Christel Sirocchi, Martin Urschler, Bastian Pfeifer
{"title":"Feature graphs for interpretable unsupervised tree ensembles: centrality, interaction, and application in disease subtyping.","authors":"Christel Sirocchi, Martin Urschler, Bastian Pfeifer","doi":"10.1186/s13040-025-00430-3","DOIUrl":null,"url":null,"abstract":"<p><p>Explainable and interpretable machine learning has emerged as essential in leveraging artificial intelligence within high-stakes domains such as healthcare to ensure transparency and trustworthiness. Feature importance analysis plays a crucial role in improving model interpretability by pinpointing the most relevant input features, particularly in disease subtyping applications, aimed at stratifying patients based on a small set of signature genes and biomarkers. While clustering methods, including unsupervised random forests, have demonstrated good performance, approaches for evaluating feature contributions in an unsupervised regime are notably scarce. To address this gap, we introduce a novel methodology to enhance the interpretability of unsupervised random forests by elucidating feature contributions through the construction of feature graphs, both over the entire dataset and individual clusters, that leverage parent-child node splits within the trees. Feature selection strategies to derive effective feature combinations from these graphs are presented and extensively evaluated on synthetic and benchmark datasets against state-of-the-art methods, standing out for performance, computational efficiency, reliability, versatility and ability to provide cluster-specific insights. In a disease subtyping application, clustering kidney cancer gene expression data over a feature subset selected with our approach reveals three patient groups with different survival outcomes. Cluster-specific analysis identifies distinctive feature contributions and interactions, essential for devising targeted interventions, conducting personalised risk assessments, and enhancing our understanding of the underlying molecular complexities.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"18 1","pages":"15"},"PeriodicalIF":6.1000,"publicationDate":"2025-02-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11829558/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-025-00430-3","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
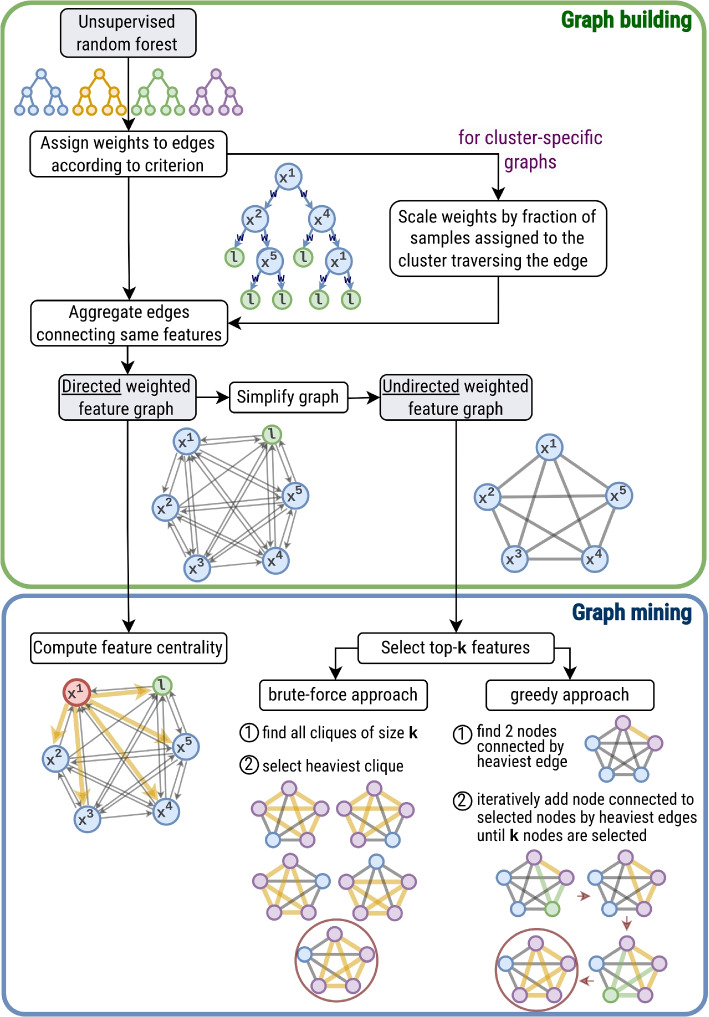
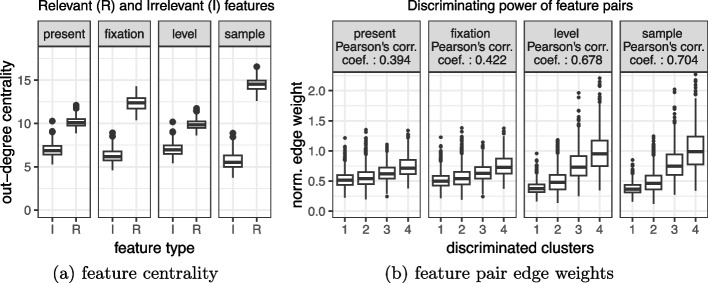
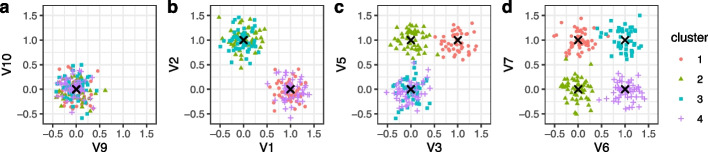
Explainable and interpretable machine learning has emerged as essential in leveraging artificial intelligence within high-stakes domains such as healthcare to ensure transparency and trustworthiness. Feature importance analysis plays a crucial role in improving model interpretability by pinpointing the most relevant input features, particularly in disease subtyping applications, aimed at stratifying patients based on a small set of signature genes and biomarkers. While clustering methods, including unsupervised random forests, have demonstrated good performance, approaches for evaluating feature contributions in an unsupervised regime are notably scarce. To address this gap, we introduce a novel methodology to enhance the interpretability of unsupervised random forests by elucidating feature contributions through the construction of feature graphs, both over the entire dataset and individual clusters, that leverage parent-child node splits within the trees. Feature selection strategies to derive effective feature combinations from these graphs are presented and extensively evaluated on synthetic and benchmark datasets against state-of-the-art methods, standing out for performance, computational efficiency, reliability, versatility and ability to provide cluster-specific insights. In a disease subtyping application, clustering kidney cancer gene expression data over a feature subset selected with our approach reveals three patient groups with different survival outcomes. Cluster-specific analysis identifies distinctive feature contributions and interactions, essential for devising targeted interventions, conducting personalised risk assessments, and enhancing our understanding of the underlying molecular complexities.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
