{"title":"Deep reinforcement learning-based routing and resource assignment in quantum key distribution-secured optical networks","authors":"Purva Sharma, Shubham Gupta, Vimal Bhatia, Shashi Prakash","doi":"10.1049/qtc2.12063","DOIUrl":null,"url":null,"abstract":"<p>In quantum key distribution-secured optical networks (QKD-ONs), constrained network resources limit the success probability of QKD lightpath requests (QLRs). Thus, the selection of an appropriate route and the efficient utilisation of network resources for establishment of QLRs are the essential and challenging problems. This work addresses the routing and resource assignment (RRA) problem in the quantum signal channel of QKD-ONs. The RRA problem of QKD-ONs is a complex decision making problem, where appropriate solutions depend on understanding the networking environment. Motivated by the recent advances in deep reinforcement learning (DRL) for complex problems and also because of its capability to learn directly from experiences, DRL is exploited to solve the RRA problem and a DRL-based RRA scheme is proposed. The proposed scheme learns the optimal policy to select an appropriate route and assigns suitable network resources for establishment of QLRs by using deep neural networks. The performance of the proposed scheme is compared with the deep-Q network (DQN) method and two baseline schemes, namely, first-fit (FF) and random-fit (RF) for two different networks, namely The National Science Foundation Network (NSFNET) and UBN24. Simulation results indicate that the proposed scheme reduces blocking by 7.19%, 10.11%, and 33.50% for NSFNET and 2.47%, 3.20%, and 19.60% for UBN24 and improves resource utilisation up to 3.40%, 4.33%, and 7.18% for NSFNET and 1.34%, 1.96%, and 6.44% for UBN24 as compared with DQN, FF, and RF, respectively.</p>","PeriodicalId":100651,"journal":{"name":"IET Quantum Communication","volume":"4 3","pages":"136-145"},"PeriodicalIF":2.8000,"publicationDate":"2023-06-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/qtc2.12063","citationCount":"1","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Quantum Communication","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1049/qtc2.12063","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"QUANTUM SCIENCE & TECHNOLOGY","Score":null,"Total":0}
引用次数: 1
Abstract
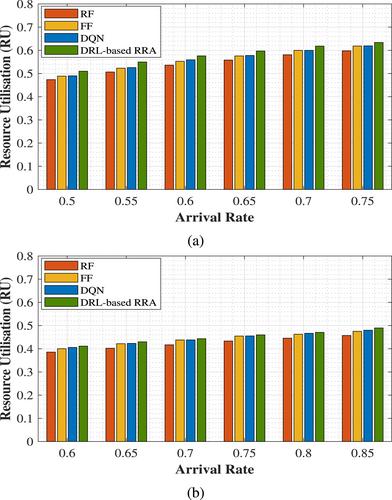
In quantum key distribution-secured optical networks (QKD-ONs), constrained network resources limit the success probability of QKD lightpath requests (QLRs). Thus, the selection of an appropriate route and the efficient utilisation of network resources for establishment of QLRs are the essential and challenging problems. This work addresses the routing and resource assignment (RRA) problem in the quantum signal channel of QKD-ONs. The RRA problem of QKD-ONs is a complex decision making problem, where appropriate solutions depend on understanding the networking environment. Motivated by the recent advances in deep reinforcement learning (DRL) for complex problems and also because of its capability to learn directly from experiences, DRL is exploited to solve the RRA problem and a DRL-based RRA scheme is proposed. The proposed scheme learns the optimal policy to select an appropriate route and assigns suitable network resources for establishment of QLRs by using deep neural networks. The performance of the proposed scheme is compared with the deep-Q network (DQN) method and two baseline schemes, namely, first-fit (FF) and random-fit (RF) for two different networks, namely The National Science Foundation Network (NSFNET) and UBN24. Simulation results indicate that the proposed scheme reduces blocking by 7.19%, 10.11%, and 33.50% for NSFNET and 2.47%, 3.20%, and 19.60% for UBN24 and improves resource utilisation up to 3.40%, 4.33%, and 7.18% for NSFNET and 1.34%, 1.96%, and 6.44% for UBN24 as compared with DQN, FF, and RF, respectively.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
