{"title":"Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model","authors":"Hongrui Cai, Yudong Guo, Zhuang Peng, Juyong Zhang","doi":"10.1016/j.gmod.2021.101103","DOIUrl":null,"url":null,"abstract":"<div><p><span><span>Caricature is an artistic abstraction of the human face by distorting or exaggerating certain facial features, while still retains a likeness with the given face. Due to the large diversity of geometric and texture variations, automatic landmark detection and 3D face reconstruction for caricature is a challenging problem and has rarely been studied before. In this paper, we propose the first automatic method for this task by a novel 3D approach. To this end, we first build a dataset with various styles of 2D caricatures and their corresponding </span>3D shapes<span><span>, and then build a parametric model on vertex based deformation space for 3D caricature face. Based on the constructed dataset and the nonlinear parametric model, we propose a </span>neural network<span> based method to regress the 3D face shape and orientation from the input 2D caricature image. Ablation studies and comparison with state-of-the-art methods demonstrate the effectiveness of our algorithm design. Extensive experimental results demonstrate that our method works well for various caricatures. Our constructed dataset, source code and trained model are available at </span></span></span><span>https://github.com/Juyong/CaricatureFace</span><svg><path></path></svg>.</p></div>","PeriodicalId":55083,"journal":{"name":"Graphical Models","volume":"115 ","pages":"Article 101103"},"PeriodicalIF":2.2000,"publicationDate":"2021-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1016/j.gmod.2021.101103","citationCount":"23","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Graphical Models","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1524070321000084","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/4/6 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 23
Abstract
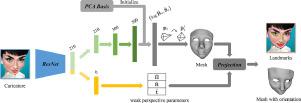
Caricature is an artistic abstraction of the human face by distorting or exaggerating certain facial features, while still retains a likeness with the given face. Due to the large diversity of geometric and texture variations, automatic landmark detection and 3D face reconstruction for caricature is a challenging problem and has rarely been studied before. In this paper, we propose the first automatic method for this task by a novel 3D approach. To this end, we first build a dataset with various styles of 2D caricatures and their corresponding 3D shapes, and then build a parametric model on vertex based deformation space for 3D caricature face. Based on the constructed dataset and the nonlinear parametric model, we propose a neural network based method to regress the 3D face shape and orientation from the input 2D caricature image. Ablation studies and comparison with state-of-the-art methods demonstrate the effectiveness of our algorithm design. Extensive experimental results demonstrate that our method works well for various caricatures. Our constructed dataset, source code and trained model are available at https://github.com/Juyong/CaricatureFace.
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
