{"title":"The Venus score for the assessment of the quality and trustworthiness of biomedical datasets.","authors":"Davide Chicco, Alessandro Fabris, Giuseppe Jurman","doi":"10.1186/s13040-024-00412-x","DOIUrl":null,"url":null,"abstract":"<p><p>Biomedical datasets are the mainstays of computational biology and health informatics projects, and can be found on multiple data platforms online or obtained from wet-lab biologists and physicians. The quality and the trustworthiness of these datasets, however, can sometimes be poor, producing bad results in turn, which can harm patients and data subjects. To address this problem, policy-makers, researchers, and consortia have proposed diverse regulations, guidelines, and scores to assess the quality and increase the reliability of datasets. Although generally useful, however, they are often incomplete and impractical. The guidelines of Datasheets for Datasets, in particular, are too numerous; the requirements of the Kaggle Dataset Usability Score focus on non-scientific requisites (for example, including a cover image); and the European Union Artificial Intelligence Act (EU AI Act) sets forth sparse and general data governance requirements, which we tailored to datasets for biomedical AI. Against this backdrop, we introduce our new Venus score to assess the data quality and trustworthiness of biomedical datasets. Our score ranges from 0 to 10 and consists of ten questions that anyone developing a bioinformatics, medical informatics, or cheminformatics dataset should answer before the release. In this study, we first describe the EU AI Act, Datasheets for Datasets, and the Kaggle Dataset Usability Score, presenting their requirements and their drawbacks. To do so, we reverse-engineer the weights of the influential Kaggle Score for the first time and report them in this study. We distill the most important data governance requirements into ten questions tailored to the biomedical domain, comprising the Venus score. We apply the Venus score to twelve datasets from multiple subdomains, including electronic health records, medical imaging, microarray and bulk RNA-seq gene expression, cheminformatics, physiologic electrogram signals, and medical text. Analyzing the results, we surface fine-grained strengths and weaknesses of popular datasets, as well as aggregate trends. Most notably, we find a widespread tendency to gloss over sources of data inaccuracy and noise, which may hinder the reliable exploitation of data and, consequently, research results. Overall, our results confirm the applicability and utility of the Venus score to assess the trustworthiness of biomedical data.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"18 1","pages":"1"},"PeriodicalIF":6.1000,"publicationDate":"2025-01-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11716409/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-024-00412-x","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
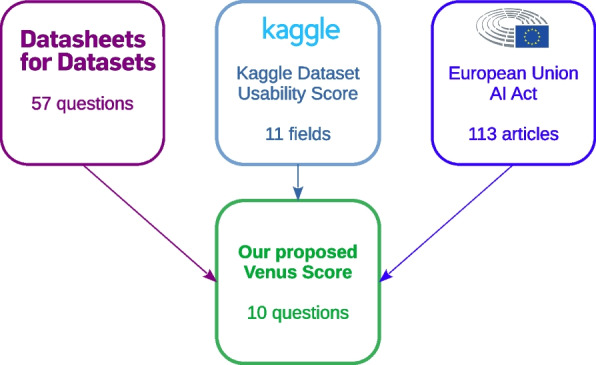
Abstract
Biomedical datasets are the mainstays of computational biology and health informatics projects, and can be found on multiple data platforms online or obtained from wet-lab biologists and physicians. The quality and the trustworthiness of these datasets, however, can sometimes be poor, producing bad results in turn, which can harm patients and data subjects. To address this problem, policy-makers, researchers, and consortia have proposed diverse regulations, guidelines, and scores to assess the quality and increase the reliability of datasets. Although generally useful, however, they are often incomplete and impractical. The guidelines of Datasheets for Datasets, in particular, are too numerous; the requirements of the Kaggle Dataset Usability Score focus on non-scientific requisites (for example, including a cover image); and the European Union Artificial Intelligence Act (EU AI Act) sets forth sparse and general data governance requirements, which we tailored to datasets for biomedical AI. Against this backdrop, we introduce our new Venus score to assess the data quality and trustworthiness of biomedical datasets. Our score ranges from 0 to 10 and consists of ten questions that anyone developing a bioinformatics, medical informatics, or cheminformatics dataset should answer before the release. In this study, we first describe the EU AI Act, Datasheets for Datasets, and the Kaggle Dataset Usability Score, presenting their requirements and their drawbacks. To do so, we reverse-engineer the weights of the influential Kaggle Score for the first time and report them in this study. We distill the most important data governance requirements into ten questions tailored to the biomedical domain, comprising the Venus score. We apply the Venus score to twelve datasets from multiple subdomains, including electronic health records, medical imaging, microarray and bulk RNA-seq gene expression, cheminformatics, physiologic electrogram signals, and medical text. Analyzing the results, we surface fine-grained strengths and weaknesses of popular datasets, as well as aggregate trends. Most notably, we find a widespread tendency to gloss over sources of data inaccuracy and noise, which may hinder the reliable exploitation of data and, consequently, research results. Overall, our results confirm the applicability and utility of the Venus score to assess the trustworthiness of biomedical data.
生物医学数据集是计算生物学和健康信息学项目的支柱,可以在多个在线数据平台上找到,也可以从湿实验室生物学家和医生那里获得。然而,这些数据集的质量和可信度有时可能很差,从而产生不好的结果,这可能会伤害患者和数据主体。为了解决这个问题,政策制定者、研究人员和协会提出了各种各样的法规、指南和评分来评估数据集的质量并提高数据集的可靠性。然而,尽管它们通常是有用的,但往往是不完整的和不切实际的。特别是,数据集的数据表指南太多了;Kaggle数据集可用性评分的要求侧重于非科学的必要条件(例如,包括封面图像);欧盟人工智能法案(EU AI Act)规定了稀疏和一般的数据治理要求,我们为生物医学人工智能的数据集量身定制了这些要求。在此背景下,我们引入了新的Venus评分来评估生物医学数据集的数据质量和可信度。我们的评分范围从0到10,由10个问题组成,任何开发生物信息学,医学信息学或化学信息学数据集的人都应该在发布之前回答这些问题。在本研究中,我们首先描述了欧盟人工智能法案、数据集数据表和Kaggle数据集可用性评分,并提出了它们的要求和缺点。为此,我们首次对有影响力的Kaggle评分的权重进行了逆向工程,并在本研究中报告了它们。我们将最重要的数据治理需求提炼成针对生物医学领域量身定制的十个问题,组成维纳斯评分。我们将Venus评分应用于来自多个子领域的12个数据集,包括电子健康记录、医学成像、微阵列和大量RNA-seq基因表达、化学信息学、生理电图信号和医学文本。分析结果,我们揭示了流行数据集的细粒度优势和劣势,以及总体趋势。最值得注意的是,我们发现了一种广泛的趋势,即掩盖数据不准确和噪音的来源,这可能会阻碍数据的可靠利用,从而影响研究结果。总体而言,我们的研究结果证实了维纳斯评分在评估生物医学数据可信度方面的适用性和实用性。
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
