Yong Zhang, Xiao Lu, Yan Luo, Ying Zhu, Wenwu Ling
{"title":"Performance of Artificial Intelligence Chatbots on Ultrasound Examinations: Cross-Sectional Comparative Analysis.","authors":"Yong Zhang, Xiao Lu, Yan Luo, Ying Zhu, Wenwu Ling","doi":"10.2196/63924","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Artificial intelligence chatbots are being increasingly used for medical inquiries, particularly in the field of ultrasound medicine. However, their performance varies and is influenced by factors such as language, question type, and topic.</p><p><strong>Objective: </strong>This study aimed to evaluate the performance of ChatGPT and ERNIE Bot in answering ultrasound-related medical examination questions, providing insights for users and developers.</p><p><strong>Methods: </strong>We curated 554 questions from ultrasound medicine examinations, covering various question types and topics. The questions were posed in both English and Chinese. Objective questions were scored based on accuracy rates, whereas subjective questions were rated by 5 experienced doctors using a Likert scale. The data were analyzed in Excel.</p><p><strong>Results: </strong>Of the 554 questions included in this study, single-choice questions comprised the largest share (354/554, 64%), followed by short answers (69/554, 12%) and noun explanations (63/554, 11%). The accuracy rates for objective questions ranged from 8.33% to 80%, with true or false questions scoring highest. Subjective questions received acceptability rates ranging from 47.62% to 75.36%. ERNIE Bot was superior to ChatGPT in many aspects (P<.05). Both models showed a performance decline in English, but ERNIE Bot's decline was less significant. The models performed better in terms of basic knowledge, ultrasound methods, and diseases than in terms of ultrasound signs and diagnosis.</p><p><strong>Conclusions: </strong>Chatbots can provide valuable ultrasound-related answers, but performance differs by model and is influenced by language, question type, and topic. In general, ERNIE Bot outperforms ChatGPT. Users and developers should understand model performance characteristics and select appropriate models for different questions and languages to optimize chatbot use.</p>","PeriodicalId":56334,"journal":{"name":"JMIR Medical Informatics","volume":"13 ","pages":"e63924"},"PeriodicalIF":3.8000,"publicationDate":"2025-01-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11737282/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR Medical Informatics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.2196/63924","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
引用次数: 0
Abstract
Background: Artificial intelligence chatbots are being increasingly used for medical inquiries, particularly in the field of ultrasound medicine. However, their performance varies and is influenced by factors such as language, question type, and topic.
Objective: This study aimed to evaluate the performance of ChatGPT and ERNIE Bot in answering ultrasound-related medical examination questions, providing insights for users and developers.
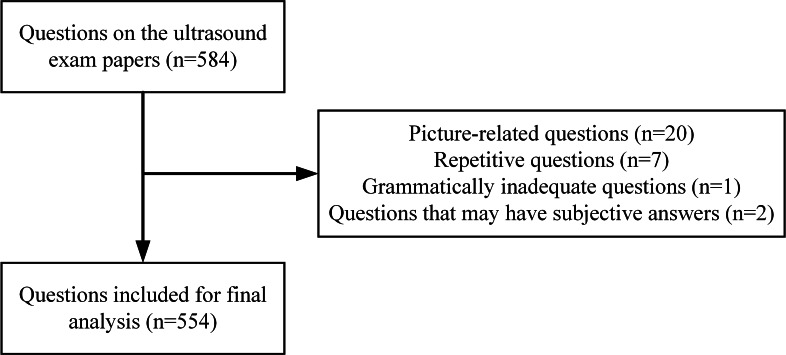
Methods: We curated 554 questions from ultrasound medicine examinations, covering various question types and topics. The questions were posed in both English and Chinese. Objective questions were scored based on accuracy rates, whereas subjective questions were rated by 5 experienced doctors using a Likert scale. The data were analyzed in Excel.
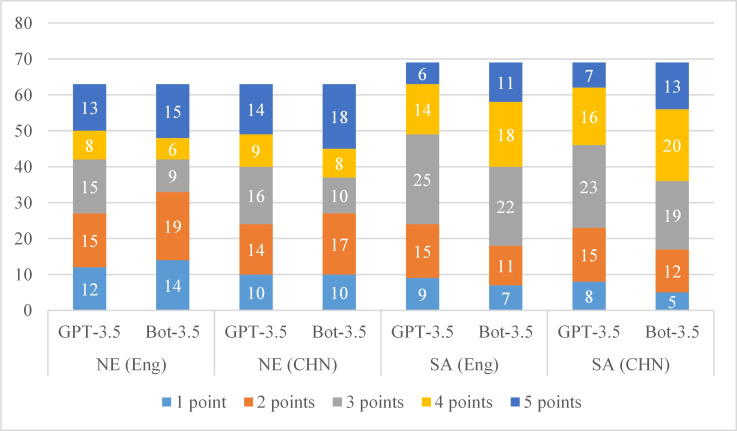
Results: Of the 554 questions included in this study, single-choice questions comprised the largest share (354/554, 64%), followed by short answers (69/554, 12%) and noun explanations (63/554, 11%). The accuracy rates for objective questions ranged from 8.33% to 80%, with true or false questions scoring highest. Subjective questions received acceptability rates ranging from 47.62% to 75.36%. ERNIE Bot was superior to ChatGPT in many aspects (P<.05). Both models showed a performance decline in English, but ERNIE Bot's decline was less significant. The models performed better in terms of basic knowledge, ultrasound methods, and diseases than in terms of ultrasound signs and diagnosis.
Conclusions: Chatbots can provide valuable ultrasound-related answers, but performance differs by model and is influenced by language, question type, and topic. In general, ERNIE Bot outperforms ChatGPT. Users and developers should understand model performance characteristics and select appropriate models for different questions and languages to optimize chatbot use.
期刊介绍:
JMIR Medical Informatics (JMI, ISSN 2291-9694) is a top-rated, tier A journal which focuses on clinical informatics, big data in health and health care, decision support for health professionals, electronic health records, ehealth infrastructures and implementation. It has a focus on applied, translational research, with a broad readership including clinicians, CIOs, engineers, industry and health informatics professionals.
Published by JMIR Publications, publisher of the Journal of Medical Internet Research (JMIR), the leading eHealth/mHealth journal (Impact Factor 2016: 5.175), JMIR Med Inform has a slightly different scope (emphasizing more on applications for clinicians and health professionals rather than consumers/citizens, which is the focus of JMIR), publishes even faster, and also allows papers which are more technical or more formative than what would be published in the Journal of Medical Internet Research.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
