{"title":"Singing to speech conversion with generative flow.","authors":"Jiawen Huang, Emmanouil Benetos","doi":"10.1186/s13636-025-00400-x","DOIUrl":null,"url":null,"abstract":"<p><p>This paper introduces singing to speech conversion (S2S), a cross-domain voice conversion task, and presents the first deep learning-based S2S system. S2S aims to transform singing into speech while retaining the phonetic information, reducing variations in pitch, rhythm, and timbre. Inspired by the Glow-TTS architecture, the proposed model is built using generative flow, with an adjusted alignment module between the latent features. We adapt the original monotonic alignment search (MAS) to the S2S scenario and utilize a duration predictor to deal with the duration differences between the two modalities. Subjective evaluations show that the proposed model outperforms signal processing baselines in naturalness and outperforms a transcribe-and-synthesize baseline in phonetic similarity to the original singing. We further demonstrate that singing-to-speech could be an effective augmentation method for low-resource lyrics transcription.</p>","PeriodicalId":49202,"journal":{"name":"Eurasip Journal on Audio Speech and Music Processing","volume":"2025 1","pages":"12"},"PeriodicalIF":1.9000,"publicationDate":"2025-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11893632/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Eurasip Journal on Audio Speech and Music Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s13636-025-00400-x","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/3/10 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ACOUSTICS","Score":null,"Total":0}
引用次数: 0
Abstract
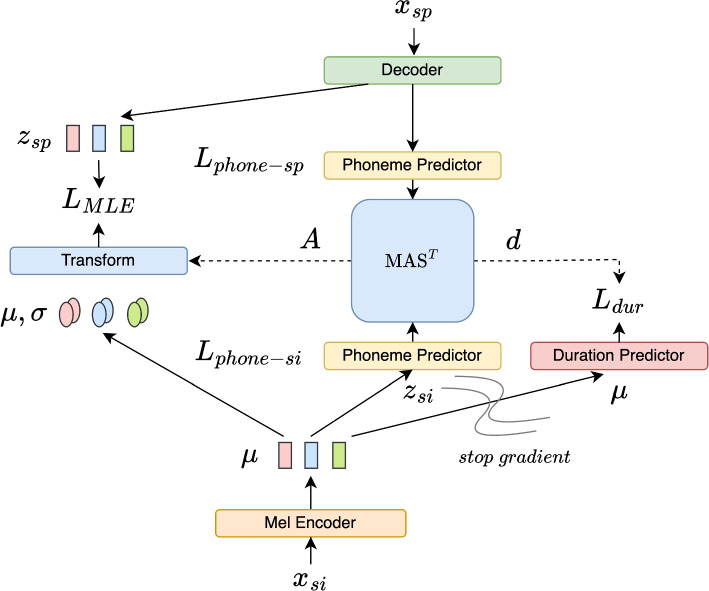
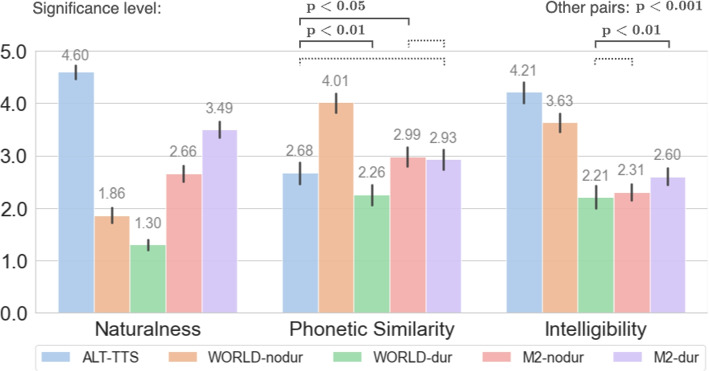
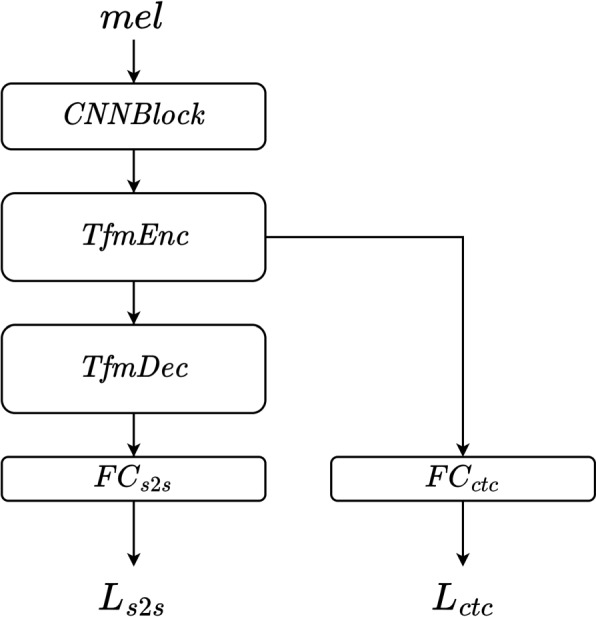
This paper introduces singing to speech conversion (S2S), a cross-domain voice conversion task, and presents the first deep learning-based S2S system. S2S aims to transform singing into speech while retaining the phonetic information, reducing variations in pitch, rhythm, and timbre. Inspired by the Glow-TTS architecture, the proposed model is built using generative flow, with an adjusted alignment module between the latent features. We adapt the original monotonic alignment search (MAS) to the S2S scenario and utilize a duration predictor to deal with the duration differences between the two modalities. Subjective evaluations show that the proposed model outperforms signal processing baselines in naturalness and outperforms a transcribe-and-synthesize baseline in phonetic similarity to the original singing. We further demonstrate that singing-to-speech could be an effective augmentation method for low-resource lyrics transcription.
期刊介绍:
The aim of “EURASIP Journal on Audio, Speech, and Music Processing” is to bring together researchers, scientists and engineers working on the theory and applications of the processing of various audio signals, with a specific focus on speech and music. EURASIP Journal on Audio, Speech, and Music Processing will be an interdisciplinary journal for the dissemination of all basic and applied aspects of speech communication and audio processes.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
