{"title":"Vertex position estimation with spatial–temporal transformer for 3D human reconstruction","authors":"Xiangjun Zhang, Yinglin Zheng, Wenjin Deng, Qifeng Dai, Yuxin Lin, Wangzheng Shi, Ming Zeng","doi":"10.1016/j.gmod.2023.101207","DOIUrl":null,"url":null,"abstract":"<div><p>Reconstructing 3D human pose and body shape from monocular images or videos is a fundamental task for comprehending human dynamics. Frame-based methods can be broadly categorized into two fashions: those regressing parametric model parameters (e.g., SMPL) and those exploring alternative representations (e.g., volumetric shapes, 3D coordinates). Non-parametric representations have demonstrated superior performance due to their enhanced flexibility. However, when applied to video data, these non-parametric frame-based methods tend to generate inconsistent and unsmooth results. To this end, we present a novel approach that directly regresses the 3D coordinates of the mesh vertices and body joints with a spatial–temporal Transformer. In our method, we introduce a SpatioTemporal Learning Block (STLB) with Spatial Learning Module (SLM) and Temporal Learning Module (TLM), which leverages spatial and temporal information to model interactions at a finer granularity, specifically at the body token level. Our method outperforms previous state-of-the-art approaches on Human3.6M and 3DPW benchmark datasets.</p></div>","PeriodicalId":55083,"journal":{"name":"Graphical Models","volume":"130 ","pages":"Article 101207"},"PeriodicalIF":2.2000,"publicationDate":"2023-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1524070323000371/pdfft?md5=a920877b3ee3210b23f7a6444d151f50&pid=1-s2.0-S1524070323000371-main.pdf","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Graphical Models","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1524070323000371","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/10/26 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
Abstract
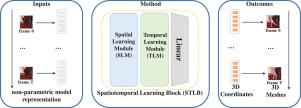
Reconstructing 3D human pose and body shape from monocular images or videos is a fundamental task for comprehending human dynamics. Frame-based methods can be broadly categorized into two fashions: those regressing parametric model parameters (e.g., SMPL) and those exploring alternative representations (e.g., volumetric shapes, 3D coordinates). Non-parametric representations have demonstrated superior performance due to their enhanced flexibility. However, when applied to video data, these non-parametric frame-based methods tend to generate inconsistent and unsmooth results. To this end, we present a novel approach that directly regresses the 3D coordinates of the mesh vertices and body joints with a spatial–temporal Transformer. In our method, we introduce a SpatioTemporal Learning Block (STLB) with Spatial Learning Module (SLM) and Temporal Learning Module (TLM), which leverages spatial and temporal information to model interactions at a finer granularity, specifically at the body token level. Our method outperforms previous state-of-the-art approaches on Human3.6M and 3DPW benchmark datasets.
期刊介绍:
Graphical Models is recognized internationally as a highly rated, top tier journal and is focused on the creation, geometric processing, animation, and visualization of graphical models and on their applications in engineering, science, culture, and entertainment. GMOD provides its readers with thoroughly reviewed and carefully selected papers that disseminate exciting innovations, that teach rigorous theoretical foundations, that propose robust and efficient solutions, or that describe ambitious systems or applications in a variety of topics.
We invite papers in five categories: research (contributions of novel theoretical or practical approaches or solutions), survey (opinionated views of the state-of-the-art and challenges in a specific topic), system (the architecture and implementation details of an innovative architecture for a complete system that supports model/animation design, acquisition, analysis, visualization?), application (description of a novel application of know techniques and evaluation of its impact), or lecture (an elegant and inspiring perspective on previously published results that clarifies them and teaches them in a new way).
GMOD offers its authors an accelerated review, feedback from experts in the field, immediate online publication of accepted papers, no restriction on color and length (when justified by the content) in the online version, and a broad promotion of published papers. A prestigious group of editors selected from among the premier international researchers in their fields oversees the review process.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
