Robert H. Dolin , Rohan Gupta , Kimberly Newsom , Bret S.E. Heale , Shailesh Gothi , Petr Starostik , Srikar Chamala
{"title":"用于简化基因组学EHR数据集成的自动化HL7v2 LRI信息学框架。","authors":"Robert H. Dolin , Rohan Gupta , Kimberly Newsom , Bret S.E. Heale , Shailesh Gothi , Petr Starostik , Srikar Chamala","doi":"10.1016/j.jpi.2023.100330","DOIUrl":null,"url":null,"abstract":"<div><p>While VCF formatted files are the lingua franca of next-generation sequencing, most EHRs do not provide native VCF support. As a result, labs often must send non-structured PDF reports to the EHR. On the other hand, while FHIR adoption is growing, most EHRs support HL7 interoperability standards, particularly those based on the HL7 Version 2 (HL7v2) standard. The HL7 Version 2 genomics component of the HL7 Laboratory Results Interface (HL7v2 LRI) standard specifies a formalism for the structured communication of genomic data from lab to EHR. We previously described an open-source tool (vcf2fhir) that converts VCF files into HL7 FHIR format. In this report, we describe how the utility has been extended to output HL7v2 LRI data that contains both variants and variant annotations (e.g., predicted phenotypes and therapeutic implications). Using this HL7v2 converter, we implemented an automated pipeline for moving structured genomic data from the clinical laboratory to EHR. We developed an open source hl7v2GenomicsExtractor that converts genomic interpretation report files into a series of HL7v2 observations conformant to HL7v2 LRI. We further enhanced the converter to produce output conformant to Epic's genomic import specification and to support alternative input formats. An automated pipeline for pushing standards-based structured genomic data directly into the EHR was successfully implemented, where genetic variant data and the clinical annotations are now both available to be viewed in the EHR through Epic's genomics module. Issues encountered in the development and deployment of the HL7v2 converter primarily revolved around data variability issues, primarily lack of a standardized representation of data elements within various genomic interpretation report files. The technical implementation of a HL7v2 message transformation to feed genomic variant and clinical annotation data into an EHR has been successful. In addition to genetic variant data, the implementation described here releases the valuable asset of clinically relevant genomic annotations provided by labs from static PDFs to calculable, structured data in EHR systems.</p></div>","PeriodicalId":37769,"journal":{"name":"Journal of Pathology Informatics","volume":"14 ","pages":"Article 100330"},"PeriodicalIF":0.0000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/08/9e/main.PMC10504540.pdf","citationCount":"0","resultStr":"{\"title\":\"Automated HL7v2 LRI informatics framework for streamlining genomics-EHR data integration\",\"authors\":\"Robert H. Dolin , Rohan Gupta , Kimberly Newsom , Bret S.E. Heale , Shailesh Gothi , Petr Starostik , Srikar Chamala\",\"doi\":\"10.1016/j.jpi.2023.100330\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>While VCF formatted files are the lingua franca of next-generation sequencing, most EHRs do not provide native VCF support. As a result, labs often must send non-structured PDF reports to the EHR. On the other hand, while FHIR adoption is growing, most EHRs support HL7 interoperability standards, particularly those based on the HL7 Version 2 (HL7v2) standard. The HL7 Version 2 genomics component of the HL7 Laboratory Results Interface (HL7v2 LRI) standard specifies a formalism for the structured communication of genomic data from lab to EHR. We previously described an open-source tool (vcf2fhir) that converts VCF files into HL7 FHIR format. In this report, we describe how the utility has been extended to output HL7v2 LRI data that contains both variants and variant annotations (e.g., predicted phenotypes and therapeutic implications). Using this HL7v2 converter, we implemented an automated pipeline for moving structured genomic data from the clinical laboratory to EHR. We developed an open source hl7v2GenomicsExtractor that converts genomic interpretation report files into a series of HL7v2 observations conformant to HL7v2 LRI. We further enhanced the converter to produce output conformant to Epic's genomic import specification and to support alternative input formats. An automated pipeline for pushing standards-based structured genomic data directly into the EHR was successfully implemented, where genetic variant data and the clinical annotations are now both available to be viewed in the EHR through Epic's genomics module. Issues encountered in the development and deployment of the HL7v2 converter primarily revolved around data variability issues, primarily lack of a standardized representation of data elements within various genomic interpretation report files. The technical implementation of a HL7v2 message transformation to feed genomic variant and clinical annotation data into an EHR has been successful. In addition to genetic variant data, the implementation described here releases the valuable asset of clinically relevant genomic annotations provided by labs from static PDFs to calculable, structured data in EHR systems.</p></div>\",\"PeriodicalId\":37769,\"journal\":{\"name\":\"Journal of Pathology Informatics\",\"volume\":\"14 \",\"pages\":\"Article 100330\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/08/9e/main.PMC10504540.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Pathology Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S215335392300144X\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/8/15 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Pathology Informatics","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S215335392300144X","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/8/15 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
Automated HL7v2 LRI informatics framework for streamlining genomics-EHR data integration
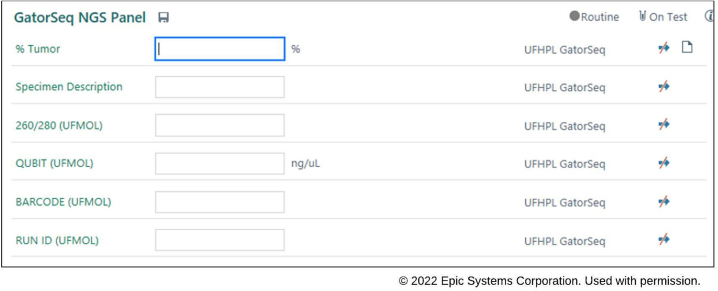
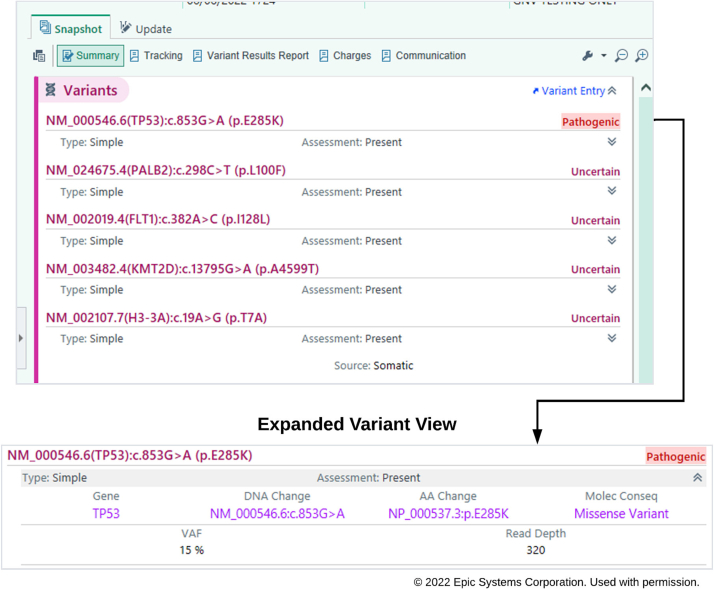
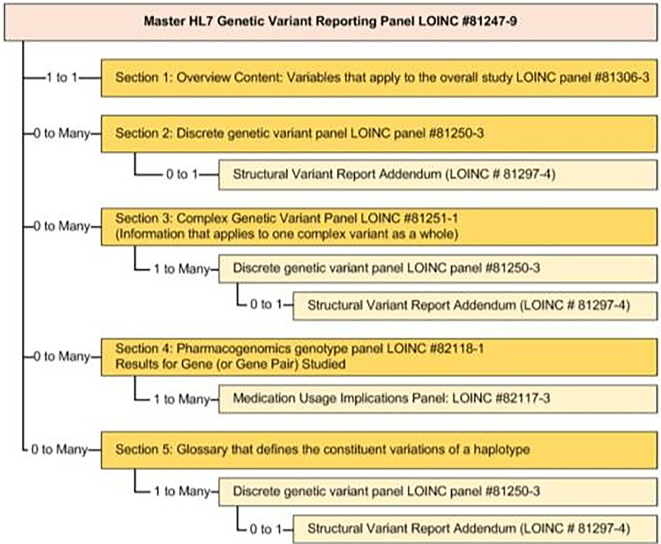
While VCF formatted files are the lingua franca of next-generation sequencing, most EHRs do not provide native VCF support. As a result, labs often must send non-structured PDF reports to the EHR. On the other hand, while FHIR adoption is growing, most EHRs support HL7 interoperability standards, particularly those based on the HL7 Version 2 (HL7v2) standard. The HL7 Version 2 genomics component of the HL7 Laboratory Results Interface (HL7v2 LRI) standard specifies a formalism for the structured communication of genomic data from lab to EHR. We previously described an open-source tool (vcf2fhir) that converts VCF files into HL7 FHIR format. In this report, we describe how the utility has been extended to output HL7v2 LRI data that contains both variants and variant annotations (e.g., predicted phenotypes and therapeutic implications). Using this HL7v2 converter, we implemented an automated pipeline for moving structured genomic data from the clinical laboratory to EHR. We developed an open source hl7v2GenomicsExtractor that converts genomic interpretation report files into a series of HL7v2 observations conformant to HL7v2 LRI. We further enhanced the converter to produce output conformant to Epic's genomic import specification and to support alternative input formats. An automated pipeline for pushing standards-based structured genomic data directly into the EHR was successfully implemented, where genetic variant data and the clinical annotations are now both available to be viewed in the EHR through Epic's genomics module. Issues encountered in the development and deployment of the HL7v2 converter primarily revolved around data variability issues, primarily lack of a standardized representation of data elements within various genomic interpretation report files. The technical implementation of a HL7v2 message transformation to feed genomic variant and clinical annotation data into an EHR has been successful. In addition to genetic variant data, the implementation described here releases the valuable asset of clinically relevant genomic annotations provided by labs from static PDFs to calculable, structured data in EHR systems.
期刊介绍:
The Journal of Pathology Informatics (JPI) is an open access peer-reviewed journal dedicated to the advancement of pathology informatics. This is the official journal of the Association for Pathology Informatics (API). The journal aims to publish broadly about pathology informatics and freely disseminate all articles worldwide. This journal is of interest to pathologists, informaticians, academics, researchers, health IT specialists, information officers, IT staff, vendors, and anyone with an interest in informatics. We encourage submissions from anyone with an interest in the field of pathology informatics. We publish all types of papers related to pathology informatics including original research articles, technical notes, reviews, viewpoints, commentaries, editorials, symposia, meeting abstracts, book reviews, and correspondence to the editors. All submissions are subject to rigorous peer review by the well-regarded editorial board and by expert referees in appropriate specialties.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
