{"title":"Reference-free phylogeny from sequencing data.","authors":"Petr Ryšavý, Filip Železný","doi":"10.1186/s13040-023-00329-x","DOIUrl":null,"url":null,"abstract":"<p><strong>Motivation: </strong>Clustering of genetic sequences is one of the key parts of bioinformatics analyses. Resulting phylogenetic trees are beneficial for solving many research questions, including tracing the history of species, studying migration in the past, or tracing a source of a virus outbreak. At the same time, biologists provide more data in the raw form of reads or only on contig-level assembly. Therefore, tools that are able to process those data without supervision need to be developed.</p><p><strong>Results: </strong>In this paper, we present a tool for reference-free phylogeny capable of handling data where no mature-level assembly is available. The tool allows distance calculation for raw reads, contigs, and the combination of the latter. The tool provides an estimation of the Levenshtein distance between the sequences, which in turn estimates the number of mutations between the organisms. Compared to the previous research, the novelty of the method lies in a newly proposed combination of the read and contig measures, a new method for read-contig mapping, and an efficient embedding of contigs.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"13"},"PeriodicalIF":6.1000,"publicationDate":"2023-03-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10045052/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00329-x","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
Motivation: Clustering of genetic sequences is one of the key parts of bioinformatics analyses. Resulting phylogenetic trees are beneficial for solving many research questions, including tracing the history of species, studying migration in the past, or tracing a source of a virus outbreak. At the same time, biologists provide more data in the raw form of reads or only on contig-level assembly. Therefore, tools that are able to process those data without supervision need to be developed.
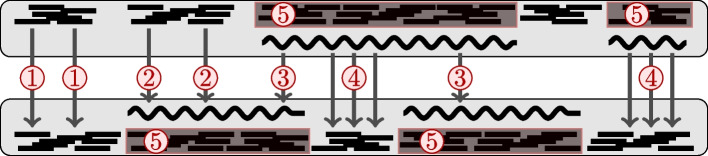
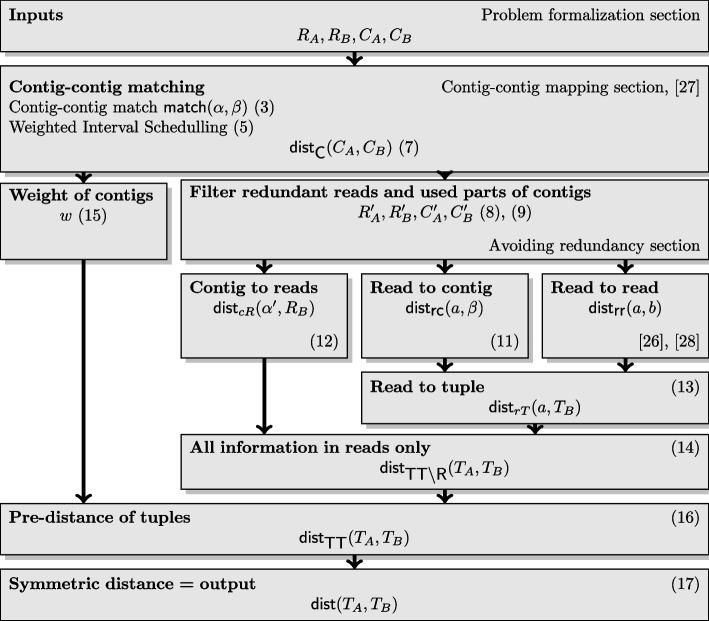
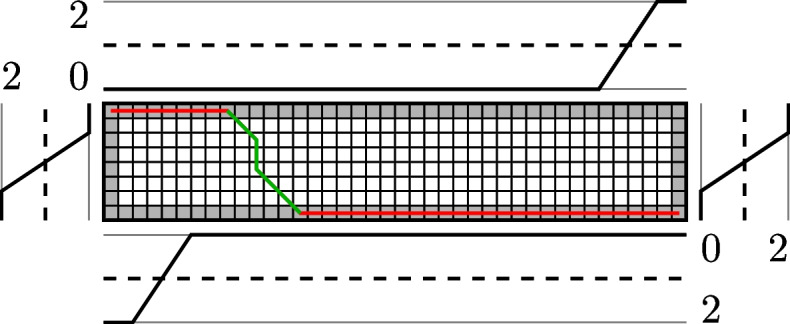
Results: In this paper, we present a tool for reference-free phylogeny capable of handling data where no mature-level assembly is available. The tool allows distance calculation for raw reads, contigs, and the combination of the latter. The tool provides an estimation of the Levenshtein distance between the sequences, which in turn estimates the number of mutations between the organisms. Compared to the previous research, the novelty of the method lies in a newly proposed combination of the read and contig measures, a new method for read-contig mapping, and an efficient embedding of contigs.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
