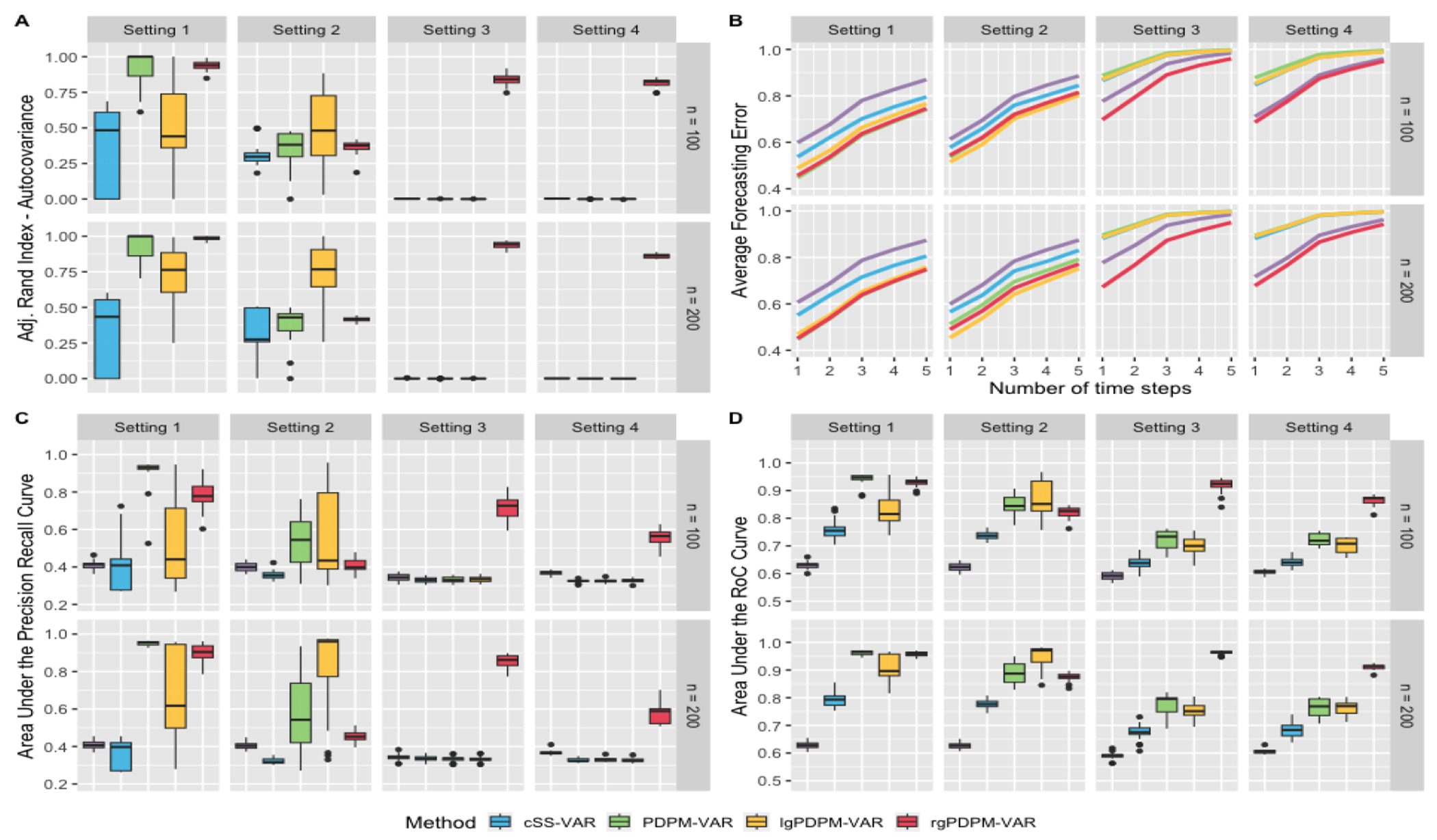
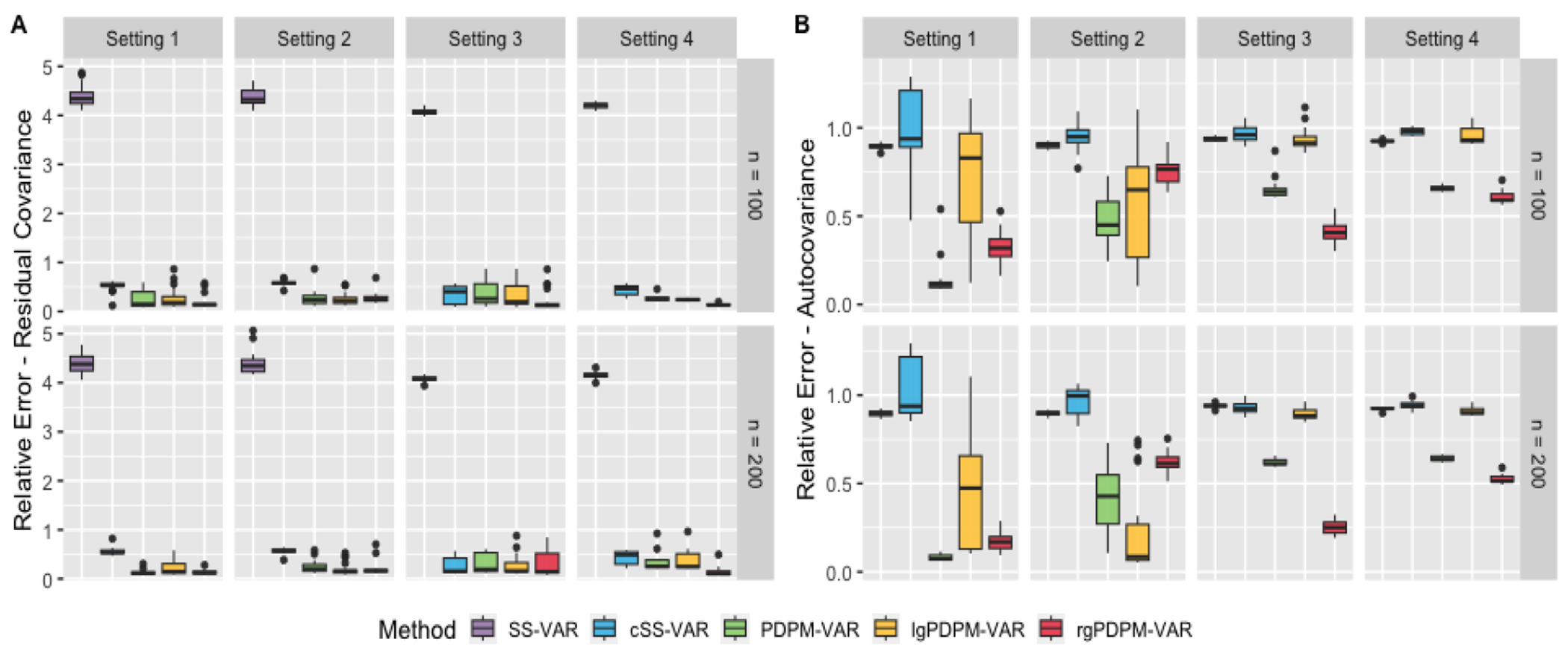
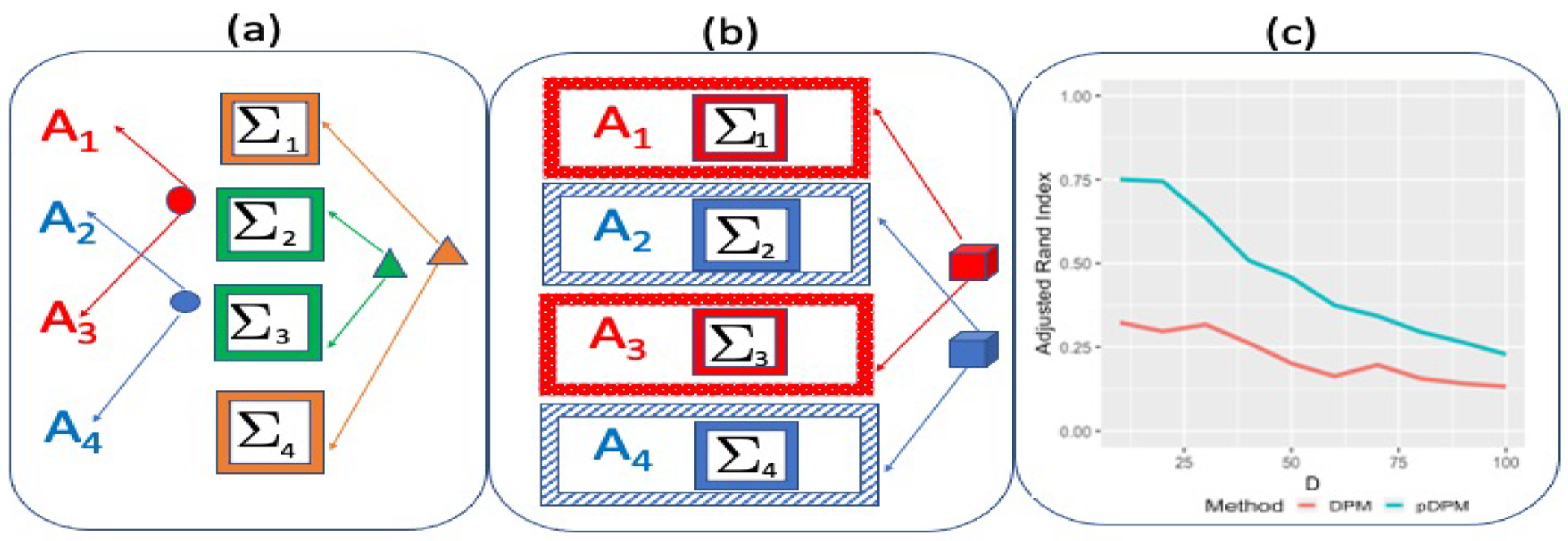
Bayesian non-parametric methods based on Dirichlet process mixtures have seen tremendous success in various domains and are appealing in being able to borrow information by clustering samples that share identical parameters. However, such methods can face hurdles in heterogeneous settings where objects are expected to cluster only along a subset of axes or where clusters of samples share only a subset of identical parameters. We overcome such limitations by developing a novel class of product of Dirichlet process location-scale mixtures that enables independent clustering at multiple scales, which results in varying levels of information sharing across samples. First, we develop the approach for independent multivariate data. Subsequently we generalize it to multivariate time-series data under the framework of multi-subject Vector Autoregressive (VAR) models that is our primary focus, which go beyond parametric single-subject VAR models. We establish posterior consistency and develop efficient posterior computation for implementation. Extensive numerical studies involving VAR models show distinct advantages over competing methods in terms of estimation, clustering, and feature selection accuracy. Our resting state fMRI analysis from the Human Connectome Project reveals biologically interpretable connectivity differences between distinct intelligence groups, while another air pollution application illustrates the superior forecasting accuracy compared to alternate methods.
期刊介绍:
The Journal of Machine Learning Research (JMLR) provides an international forum for the electronic and paper publication of high-quality scholarly articles in all areas of machine learning. All published papers are freely available online.
JMLR has a commitment to rigorous yet rapid reviewing.
JMLR seeks previously unpublished papers on machine learning that contain:
new principled algorithms with sound empirical validation, and with justification of theoretical, psychological, or biological nature;
experimental and/or theoretical studies yielding new insight into the design and behavior of learning in intelligent systems;
accounts of applications of existing techniques that shed light on the strengths and weaknesses of the methods;
formalization of new learning tasks (e.g., in the context of new applications) and of methods for assessing performance on those tasks;
development of new analytical frameworks that advance theoretical studies of practical learning methods;
computational models of data from natural learning systems at the behavioral or neural level; or extremely well-written surveys of existing work.
 分享
分享



 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
