Yikuan Li, Gholamreza Salimi-Khorshidi, Shishir Rao, Dexter Canoy, Abdelaali Hassaine, Thomas Lukasiewicz, Kazem Rahimi, Mohammad Mamouei
{"title":"验证应用于纵向电子健康记录数据的风险预测模型,以预测存在数据变化的主要心血管事件。","authors":"Yikuan Li, Gholamreza Salimi-Khorshidi, Shishir Rao, Dexter Canoy, Abdelaali Hassaine, Thomas Lukasiewicz, Kazem Rahimi, Mohammad Mamouei","doi":"10.1093/ehjdh/ztac061","DOIUrl":null,"url":null,"abstract":"<p><strong>Aims: </strong>Deep learning has dominated predictive modelling across different fields, but in medicine it has been met with mixed reception. In clinical practice, simple, statistical models and risk scores continue to inform cardiovascular disease risk predictions. This is due in part to the knowledge gap about how deep learning models perform in practice when they are subject to dynamic data shifts; a key criterion that common internal validation procedures do not address. We evaluated the performance of a novel deep learning model, BEHRT, under data shifts and compared it with several ML-based and established risk models.</p><p><strong>Methods and results: </strong>Using linked electronic health records of 1.1 million patients across England aged at least 35 years between 1985 and 2015, we replicated three established statistical models for predicting 5-year risk of incident heart failure, stroke, and coronary heart disease. The results were compared with a widely accepted machine learning model (random forests), and a novel deep learning model (BEHRT). In addition to internal validation, we investigated how data shifts affect model discrimination and calibration. To this end, we tested the models on cohorts from (i) distinct geographical regions; (ii) different periods. Using internal validation, the deep learning models substantially outperformed the best statistical models by 6%, 8%, and 11% in heart failure, stroke, and coronary heart disease, respectively, in terms of the area under the receiver operating characteristic curve.</p><p><strong>Conclusion: </strong>The performance of all models declined as a result of data shifts; despite this, the deep learning models maintained the best performance in all risk prediction tasks. Updating the model with the latest information can improve discrimination but if the prior distribution changes, the model may remain miscalibrated.</p>","PeriodicalId":72965,"journal":{"name":"European heart journal. Digital health","volume":"3 4","pages":"535-547"},"PeriodicalIF":4.4000,"publicationDate":"2022-10-21","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9779795/pdf/","citationCount":"0","resultStr":"{\"title\":\"Validation of risk prediction models applied to longitudinal electronic health record data for the prediction of major cardiovascular events in the presence of data shifts.\",\"authors\":\"Yikuan Li, Gholamreza Salimi-Khorshidi, Shishir Rao, Dexter Canoy, Abdelaali Hassaine, Thomas Lukasiewicz, Kazem Rahimi, Mohammad Mamouei\",\"doi\":\"10.1093/ehjdh/ztac061\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Aims: </strong>Deep learning has dominated predictive modelling across different fields, but in medicine it has been met with mixed reception. In clinical practice, simple, statistical models and risk scores continue to inform cardiovascular disease risk predictions. This is due in part to the knowledge gap about how deep learning models perform in practice when they are subject to dynamic data shifts; a key criterion that common internal validation procedures do not address. We evaluated the performance of a novel deep learning model, BEHRT, under data shifts and compared it with several ML-based and established risk models.</p><p><strong>Methods and results: </strong>Using linked electronic health records of 1.1 million patients across England aged at least 35 years between 1985 and 2015, we replicated three established statistical models for predicting 5-year risk of incident heart failure, stroke, and coronary heart disease. The results were compared with a widely accepted machine learning model (random forests), and a novel deep learning model (BEHRT). In addition to internal validation, we investigated how data shifts affect model discrimination and calibration. To this end, we tested the models on cohorts from (i) distinct geographical regions; (ii) different periods. Using internal validation, the deep learning models substantially outperformed the best statistical models by 6%, 8%, and 11% in heart failure, stroke, and coronary heart disease, respectively, in terms of the area under the receiver operating characteristic curve.</p><p><strong>Conclusion: </strong>The performance of all models declined as a result of data shifts; despite this, the deep learning models maintained the best performance in all risk prediction tasks. Updating the model with the latest information can improve discrimination but if the prior distribution changes, the model may remain miscalibrated.</p>\",\"PeriodicalId\":72965,\"journal\":{\"name\":\"European heart journal. Digital health\",\"volume\":\"3 4\",\"pages\":\"535-547\"},\"PeriodicalIF\":4.4000,\"publicationDate\":\"2022-10-21\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9779795/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"European heart journal. Digital health\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1093/ehjdh/ztac061\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/12/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"CARDIAC & CARDIOVASCULAR SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"European heart journal. Digital health","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1093/ehjdh/ztac061","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/12/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"CARDIAC & CARDIOVASCULAR SYSTEMS","Score":null,"Total":0}
Validation of risk prediction models applied to longitudinal electronic health record data for the prediction of major cardiovascular events in the presence of data shifts.
Aims: Deep learning has dominated predictive modelling across different fields, but in medicine it has been met with mixed reception. In clinical practice, simple, statistical models and risk scores continue to inform cardiovascular disease risk predictions. This is due in part to the knowledge gap about how deep learning models perform in practice when they are subject to dynamic data shifts; a key criterion that common internal validation procedures do not address. We evaluated the performance of a novel deep learning model, BEHRT, under data shifts and compared it with several ML-based and established risk models.
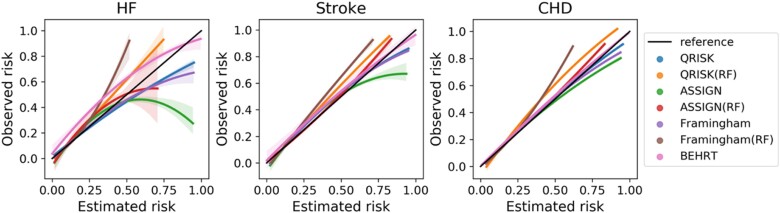
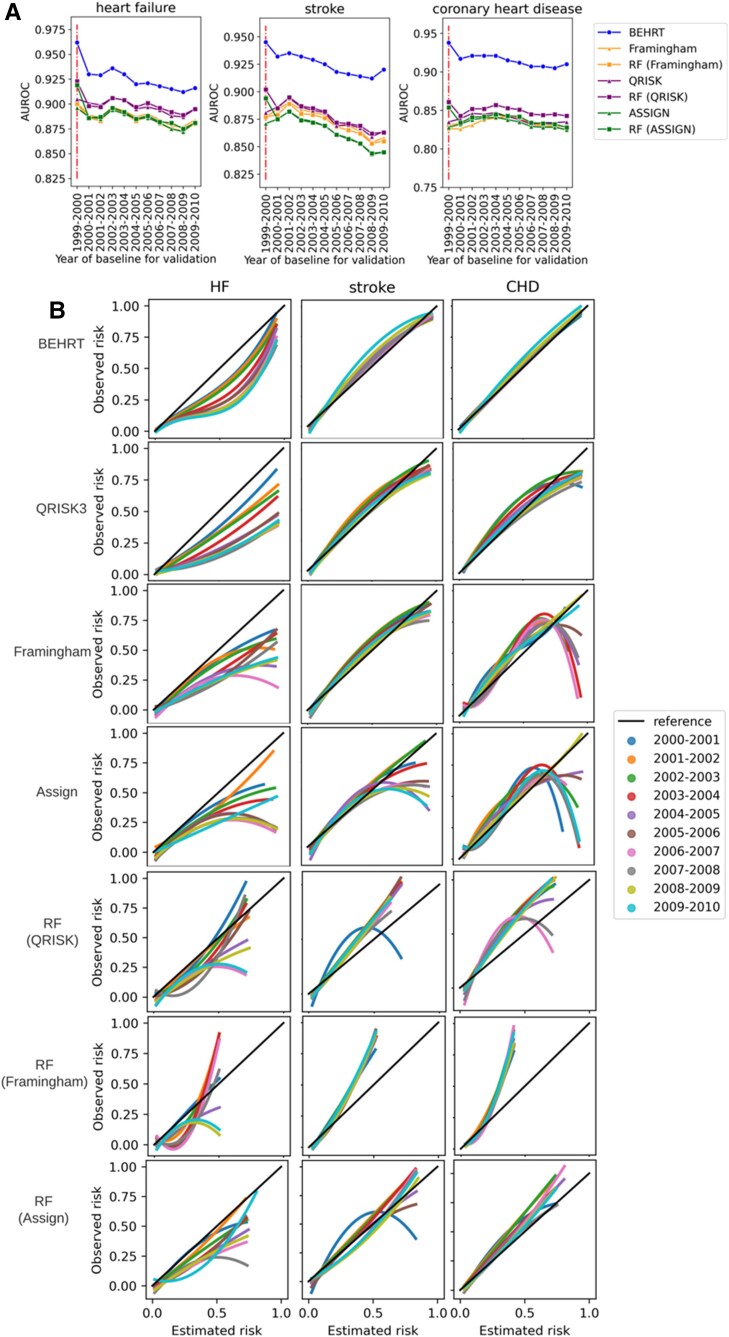
Methods and results: Using linked electronic health records of 1.1 million patients across England aged at least 35 years between 1985 and 2015, we replicated three established statistical models for predicting 5-year risk of incident heart failure, stroke, and coronary heart disease. The results were compared with a widely accepted machine learning model (random forests), and a novel deep learning model (BEHRT). In addition to internal validation, we investigated how data shifts affect model discrimination and calibration. To this end, we tested the models on cohorts from (i) distinct geographical regions; (ii) different periods. Using internal validation, the deep learning models substantially outperformed the best statistical models by 6%, 8%, and 11% in heart failure, stroke, and coronary heart disease, respectively, in terms of the area under the receiver operating characteristic curve.
Conclusion: The performance of all models declined as a result of data shifts; despite this, the deep learning models maintained the best performance in all risk prediction tasks. Updating the model with the latest information can improve discrimination but if the prior distribution changes, the model may remain miscalibrated.



 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
