{"title":"Evaluating the Potential of Large Language Models for Vestibular Rehabilitation Education: A Comparison of ChatGPT, Google Gemini, and Clinicians.","authors":"Yael Arbel, Yoav Gimmon, Liora Shmueli","doi":"10.1093/ptj/pzaf010","DOIUrl":null,"url":null,"abstract":"<p><strong>Objective: </strong>This study aimed to compare the performance of 2 large language models, ChatGPT (Generative Pre-trained Transformer) and Google Gemini, against experienced physical therapists and students in responding to multiple-choice questions related to vestibular rehabilitation. The study further aimed to assess the accuracy of ChatGPT's responses by board-certified otoneurologists.</p><p><strong>Methods: </strong>This study was conducted among 30 physical therapist professionals experienced with vestibular rehabilitation and 30 physical therapist students. They were asked to complete a vestibular knowledge test (VKT) consisting of 20 multiple-choice questions that were divided into 3 categories: (1) Clinical Knowledge, (2) Basic Clinical Practice, and (3) Clinical Reasoning. ChatGPT and Google Gemini were tasked with answering the same 20 VKT questions. Three board-certified otoneurologists independently evaluated the accuracy of each response using a 4-level scale, ranging from comprehensive to completely incorrect.</p><p><strong>Results: </strong>ChatGPT outperformed Google Gemini with a 70% score on the VKT test, while Gemini scored 60%. Both excelled in Clinical Knowledge scoring 100% but struggled in Clinical Reasoning with ChatGPT scoring 50% and Gemini scoring 25%. According to 3 otoneurologic experts, ChatGPT's accuracy was considered \"comprehensive\" in 45% of the 20 questions, while 25% were found to be completely incorrect. ChatGPT provided \"comprehensive\" responses in 50% of Clinical Knowledge and Basic Clinical Practice questions, but only 25% in Clinical Reasoning.</p><p><strong>Conclusion: </strong>Caution is advised when using ChatGPT and Google Gemini due to their limited accuracy in clinical reasoning. While they provide accurate responses concerning Clinical Knowledge, their reliance on web information may lead to inconsistencies. ChatGPT performed better than Gemini. Health care professionals should carefully formulate questions and be aware of the potential influence of the online prevalence of information on ChatGPT's and Google Gemini's responses. Combining clinical expertise and clinical guidelines with ChatGPT and Google Gemini can maximize benefits while mitigating limitations. The results are based on current models of ChatGPT3.5 and Google Gemini. Future iterations of these models are expected to offer improved accuracy as the underlying modeling and algorithms are further refined.</p><p><strong>Impact: </strong>This study highlights the potential utility of large language models like ChatGPT in supplementing clinical knowledge for physical therapists, while underscoring the need for caution in domains requiring complex clinical reasoning. The findings emphasize the importance of integrating technological tools carefully with human expertise to enhance patient care and rehabilitation outcomes.</p>","PeriodicalId":20093,"journal":{"name":"Physical Therapy","volume":" ","pages":""},"PeriodicalIF":3.3000,"publicationDate":"2025-04-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11994992/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Physical Therapy","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1093/ptj/pzaf010","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"ORTHOPEDICS","Score":null,"Total":0}
引用次数: 0
Abstract
Objective: This study aimed to compare the performance of 2 large language models, ChatGPT (Generative Pre-trained Transformer) and Google Gemini, against experienced physical therapists and students in responding to multiple-choice questions related to vestibular rehabilitation. The study further aimed to assess the accuracy of ChatGPT's responses by board-certified otoneurologists.
Methods: This study was conducted among 30 physical therapist professionals experienced with vestibular rehabilitation and 30 physical therapist students. They were asked to complete a vestibular knowledge test (VKT) consisting of 20 multiple-choice questions that were divided into 3 categories: (1) Clinical Knowledge, (2) Basic Clinical Practice, and (3) Clinical Reasoning. ChatGPT and Google Gemini were tasked with answering the same 20 VKT questions. Three board-certified otoneurologists independently evaluated the accuracy of each response using a 4-level scale, ranging from comprehensive to completely incorrect.
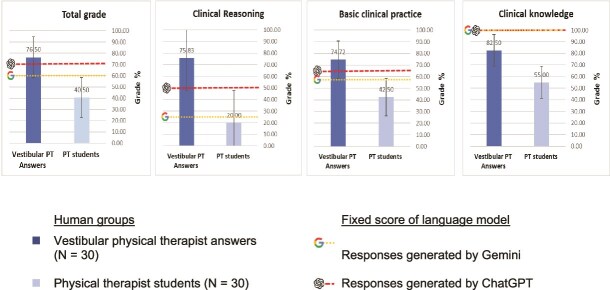
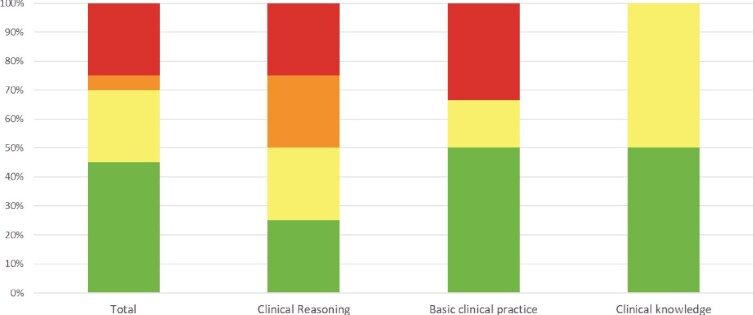
Results: ChatGPT outperformed Google Gemini with a 70% score on the VKT test, while Gemini scored 60%. Both excelled in Clinical Knowledge scoring 100% but struggled in Clinical Reasoning with ChatGPT scoring 50% and Gemini scoring 25%. According to 3 otoneurologic experts, ChatGPT's accuracy was considered "comprehensive" in 45% of the 20 questions, while 25% were found to be completely incorrect. ChatGPT provided "comprehensive" responses in 50% of Clinical Knowledge and Basic Clinical Practice questions, but only 25% in Clinical Reasoning.
Conclusion: Caution is advised when using ChatGPT and Google Gemini due to their limited accuracy in clinical reasoning. While they provide accurate responses concerning Clinical Knowledge, their reliance on web information may lead to inconsistencies. ChatGPT performed better than Gemini. Health care professionals should carefully formulate questions and be aware of the potential influence of the online prevalence of information on ChatGPT's and Google Gemini's responses. Combining clinical expertise and clinical guidelines with ChatGPT and Google Gemini can maximize benefits while mitigating limitations. The results are based on current models of ChatGPT3.5 and Google Gemini. Future iterations of these models are expected to offer improved accuracy as the underlying modeling and algorithms are further refined.
Impact: This study highlights the potential utility of large language models like ChatGPT in supplementing clinical knowledge for physical therapists, while underscoring the need for caution in domains requiring complex clinical reasoning. The findings emphasize the importance of integrating technological tools carefully with human expertise to enhance patient care and rehabilitation outcomes.
期刊介绍:
Physical Therapy (PTJ) engages and inspires an international readership on topics related to physical therapy. As the leading international journal for research in physical therapy and related fields, PTJ publishes innovative and highly relevant content for both clinicians and scientists and uses a variety of interactive approaches to communicate that content, with the expressed purpose of improving patient care. PTJ"s circulation in 2008 is more than 72,000. Its 2007 impact factor was 2.152. The mean time from submission to first decision is 58 days. Time from acceptance to publication online is less than or equal to 3 months and from acceptance to publication in print is less than or equal to 5 months.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
