Andrew Trigg, Claudia Haberland, Huda Shalhoub, Christoph Gerlinger, Christian Seitz
{"title":"Comparative performance of PROMIS Sleep Disturbance computerized adaptive testing algorithms and static short form in postmenopausal women.","authors":"Andrew Trigg, Claudia Haberland, Huda Shalhoub, Christoph Gerlinger, Christian Seitz","doi":"10.1186/s41687-025-00849-6","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The Patient-Reported Outcomes Measurement Information System (PROMIS) Sleep Disturbance v1.0 item bank (27 items) measures sleep disturbances. Rather than the full item bank, an 8-item short form (PROMIS SD SF 8b) or computerized adaptive testing (CAT) can be used. This study compares the performance of the PROMIS SD SF 8b with two CAT algorithms in postmenopausal women.</p><p><strong>Methods: </strong>This is a secondary analysis of data collected for the original psychometric testing of the PROMIS Sleep Disturbance item bank, in a sub-sample of women aged ≥55. A graded response model (GRM) was fitted for the item bank, then simulations evaluated the performance of CAT algorithms and the short form, in terms of root mean square error (RMSE) versus the latent trait estimate derived from the full bank. Two CAT algorithms were tested: CAT1 (stop once standard error <0.3 or 12 items administered) and CAT2 (stop once 8 items administered). Convergent and divergent hypotheses for validity were tested through correlations with the Pittsburgh Sleep Quality Index (PSQI) and Epworth Sleepiness Scale (ESS). Known-groups comparisons were made between those with and without self-reported sleep disorder.</p><p><strong>Results: </strong>A sample of 337 women was analyzed. Unidimensionality and item-level fit to the GRM was supported; however, the local independence assumption was violated. The CAT1 algorithm showed 4.18 items on average, with a minor decrease in performance (higher RMSE value) compared to CAT2 or the PROMIS SD SF 8b. Administering 8 items adaptively (CAT2) compared to fixed (PROMIS SD SF 8b) performed similarly (RMSE difference = 0.001). Reliability exceeded 0.90 across most of the latent trait for all approaches. Correlations with the PSQI and ESS were largely as hypothesized, with minor differences in coefficient values between the approaches (all within 0.05). Women reporting a sleep disorder had greater sleep disturbance than those who did not (p < 0.001 for all).</p><p><strong>Conclusions: </strong>The results of this study support using the PROMIS Sleep Disturbance item bank in postmenopausal women. The choice of PROMIS SD SF 8b versus CAT can largely be driven by practical reasons (respondent burden and operational complexity) rather than concerns of differential reliability and validity.</p>","PeriodicalId":36660,"journal":{"name":"Journal of Patient-Reported Outcomes","volume":"9 1","pages":"18"},"PeriodicalIF":2.9000,"publicationDate":"2025-02-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11832987/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Patient-Reported Outcomes","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s41687-025-00849-6","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
引用次数: 0
Abstract
Background: The Patient-Reported Outcomes Measurement Information System (PROMIS) Sleep Disturbance v1.0 item bank (27 items) measures sleep disturbances. Rather than the full item bank, an 8-item short form (PROMIS SD SF 8b) or computerized adaptive testing (CAT) can be used. This study compares the performance of the PROMIS SD SF 8b with two CAT algorithms in postmenopausal women.
Methods: This is a secondary analysis of data collected for the original psychometric testing of the PROMIS Sleep Disturbance item bank, in a sub-sample of women aged ≥55. A graded response model (GRM) was fitted for the item bank, then simulations evaluated the performance of CAT algorithms and the short form, in terms of root mean square error (RMSE) versus the latent trait estimate derived from the full bank. Two CAT algorithms were tested: CAT1 (stop once standard error <0.3 or 12 items administered) and CAT2 (stop once 8 items administered). Convergent and divergent hypotheses for validity were tested through correlations with the Pittsburgh Sleep Quality Index (PSQI) and Epworth Sleepiness Scale (ESS). Known-groups comparisons were made between those with and without self-reported sleep disorder.
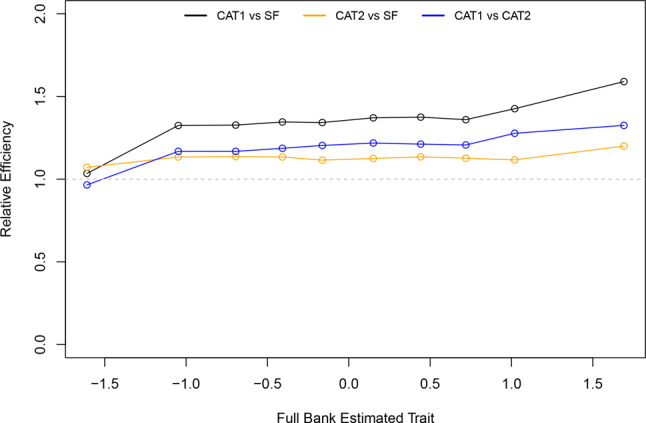
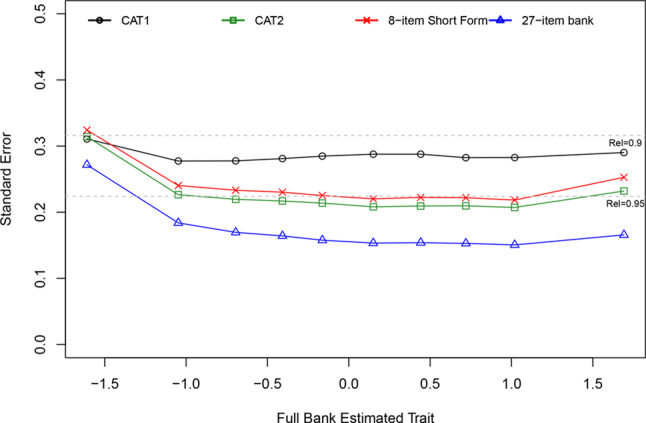
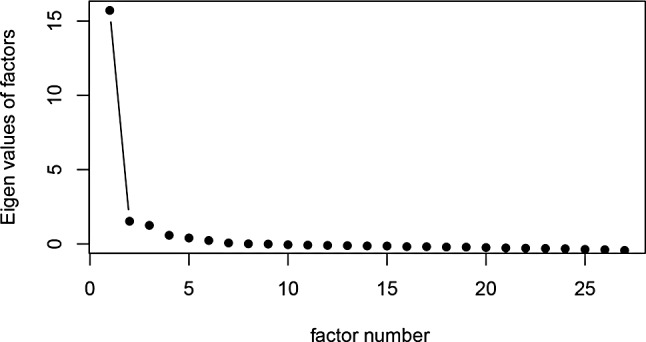
Results: A sample of 337 women was analyzed. Unidimensionality and item-level fit to the GRM was supported; however, the local independence assumption was violated. The CAT1 algorithm showed 4.18 items on average, with a minor decrease in performance (higher RMSE value) compared to CAT2 or the PROMIS SD SF 8b. Administering 8 items adaptively (CAT2) compared to fixed (PROMIS SD SF 8b) performed similarly (RMSE difference = 0.001). Reliability exceeded 0.90 across most of the latent trait for all approaches. Correlations with the PSQI and ESS were largely as hypothesized, with minor differences in coefficient values between the approaches (all within 0.05). Women reporting a sleep disorder had greater sleep disturbance than those who did not (p < 0.001 for all).
Conclusions: The results of this study support using the PROMIS Sleep Disturbance item bank in postmenopausal women. The choice of PROMIS SD SF 8b versus CAT can largely be driven by practical reasons (respondent burden and operational complexity) rather than concerns of differential reliability and validity.
背景:患者报告结果测量信息系统(PROMIS)睡眠障碍v1.0项目库(27个项目)测量睡眠障碍。可以使用8项短表(PROMIS SD SF 8b)或计算机自适应测试(CAT),而不是完整的题库。本研究比较了PROMIS SD SF 8b与两种CAT算法在绝经后妇女中的表现。方法:这是对PROMIS睡眠障碍题库的原始心理测量测试收集的数据的二次分析,在年龄≥55岁的女性子样本中。对题库拟合了分级响应模型(GRM),然后模拟评估了CAT算法和简短形式的性能,根据均方根误差(RMSE)与从完整题库获得的潜在特征估计。测试了两种CAT算法:CAT1(一次标准误差停止)结果:分析了337名女性的样本。支持GRM的单维性和项目级拟合;但是,这违反了局部独立假设。CAT1算法平均显示4.18个项目,与CAT2或PROMIS SD SF 8b相比,性能略有下降(RMSE值较高)。与固定管理(PROMIS SD SF 8b)相比,自适应管理8个项目(CAT2)的效果相似(RMSE差异= 0.001)。所有方法的大部分潜在性状的信度均超过0.90。与PSQI和ESS的相关性在很大程度上与假设一致,两种方法之间的系数值差异较小(均在0.05以内)。报告睡眠障碍的妇女比没有报告睡眠障碍的妇女有更大的睡眠障碍(p)结论:本研究的结果支持在绝经后妇女中使用PROMIS睡眠障碍项目库。选择PROMIS SD SF 8b和CAT主要是由实际原因(被调查者负担和操作复杂性)驱动的,而不是考虑不同的信度和效度。




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
