Anoop Sathyan, Abraham Itzhak Weinberg, Kelly Cohen
{"title":"Interpretable AI for bio-medical applications.","authors":"Anoop Sathyan, Abraham Itzhak Weinberg, Kelly Cohen","doi":"10.20517/ces.2022.41","DOIUrl":null,"url":null,"abstract":"<p><p>This paper presents the use of two popular explainability tools called Local Interpretable Model-Agnostic Explanations (LIME) and Shapley Additive exPlanations (SHAP) to explain the predictions made by a trained deep neural network. The deep neural network used in this work is trained on the UCI Breast Cancer Wisconsin dataset. The neural network is used to classify the masses found in patients as benign or malignant based on 30 features that describe the mass. LIME and SHAP are then used to explain the individual predictions made by the trained neural network model. The explanations provide further insights into the relationship between the input features and the predictions. SHAP methodology additionally provides a more holistic view of the effect of the inputs on the output predictions. The results also present the commonalities between the insights gained using LIME and SHAP. Although this paper focuses on the use of deep neural networks trained on UCI Breast Cancer Wisconsin dataset, the methodology can be applied to other neural networks and architectures trained on other applications. The deep neural network trained in this work provides a high level of accuracy. Analyzing the model using LIME and SHAP adds the much desired benefit of providing explanations for the recommendations made by the trained model.</p>","PeriodicalId":72652,"journal":{"name":"Complex engineering systems (Alhambra, Calif.)","volume":"2 4","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2022-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10074303/pdf/","citationCount":"4","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Complex engineering systems (Alhambra, Calif.)","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.20517/ces.2022.41","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 4
Abstract
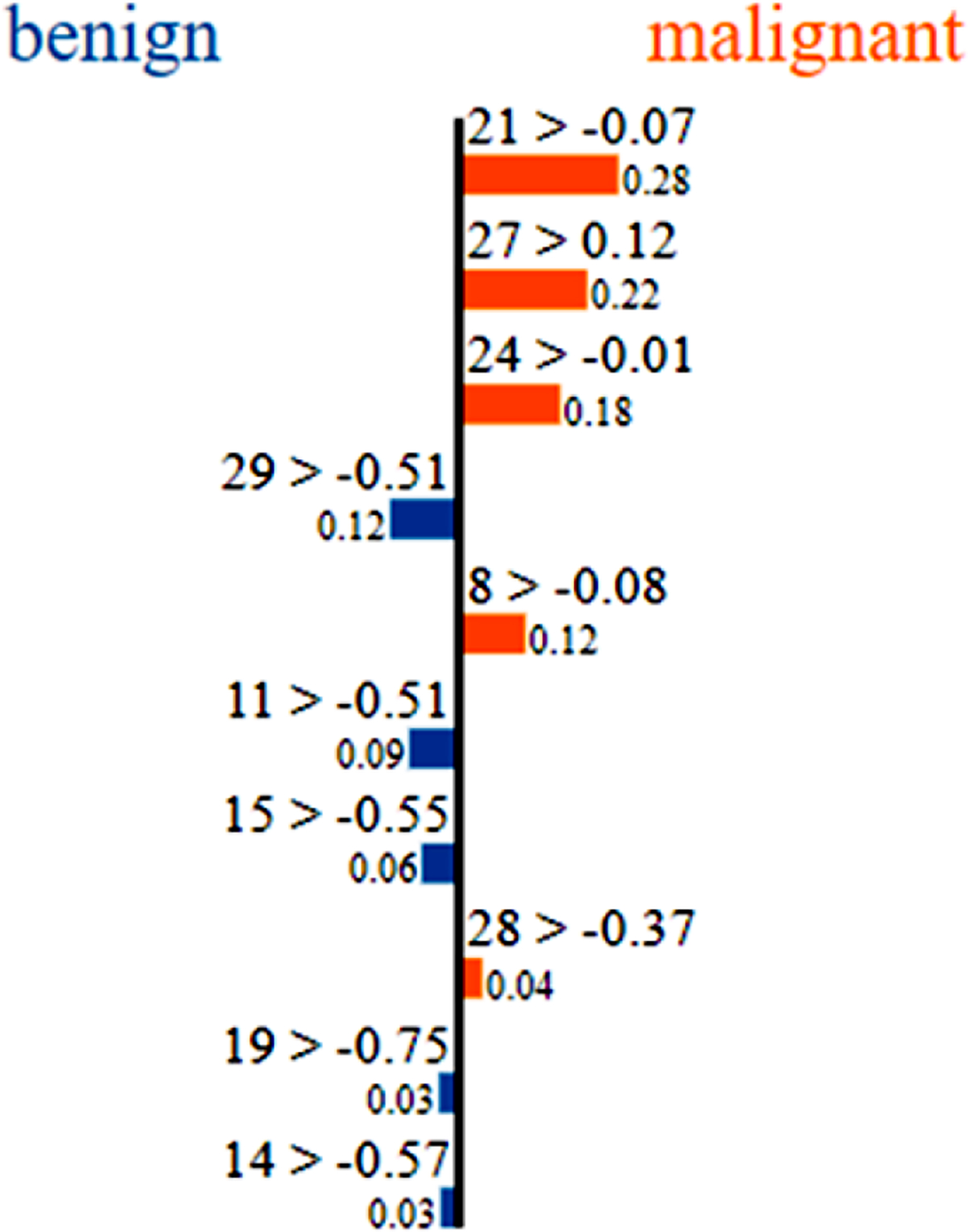
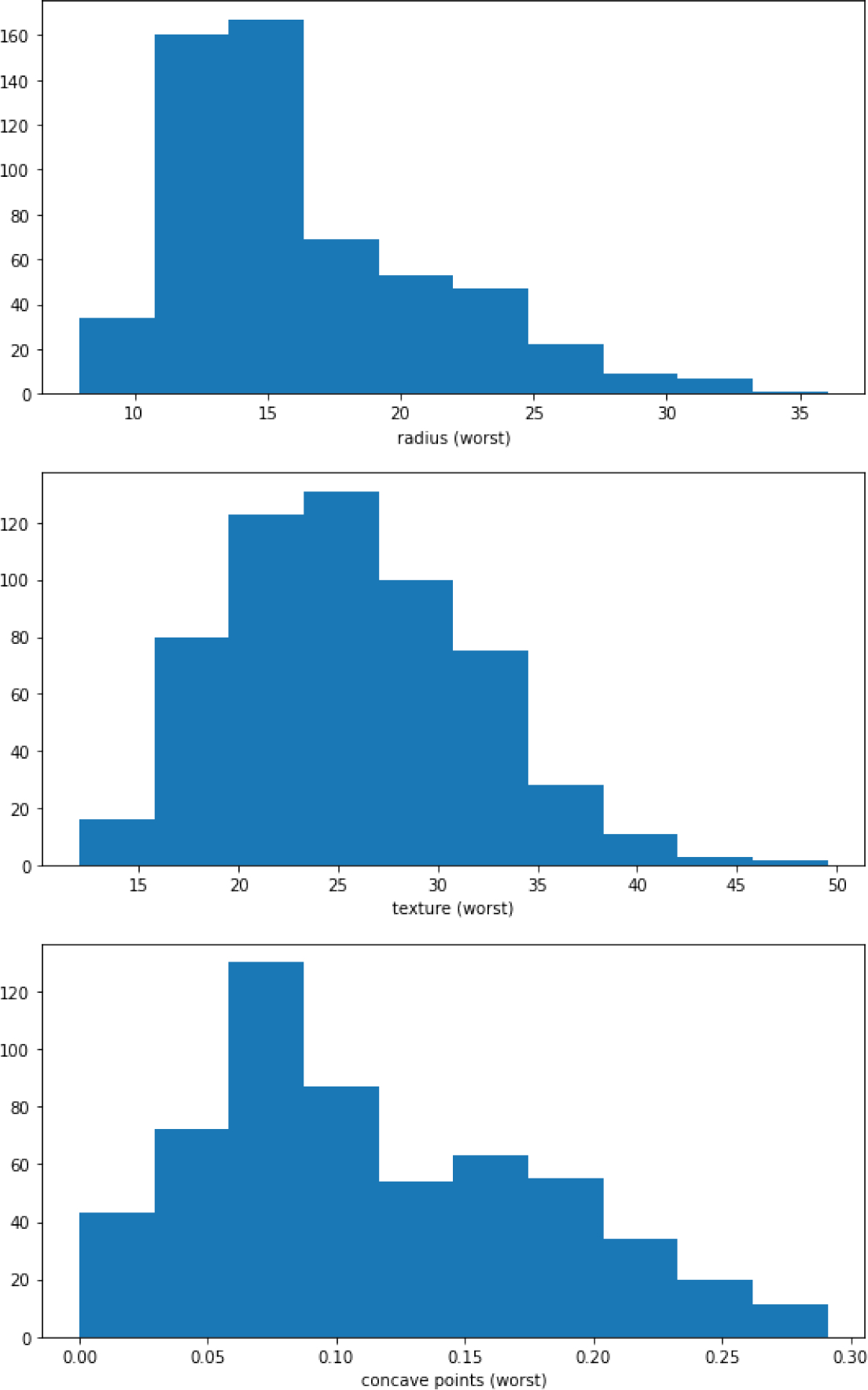
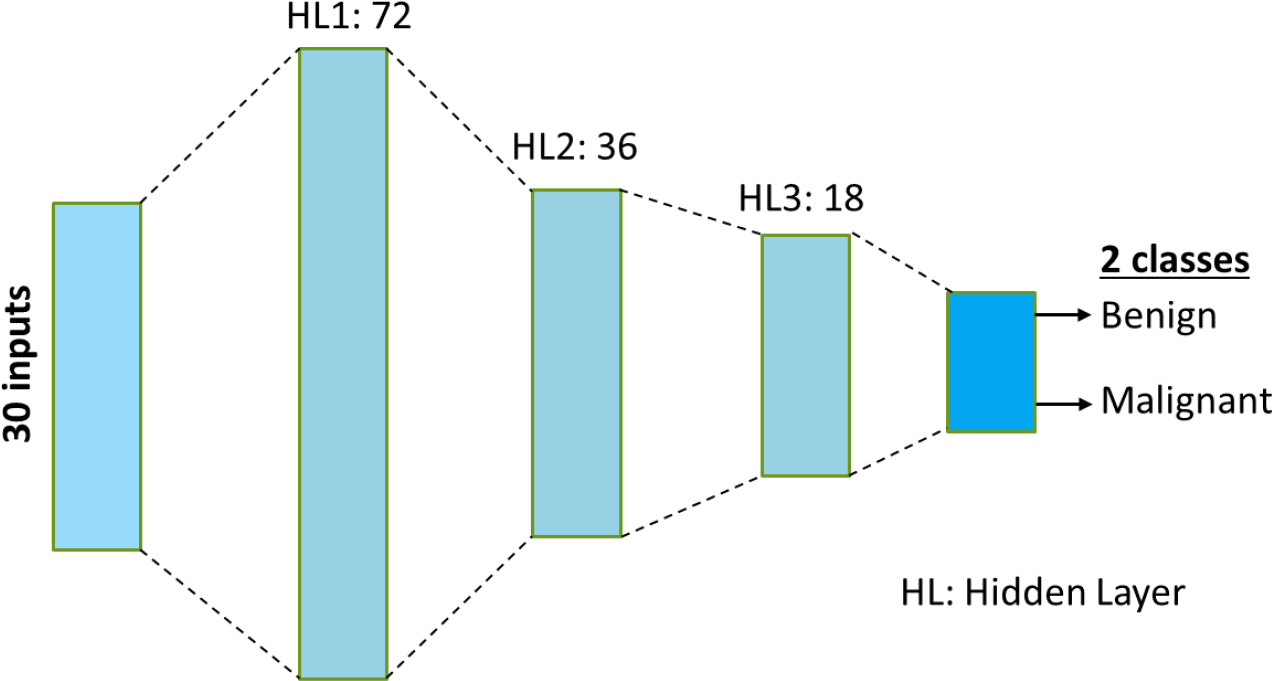
This paper presents the use of two popular explainability tools called Local Interpretable Model-Agnostic Explanations (LIME) and Shapley Additive exPlanations (SHAP) to explain the predictions made by a trained deep neural network. The deep neural network used in this work is trained on the UCI Breast Cancer Wisconsin dataset. The neural network is used to classify the masses found in patients as benign or malignant based on 30 features that describe the mass. LIME and SHAP are then used to explain the individual predictions made by the trained neural network model. The explanations provide further insights into the relationship between the input features and the predictions. SHAP methodology additionally provides a more holistic view of the effect of the inputs on the output predictions. The results also present the commonalities between the insights gained using LIME and SHAP. Although this paper focuses on the use of deep neural networks trained on UCI Breast Cancer Wisconsin dataset, the methodology can be applied to other neural networks and architectures trained on other applications. The deep neural network trained in this work provides a high level of accuracy. Analyzing the model using LIME and SHAP adds the much desired benefit of providing explanations for the recommendations made by the trained model.


 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
