Mioara A Nicolaie, Koen Füssenich, Caroline Ameling, Hendriek C Boshuizen
{"title":"Constructing synthetic populations in the age of big data.","authors":"Mioara A Nicolaie, Koen Füssenich, Caroline Ameling, Hendriek C Boshuizen","doi":"10.1186/s12963-023-00319-5","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>To develop public health intervention models using micro-simulations, extensive personal information about inhabitants is needed, such as socio-demographic, economic and health figures. Confidentiality is an essential characteristic of such data, while the data should reflect realistic scenarios. Collection of such data is possible only in secured environments and not directly available for open-source micro-simulation models. The aim of this paper is to illustrate a method of construction of synthetic data by predicting individual features through models based on confidential data on health and socio-economic determinants of the entire Dutch population.</p><p><strong>Methods: </strong>Administrative records and health registry data were linked to socio-economic characteristics and self-reported lifestyle factors. For the entire Dutch population (n = 16,778,708), all socio-demographic information except lifestyle factors was available. Lifestyle factors were available from the 2012 Dutch Health Monitor (n = 370,835). Regression model was used to sequentially predict individual features.</p><p><strong>Results: </strong>The synthetic population resembles the original confidential population. Features predicted in the first stages of the sequential procedure are virtually similar to those in the original population, while those predicted in later stages of the sequential procedure carry the accumulation of limitations furthered by data quality and previously modelled features.</p><p><strong>Conclusions: </strong>By combining socio-demographic, economic, health and lifestyle related data at individual level on a large scale, our method provides us with a powerful tool to construct a synthetic population of good quality and with no confidentiality issues.</p>","PeriodicalId":51476,"journal":{"name":"Population Health Metrics","volume":"21 1","pages":"19"},"PeriodicalIF":2.5000,"publicationDate":"2023-10-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10617102/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Population Health Metrics","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1186/s12963-023-00319-5","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"PUBLIC, ENVIRONMENTAL & OCCUPATIONAL HEALTH","Score":null,"Total":0}
引用次数: 0
Abstract
Background: To develop public health intervention models using micro-simulations, extensive personal information about inhabitants is needed, such as socio-demographic, economic and health figures. Confidentiality is an essential characteristic of such data, while the data should reflect realistic scenarios. Collection of such data is possible only in secured environments and not directly available for open-source micro-simulation models. The aim of this paper is to illustrate a method of construction of synthetic data by predicting individual features through models based on confidential data on health and socio-economic determinants of the entire Dutch population.
Methods: Administrative records and health registry data were linked to socio-economic characteristics and self-reported lifestyle factors. For the entire Dutch population (n = 16,778,708), all socio-demographic information except lifestyle factors was available. Lifestyle factors were available from the 2012 Dutch Health Monitor (n = 370,835). Regression model was used to sequentially predict individual features.
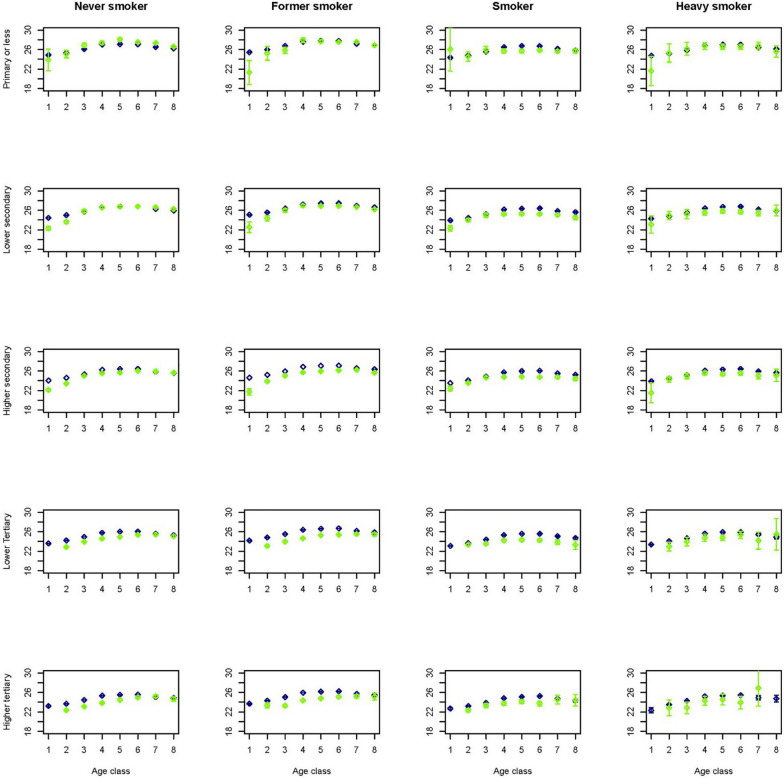
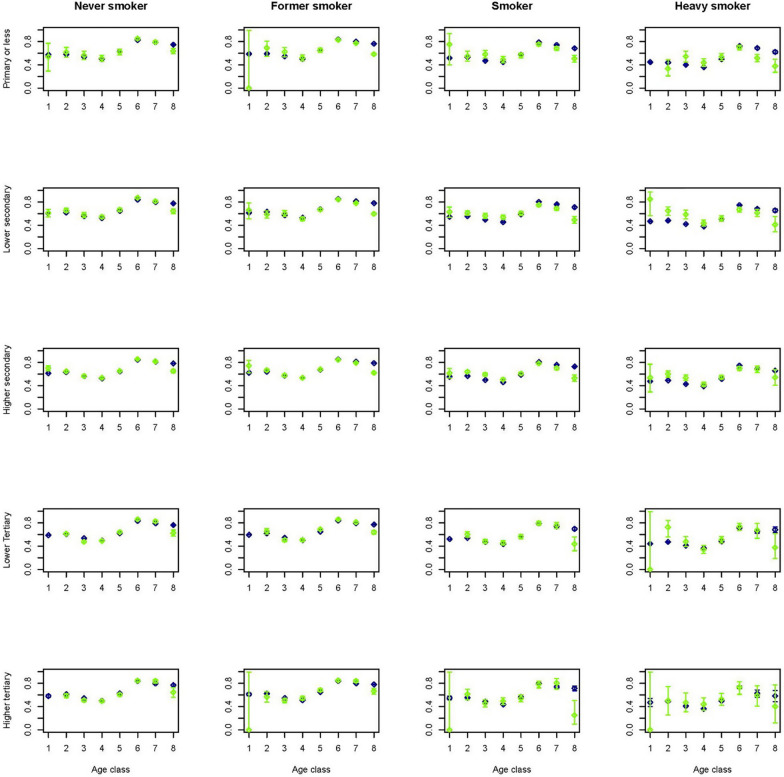
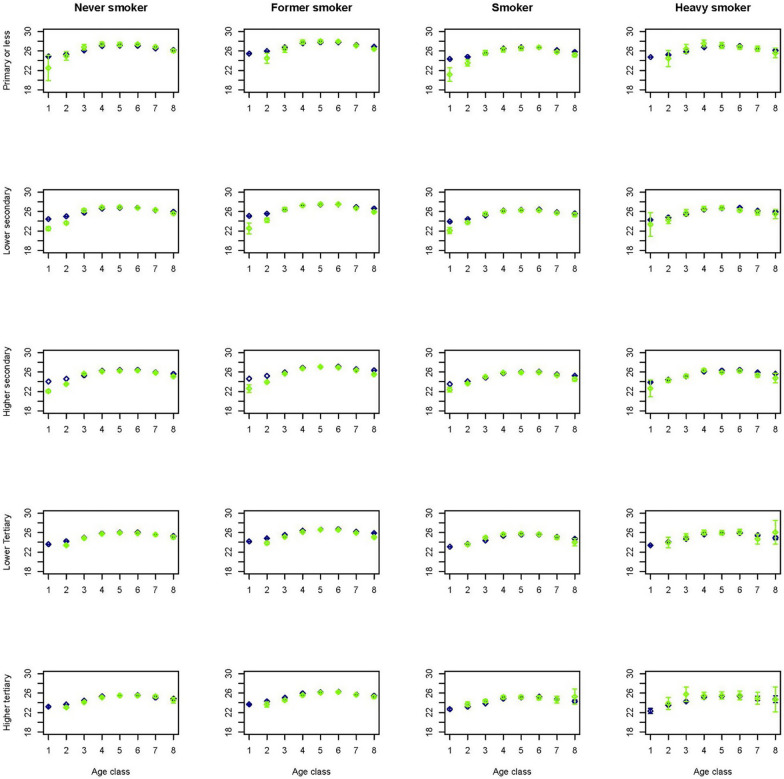
Results: The synthetic population resembles the original confidential population. Features predicted in the first stages of the sequential procedure are virtually similar to those in the original population, while those predicted in later stages of the sequential procedure carry the accumulation of limitations furthered by data quality and previously modelled features.
Conclusions: By combining socio-demographic, economic, health and lifestyle related data at individual level on a large scale, our method provides us with a powerful tool to construct a synthetic population of good quality and with no confidentiality issues.
期刊介绍:
Population Health Metrics aims to advance the science of population health assessment, and welcomes papers relating to concepts, methods, ethics, applications, and summary measures of population health. The journal provides a unique platform for population health researchers to share their findings with the global community. We seek research that addresses the communication of population health measures and policy implications to stakeholders; this includes papers related to burden estimation and risk assessment, and research addressing population health across the full range of development. Population Health Metrics covers a broad range of topics encompassing health state measurement and valuation, summary measures of population health, descriptive epidemiology at the population level, burden of disease and injury analysis, disease and risk factor modeling for populations, and comparative assessment of risks to health at the population level. The journal is also interested in how to use and communicate indicators of population health to reduce disease burden, and the approaches for translating from indicators of population health to health-advancing actions. As a cross-cutting topic of importance, we are particularly interested in inequalities in population health and their measurement.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
