{"title":"ChatGPT-4o in Risk-of-Bias Assessments in Neonatology: A Validity Analysis.","authors":"Ilari Kuitunen, Lauri Nyrhi, Daniele De Luca","doi":"10.1159/000544857","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Only a few studies have addressed the potential of large language models (LLMs) in risk-of-bias assessments and the results have been varying. The aim of this study was to analyze how well ChatGPT performs in risk-of-bias assessments of neonatal studies.</p><p><strong>Methods: </strong>We searched all Cochrane neonatal intervention reviews published in 2024 and extracted all risk-of-bias assessments. Then the full reports were retrieved and uploaded alongside the guidance to perform a Cochrane original risk-of-bias analysis in ChatGPT-4o. The concordance between the original assessment and that provided by ChatGPT-4o was evaluated by inter-class correlation coefficients and Cohen's kappa statistics (with 95% confidence intervals) for each risk-of-bias domain and for the overall assessment.</p><p><strong>Results: </strong>From 9 reviews, a total of 61 randomized studies were analyzed. A total of 427 judgments were compared. The overall κ was 0.43 (95% CI: 0.35-0.51) and the overall intraclass correlation coefficient was 0.65 (95% CI: 0.59-0.70). The Cohen's κ was assessed for each domain and the best agreement was observed in the allocation concealment (κ = 0.73, 95% CI: 0.55-0.90), whereas the poorest agreement was found in incomplete outcome data (κ = -0.03, 95% CI: -0.07-0.02).</p><p><strong>Conclusion: </strong>ChatGPT-4o failed to achieve sufficient agreement in the risk-of-bias assessments. Future studies should examine whether the performance of other LLM would be better or whether the agreement in ChatGPT-4o could be further enhanced by better prompting. Currently, the use of ChatGPT-4o in risk-of-bias assessments should not be promoted.</p>","PeriodicalId":94152,"journal":{"name":"Neonatology","volume":" ","pages":"360-365"},"PeriodicalIF":3.0000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12129414/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neonatology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1159/000544857","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/2/25 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
Abstract
Introduction: Only a few studies have addressed the potential of large language models (LLMs) in risk-of-bias assessments and the results have been varying. The aim of this study was to analyze how well ChatGPT performs in risk-of-bias assessments of neonatal studies.
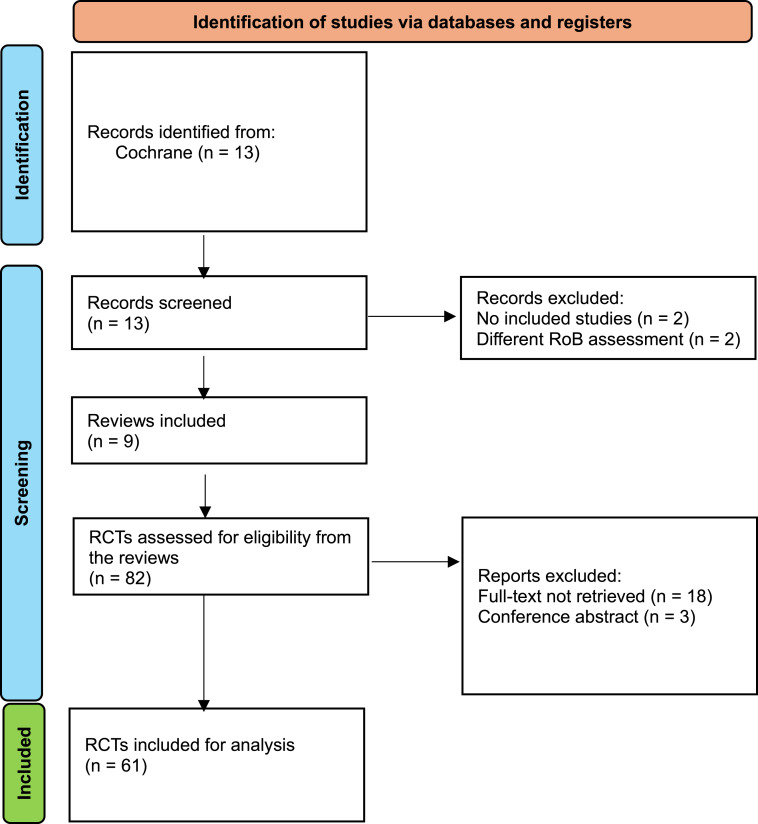
Methods: We searched all Cochrane neonatal intervention reviews published in 2024 and extracted all risk-of-bias assessments. Then the full reports were retrieved and uploaded alongside the guidance to perform a Cochrane original risk-of-bias analysis in ChatGPT-4o. The concordance between the original assessment and that provided by ChatGPT-4o was evaluated by inter-class correlation coefficients and Cohen's kappa statistics (with 95% confidence intervals) for each risk-of-bias domain and for the overall assessment.
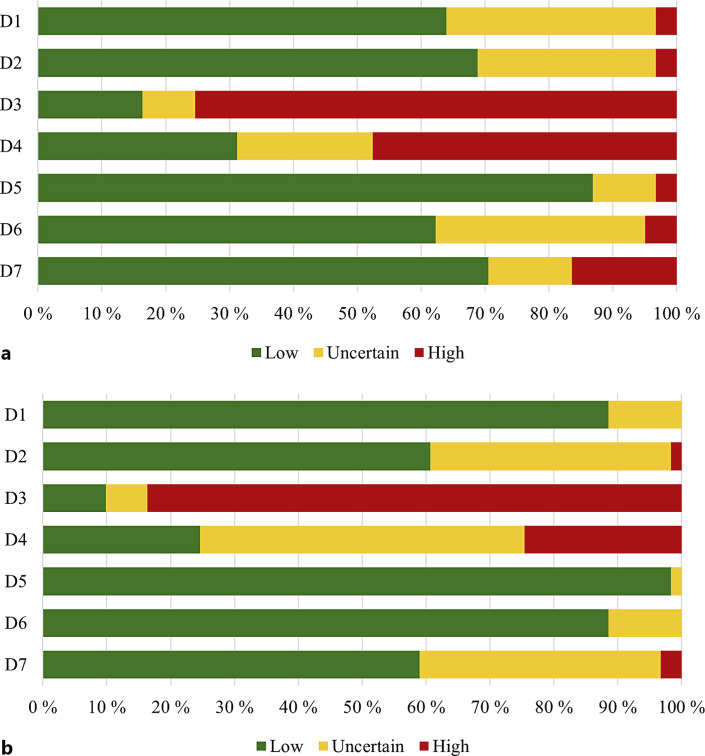
Results: From 9 reviews, a total of 61 randomized studies were analyzed. A total of 427 judgments were compared. The overall κ was 0.43 (95% CI: 0.35-0.51) and the overall intraclass correlation coefficient was 0.65 (95% CI: 0.59-0.70). The Cohen's κ was assessed for each domain and the best agreement was observed in the allocation concealment (κ = 0.73, 95% CI: 0.55-0.90), whereas the poorest agreement was found in incomplete outcome data (κ = -0.03, 95% CI: -0.07-0.02).
Conclusion: ChatGPT-4o failed to achieve sufficient agreement in the risk-of-bias assessments. Future studies should examine whether the performance of other LLM would be better or whether the agreement in ChatGPT-4o could be further enhanced by better prompting. Currently, the use of ChatGPT-4o in risk-of-bias assessments should not be promoted.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
