{"title":"Scalable and robust DNA-based storage via coding theory and deep learning","authors":"Daniella Bar-Lev, Itai Orr, Omer Sabary, Tuvi Etzion, Eitan Yaakobi","doi":"10.1038/s42256-025-01003-z","DOIUrl":null,"url":null,"abstract":"The global data sphere is expanding exponentially, projected to hit 180 zettabytes by 2025, whereas current technologies are not anticipated to scale at nearly the same rate. DNA-based storage emerges as a crucial solution to this gap, enabling digital information to be archived in DNA molecules. This method enjoys major advantages over magnetic and optical storage solutions such as exceptional information density, enhanced data durability and negligible power consumption to maintain data integrity. To access the data, an information retrieval process is employed, where some of the main bottlenecks are the scalability and accuracy, which have a natural tradeoff between the two. Here we show a modular and holistic approach that combines deep neural networks trained on simulated data, tensor product-based error-correcting codes and a safety margin mechanism into a single coherent pipeline. We demonstrated our solution on 3.1 MB of information using two different sequencing technologies. Our work improves upon the current leading solutions with a 3,200× increase in speed and a 40% improvement in accuracy and offers a code rate of 1.6 bits per base in a high-noise regime. In a broader sense, our work shows a viable path to commercial DNA storage solutions hindered by current information retrieval processes. Bar-Lev et al. propose a high-efficiency DNA-based storage pipeline that integrates deep neural networks, error-correcting codes and safety margins, achieving a 3,200× speed improvement and a 40% accuracy gain, paving the way for commercially viable DNA data storage.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"7 4","pages":"639-649"},"PeriodicalIF":23.9000,"publicationDate":"2025-02-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-025-01003-z","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
Abstract
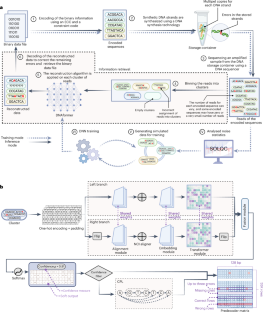
The global data sphere is expanding exponentially, projected to hit 180 zettabytes by 2025, whereas current technologies are not anticipated to scale at nearly the same rate. DNA-based storage emerges as a crucial solution to this gap, enabling digital information to be archived in DNA molecules. This method enjoys major advantages over magnetic and optical storage solutions such as exceptional information density, enhanced data durability and negligible power consumption to maintain data integrity. To access the data, an information retrieval process is employed, where some of the main bottlenecks are the scalability and accuracy, which have a natural tradeoff between the two. Here we show a modular and holistic approach that combines deep neural networks trained on simulated data, tensor product-based error-correcting codes and a safety margin mechanism into a single coherent pipeline. We demonstrated our solution on 3.1 MB of information using two different sequencing technologies. Our work improves upon the current leading solutions with a 3,200× increase in speed and a 40% improvement in accuracy and offers a code rate of 1.6 bits per base in a high-noise regime. In a broader sense, our work shows a viable path to commercial DNA storage solutions hindered by current information retrieval processes. Bar-Lev et al. propose a high-efficiency DNA-based storage pipeline that integrates deep neural networks, error-correcting codes and safety margins, achieving a 3,200× speed improvement and a 40% accuracy gain, paving the way for commercially viable DNA data storage.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
