{"title":"Inverse problem for parameters identification in a modified SIRD epidemic model using ensemble neural networks.","authors":"Marian Petrica, Ionel Popescu","doi":"10.1186/s13040-023-00337-x","DOIUrl":null,"url":null,"abstract":"<p><p>In this paper, we propose a parameter identification methodology of the SIRD model, an extension of the classical SIR model, that considers the deceased as a separate category. In addition, our model includes one parameter which is the ratio between the real total number of infected and the number of infected that were documented in the official statistics. Due to many factors, like governmental decisions, several variants circulating, opening and closing of schools, the typical assumption that the parameters of the model stay constant for long periods of time is not realistic. Thus our objective is to create a method which works for short periods of time. In this scope, we approach the estimation relying on the previous 7 days of data and then use the identified parameters to make predictions. To perform the estimation of the parameters we propose the average of an ensemble of neural networks. Each neural network is constructed based on a database built by solving the SIRD for 7 days, with random parameters. In this way, the networks learn the parameters from the solution of the SIRD model. Lastly we use the ensemble to get estimates of the parameters from the real data of Covid19 in Romania and then we illustrate the predictions for different periods of time, from 10 up to 45 days, for the number of deaths. The main goal was to apply this approach on the analysis of COVID-19 evolution in Romania, but this was also exemplified on other countries like Hungary, Czech Republic and Poland with similar results. The results are backed by a theorem which guarantees that we can recover the parameters of the model from the reported data. We believe this methodology can be used as a general tool for dealing with short term predictions of infectious diseases or in other compartmental models.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"22"},"PeriodicalIF":6.1000,"publicationDate":"2023-07-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10354917/pdf/","citationCount":"0","resultStr":null,"platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00337-x","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
Abstract
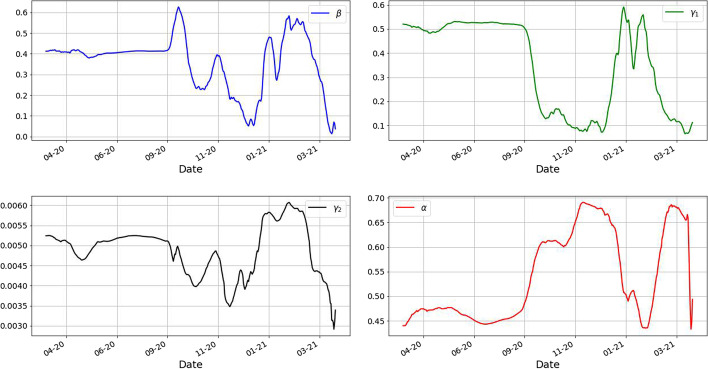
In this paper, we propose a parameter identification methodology of the SIRD model, an extension of the classical SIR model, that considers the deceased as a separate category. In addition, our model includes one parameter which is the ratio between the real total number of infected and the number of infected that were documented in the official statistics. Due to many factors, like governmental decisions, several variants circulating, opening and closing of schools, the typical assumption that the parameters of the model stay constant for long periods of time is not realistic. Thus our objective is to create a method which works for short periods of time. In this scope, we approach the estimation relying on the previous 7 days of data and then use the identified parameters to make predictions. To perform the estimation of the parameters we propose the average of an ensemble of neural networks. Each neural network is constructed based on a database built by solving the SIRD for 7 days, with random parameters. In this way, the networks learn the parameters from the solution of the SIRD model. Lastly we use the ensemble to get estimates of the parameters from the real data of Covid19 in Romania and then we illustrate the predictions for different periods of time, from 10 up to 45 days, for the number of deaths. The main goal was to apply this approach on the analysis of COVID-19 evolution in Romania, but this was also exemplified on other countries like Hungary, Czech Republic and Poland with similar results. The results are backed by a theorem which guarantees that we can recover the parameters of the model from the reported data. We believe this methodology can be used as a general tool for dealing with short term predictions of infectious diseases or in other compartmental models.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.





 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
