{"title":"Unsupervised learning of style-aware facial animation from real acting performances","authors":"Wolfgang Paier , Anna Hilsmann , Peter Eisert","doi":"10.1016/j.gmod.2023.101199","DOIUrl":null,"url":null,"abstract":"<div><p>This paper presents a novel approach for text/speech-driven animation of a photo-realistic head model based on blend-shape geometry, dynamic textures, and neural rendering. Training a VAE for geometry and texture yields a parametric model for accurate capturing and realistic synthesis of facial expressions from a latent feature vector. Our animation method is based on a conditional CNN that transforms text or speech into a sequence of animation parameters. In contrast to previous approaches, our animation model learns disentangling/synthesizing different acting-styles in an unsupervised manner, requiring only phonetic labels that describe the content of training sequences. For realistic real-time rendering, we train a U-Net that refines rasterization-based renderings by computing improved pixel colors and a foreground matte. We compare our framework qualitatively/quantitatively against recent methods for head modeling as well as facial animation and evaluate the perceived rendering/animation quality in a user-study, which indicates large improvements compared to state-of-the-art approaches.</p></div>","PeriodicalId":55083,"journal":{"name":"Graphical Models","volume":"129 ","pages":"Article 101199"},"PeriodicalIF":2.2000,"publicationDate":"2023-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Graphical Models","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1524070323000292","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/9/8 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
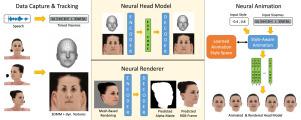
This paper presents a novel approach for text/speech-driven animation of a photo-realistic head model based on blend-shape geometry, dynamic textures, and neural rendering. Training a VAE for geometry and texture yields a parametric model for accurate capturing and realistic synthesis of facial expressions from a latent feature vector. Our animation method is based on a conditional CNN that transforms text or speech into a sequence of animation parameters. In contrast to previous approaches, our animation model learns disentangling/synthesizing different acting-styles in an unsupervised manner, requiring only phonetic labels that describe the content of training sequences. For realistic real-time rendering, we train a U-Net that refines rasterization-based renderings by computing improved pixel colors and a foreground matte. We compare our framework qualitatively/quantitatively against recent methods for head modeling as well as facial animation and evaluate the perceived rendering/animation quality in a user-study, which indicates large improvements compared to state-of-the-art approaches.
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
