Can Sequential Images from the Same Object Be Used for Training Machine Learning Models? A Case Study for Detecting Liver Disease by Ultrasound Radiomics.
Laith R Sultan, Theodore W Cary, Maryam Al-Hasani, Mrigendra B Karmacharya, Santosh S Venkatesh, Charles-Antoine Assenmacher, Enrico Radaelli, Chandra M Sehgal
{"title":"Can Sequential Images from the Same Object Be Used for Training Machine Learning Models? A Case Study for Detecting Liver Disease by Ultrasound Radiomics.","authors":"Laith R Sultan, Theodore W Cary, Maryam Al-Hasani, Mrigendra B Karmacharya, Santosh S Venkatesh, Charles-Antoine Assenmacher, Enrico Radaelli, Chandra M Sehgal","doi":"10.3390/ai3030043","DOIUrl":null,"url":null,"abstract":"Machine learning for medical imaging not only requires sufficient amounts of data for training and testing but also that the data be independent. It is common to see highly interdependent data whenever there are inherent correlations between observations. This is especially to be expected for sequential imaging data taken from time series. In this study, we evaluate the use of statistical measures to test the independence of sequential ultrasound image data taken from the same case. A total of 1180 B-mode liver ultrasound images with 5903 regions of interests were analyzed. The ultrasound images were taken from two liver disease groups, fibrosis and steatosis, as well as normal cases. Computer-extracted texture features were then used to train a machine learning (ML) model for computer-aided diagnosis. The experiment resulted in high two-category diagnosis using logistic regression, with AUC of 0.928 and high performance of multicategory classification, using random forest ML, with AUC of 0.917. To evaluate the image region independence for machine learning, Jenson–Shannon (JS) divergence was used. JS distributions showed that images of normal liver were independent from each other, while the images from the two disease pathologies were not independent. To guarantee the generalizability of machine learning models, and to prevent data leakage, multiple frames of image data acquired of the same object should be tested for independence before machine learning. Such tests can be applied to real-world medical image problems to determine if images from the same subject can be used for training.","PeriodicalId":93633,"journal":{"name":"AI (Basel, Switzerland)","volume":"3 3","pages":"739-750"},"PeriodicalIF":5.0000,"publicationDate":"2022-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9511699/pdf/","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"AI (Basel, Switzerland)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/ai3030043","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 1
Abstract
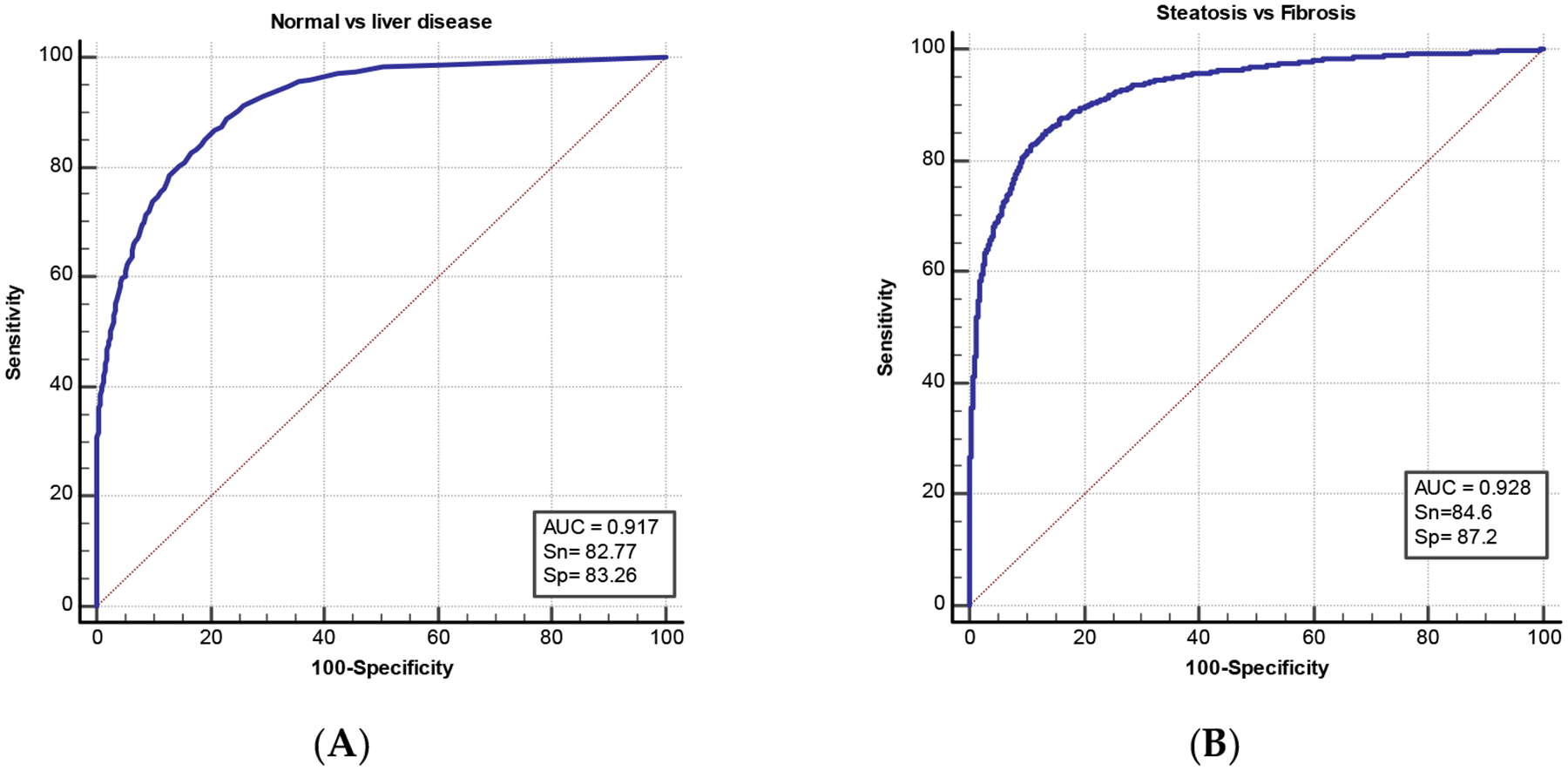
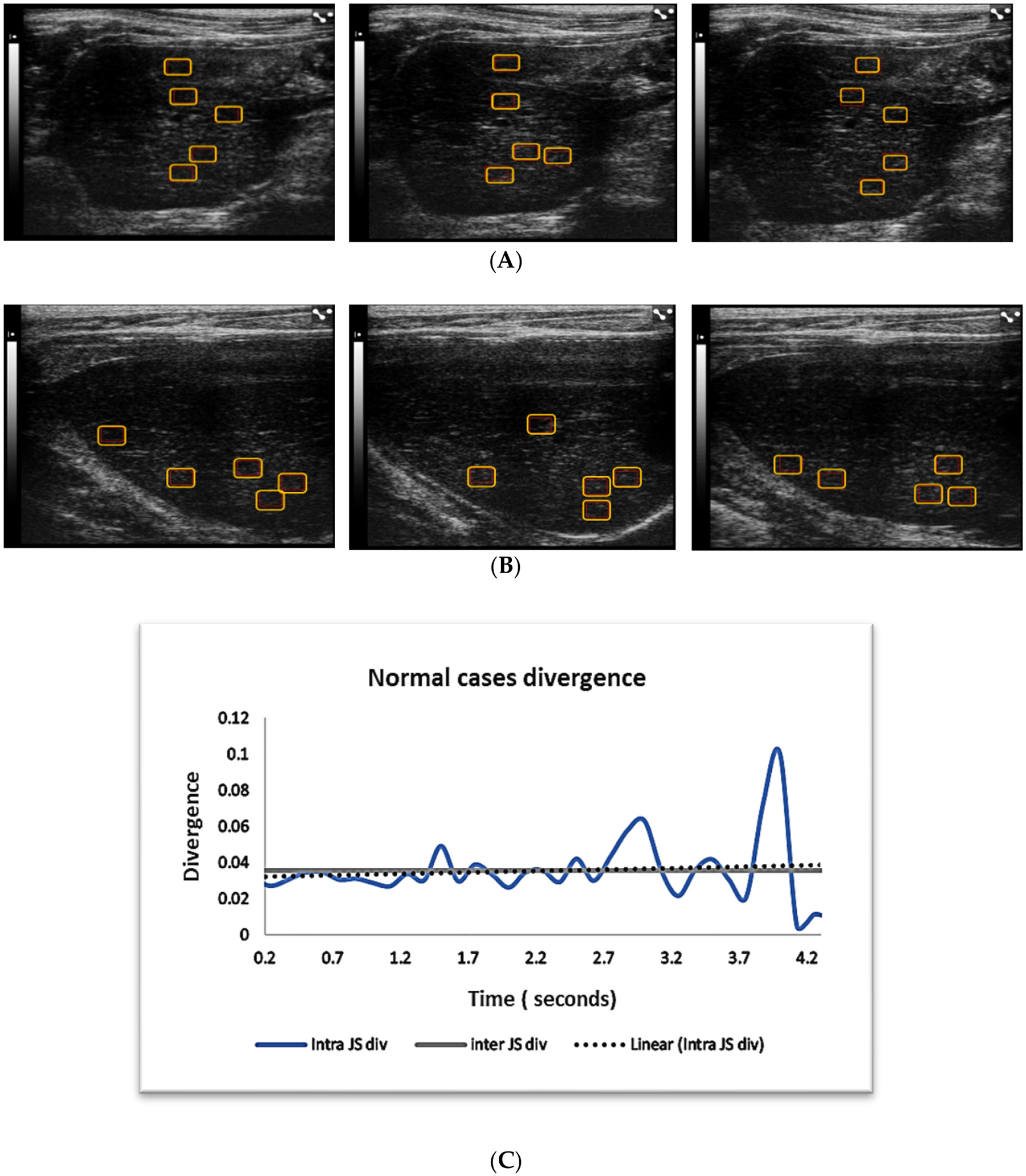
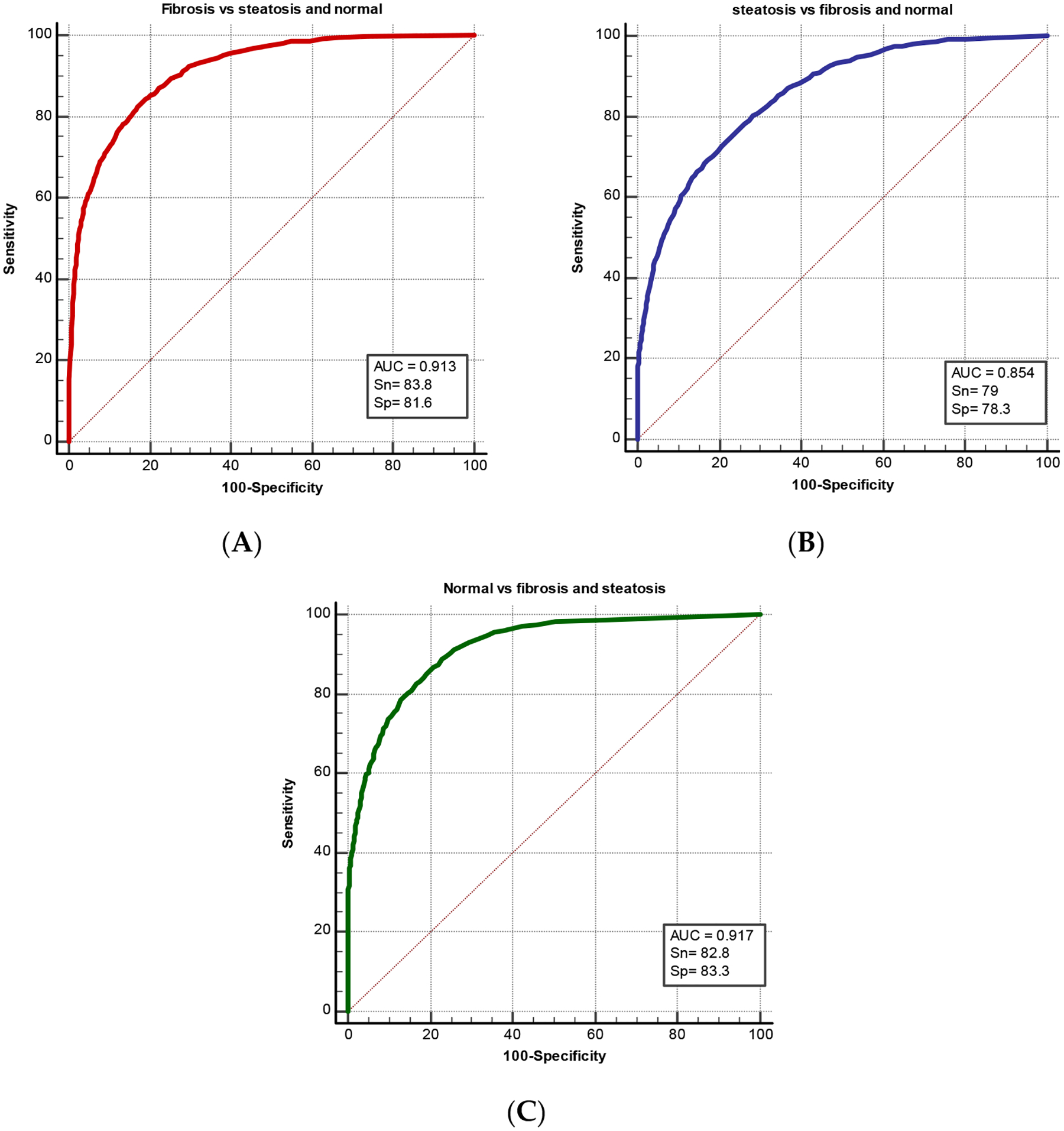
Machine learning for medical imaging not only requires sufficient amounts of data for training and testing but also that the data be independent. It is common to see highly interdependent data whenever there are inherent correlations between observations. This is especially to be expected for sequential imaging data taken from time series. In this study, we evaluate the use of statistical measures to test the independence of sequential ultrasound image data taken from the same case. A total of 1180 B-mode liver ultrasound images with 5903 regions of interests were analyzed. The ultrasound images were taken from two liver disease groups, fibrosis and steatosis, as well as normal cases. Computer-extracted texture features were then used to train a machine learning (ML) model for computer-aided diagnosis. The experiment resulted in high two-category diagnosis using logistic regression, with AUC of 0.928 and high performance of multicategory classification, using random forest ML, with AUC of 0.917. To evaluate the image region independence for machine learning, Jenson–Shannon (JS) divergence was used. JS distributions showed that images of normal liver were independent from each other, while the images from the two disease pathologies were not independent. To guarantee the generalizability of machine learning models, and to prevent data leakage, multiple frames of image data acquired of the same object should be tested for independence before machine learning. Such tests can be applied to real-world medical image problems to determine if images from the same subject can be used for training.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
