Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R. Pfohl, Heather Cole-Lewis, Darlene Neal, Qazi Mamunur Rashid, Mike Schaekermann, Amy Wang, Dev Dash, Jonathan H. Chen, Nigam H. Shah, Sami Lachgar, Philip Andrew Mansfield, Sushant Prakash, Bradley Green, Ewa Dominowska, Blaise Agüera y Arcas, Nenad Tomašev, Yun Liu, Renee Wong, Christopher Semturs, S. Sara Mahdavi, Joelle K. Barral, Dale R. Webster, Greg S. Corrado, Yossi Matias, Shekoofeh Azizi, Alan Karthikesalingam, Vivek Natarajan
{"title":"Toward expert-level medical question answering with large language models","authors":"Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R. Pfohl, Heather Cole-Lewis, Darlene Neal, Qazi Mamunur Rashid, Mike Schaekermann, Amy Wang, Dev Dash, Jonathan H. Chen, Nigam H. Shah, Sami Lachgar, Philip Andrew Mansfield, Sushant Prakash, Bradley Green, Ewa Dominowska, Blaise Agüera y Arcas, Nenad Tomašev, Yun Liu, Renee Wong, Christopher Semturs, S. Sara Mahdavi, Joelle K. Barral, Dale R. Webster, Greg S. Corrado, Yossi Matias, Shekoofeh Azizi, Alan Karthikesalingam, Vivek Natarajan","doi":"10.1038/s41591-024-03423-7","DOIUrl":null,"url":null,"abstract":"Large language models (LLMs) have shown promise in medical question answering, with Med-PaLM being the first to exceed a ‘passing’ score in United States Medical Licensing Examination style questions. However, challenges remain in long-form medical question answering and handling real-world workflows. Here, we present Med-PaLM 2, which bridges these gaps with a combination of base LLM improvements, medical domain fine-tuning and new strategies for improving reasoning and grounding through ensemble refinement and chain of retrieval. Med-PaLM 2 scores up to 86.5% on the MedQA dataset, improving upon Med-PaLM by over 19%, and demonstrates dramatic performance increases across MedMCQA, PubMedQA and MMLU clinical topics datasets. Our detailed human evaluations framework shows that physicians prefer Med-PaLM 2 answers to those from other physicians on eight of nine clinical axes. Med-PaLM 2 also demonstrates significant improvements over its predecessor across all evaluation metrics, particularly on new adversarial datasets designed to probe LLM limitations (P < 0.001). In a pilot study using real-world medical questions, specialists preferred Med-PaLM 2 answers to generalist physician answers 65% of the time. While specialist answers were still preferred overall, both specialists and generalists rated Med-PaLM 2 to be as safe as physician answers, demonstrating its growing potential in real-world medical applications. With an improved framework for model development and evaluation, a large language model is shown to provide answers to medical questions that are comparable or preferred with respect to those provided by human physicians.","PeriodicalId":19037,"journal":{"name":"Nature Medicine","volume":"31 3","pages":"943-950"},"PeriodicalIF":50.0000,"publicationDate":"2025-01-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.nature.com/articles/s41591-024-03423-7.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Medicine","FirstCategoryId":"3","ListUrlMain":"https://www.nature.com/articles/s41591-024-03423-7","RegionNum":1,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
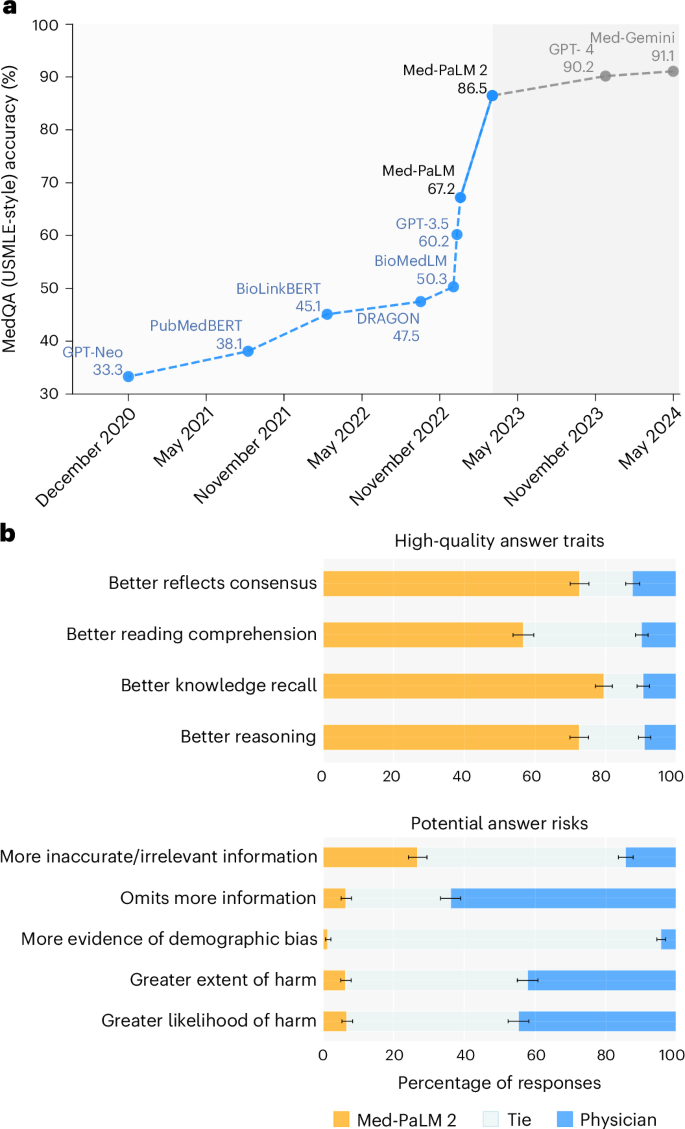
Large language models (LLMs) have shown promise in medical question answering, with Med-PaLM being the first to exceed a ‘passing’ score in United States Medical Licensing Examination style questions. However, challenges remain in long-form medical question answering and handling real-world workflows. Here, we present Med-PaLM 2, which bridges these gaps with a combination of base LLM improvements, medical domain fine-tuning and new strategies for improving reasoning and grounding through ensemble refinement and chain of retrieval. Med-PaLM 2 scores up to 86.5% on the MedQA dataset, improving upon Med-PaLM by over 19%, and demonstrates dramatic performance increases across MedMCQA, PubMedQA and MMLU clinical topics datasets. Our detailed human evaluations framework shows that physicians prefer Med-PaLM 2 answers to those from other physicians on eight of nine clinical axes. Med-PaLM 2 also demonstrates significant improvements over its predecessor across all evaluation metrics, particularly on new adversarial datasets designed to probe LLM limitations (P < 0.001). In a pilot study using real-world medical questions, specialists preferred Med-PaLM 2 answers to generalist physician answers 65% of the time. While specialist answers were still preferred overall, both specialists and generalists rated Med-PaLM 2 to be as safe as physician answers, demonstrating its growing potential in real-world medical applications. With an improved framework for model development and evaluation, a large language model is shown to provide answers to medical questions that are comparable or preferred with respect to those provided by human physicians.
期刊介绍:
Nature Medicine is a monthly journal publishing original peer-reviewed research in all areas of medicine. The publication focuses on originality, timeliness, interdisciplinary interest, and the impact on improving human health. In addition to research articles, Nature Medicine also publishes commissioned content such as News, Reviews, and Perspectives. This content aims to provide context for the latest advances in translational and clinical research, reaching a wide audience of M.D. and Ph.D. readers. All editorial decisions for the journal are made by a team of full-time professional editors.
Nature Medicine consider all types of clinical research, including:
-Case-reports and small case series
-Clinical trials, whether phase 1, 2, 3 or 4
-Observational studies
-Meta-analyses
-Biomarker studies
-Public and global health studies
Nature Medicine is also committed to facilitating communication between translational and clinical researchers. As such, we consider “hybrid” studies with preclinical and translational findings reported alongside data from clinical studies.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
