Xiao Xiao, Shuqin Wang, Feng Jiang, Tingyue Qi, Wei Wang
{"title":"Alleviating the medical strain: a triage method via cross-domain text classification.","authors":"Xiao Xiao, Shuqin Wang, Feng Jiang, Tingyue Qi, Wei Wang","doi":"10.3389/fncom.2024.1468519","DOIUrl":null,"url":null,"abstract":"<p><p>It is a universal phenomenon for patients who do not know which clinical department to register in large general hospitals. Although triage nurses can help patients, due to the larger number of patients, they have to stand in a queue for minutes to consult. Recently, there have already been some efforts to devote deep-learning techniques or pre-trained language models (PLMs) to triage recommendations. However, these methods may suffer two main limitations: (1) These methods typically require a certain amount of labeled or unlabeled data for model training, which are not always accessible and costly to acquire. (2) These methods have not taken into account the distortion of semantic feature structure and the loss of category discriminability in the model training. To overcome these limitations, in this study, we propose a cross-domain text classification method based on prompt-tuning, which can classify patients' questions or texts about their symptoms into several given categories to give suggestions on which kind of consulting room patients could choose. Specifically, first, different prompt templates are manually crafted based on various data contents, embedding source domain information into the prompt templates to generate another text with similar semantic feature structures for performing classification tasks. Then, five different strategies are employed to expand the label word space for modifying prompts, and the integration of these strategies is used as the final verbalizer. The extensive experiments on Chinese Triage datasets demonstrate that our method achieved state-of-the-art performance.</p>","PeriodicalId":12363,"journal":{"name":"Frontiers in Computational Neuroscience","volume":"18 ","pages":"1468519"},"PeriodicalIF":2.3000,"publicationDate":"2024-12-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11688176/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Frontiers in Computational Neuroscience","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3389/fncom.2024.1468519","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q2","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
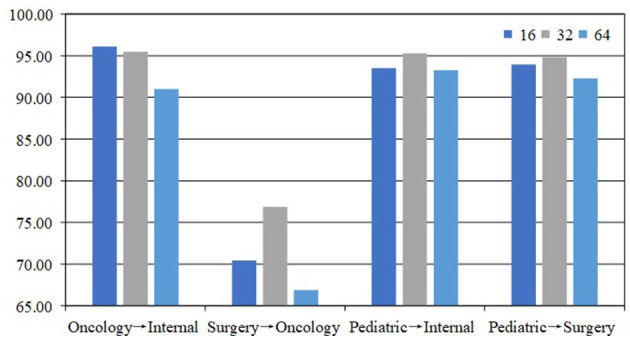
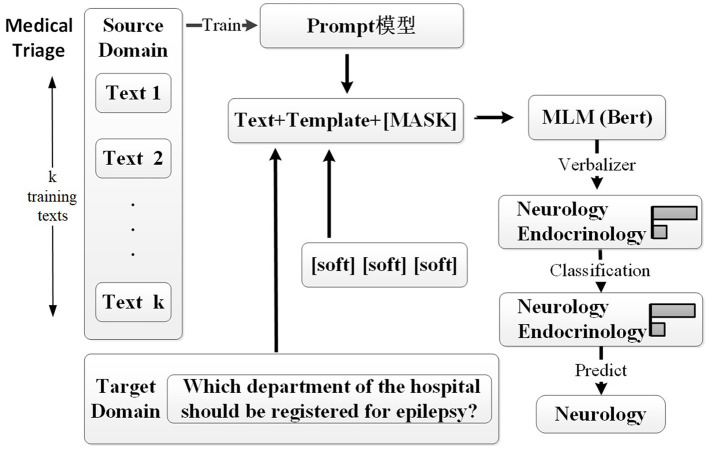
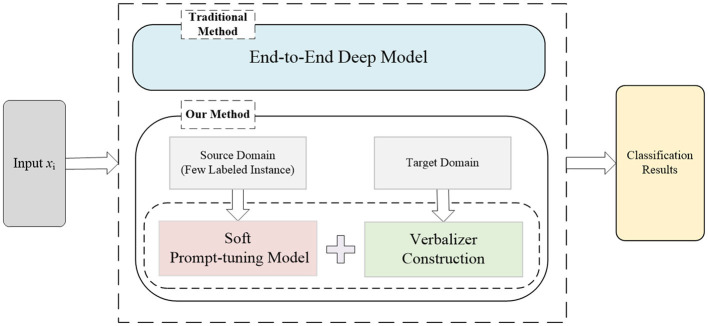
It is a universal phenomenon for patients who do not know which clinical department to register in large general hospitals. Although triage nurses can help patients, due to the larger number of patients, they have to stand in a queue for minutes to consult. Recently, there have already been some efforts to devote deep-learning techniques or pre-trained language models (PLMs) to triage recommendations. However, these methods may suffer two main limitations: (1) These methods typically require a certain amount of labeled or unlabeled data for model training, which are not always accessible and costly to acquire. (2) These methods have not taken into account the distortion of semantic feature structure and the loss of category discriminability in the model training. To overcome these limitations, in this study, we propose a cross-domain text classification method based on prompt-tuning, which can classify patients' questions or texts about their symptoms into several given categories to give suggestions on which kind of consulting room patients could choose. Specifically, first, different prompt templates are manually crafted based on various data contents, embedding source domain information into the prompt templates to generate another text with similar semantic feature structures for performing classification tasks. Then, five different strategies are employed to expand the label word space for modifying prompts, and the integration of these strategies is used as the final verbalizer. The extensive experiments on Chinese Triage datasets demonstrate that our method achieved state-of-the-art performance.
期刊介绍:
Frontiers in Computational Neuroscience is a first-tier electronic journal devoted to promoting theoretical modeling of brain function and fostering interdisciplinary interactions between theoretical and experimental neuroscience. Progress in understanding the amazing capabilities of the brain is still limited, and we believe that it will only come with deep theoretical thinking and mutually stimulating cooperation between different disciplines and approaches. We therefore invite original contributions on a wide range of topics that present the fruits of such cooperation, or provide stimuli for future alliances. We aim to provide an interactive forum for cutting-edge theoretical studies of the nervous system, and for promulgating the best theoretical research to the broader neuroscience community. Models of all styles and at all levels are welcome, from biophysically motivated realistic simulations of neurons and synapses to high-level abstract models of inference and decision making. While the journal is primarily focused on theoretically based and driven research, we welcome experimental studies that validate and test theoretical conclusions.
Also: comp neuro


 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
