{"title":"一种用于建议分类生成波斯语数据集的半监督方法","authors":"Leila Safari, Zanyar Mohammady","doi":"10.1007/s10579-023-09688-7","DOIUrl":null,"url":null,"abstract":"Suggestion mining has become a popular subject in the field of natural language processing (NLP) that is useful in areas like a service/product improvement. The purpose of this study is to provide an automated machine learning (ML) based approach to extract suggestions from Persian text. In this research, first, a novel two-step semi-supervised method has been proposed to generate a Persian dataset called ParsSugg, which is then used in the automatic classification of the user’s suggestions. The first step is manual labeling of data based on a proposed guideline, followed by a data augmentation phase. In the second step, using pre-trained Persian Bidirectional Encoder Representations from Transformers (ParsBERT) as a classifier and the data from the previous step, more data were labeled. The performance of various ML models, including Support Vector Machine (SVM), Random Forest (RF), Convolutional Neural Networks (CNN), Long Short Term Memory (LSTM), and the ParsBERT language model has been examined on the generated dataset. The F-score value of 97.27 for ParsBERT and about 94.5 for SVM and CNN classifiers were obtained for the suggestion class which is a promising result as the first research on suggestion classification on Persian texts. Also, the proposed guideline can be used for other NLP tasks, and the generated dataset can be used in other suggestion classification tasks.","PeriodicalId":49927,"journal":{"name":"Language Resources and Evaluation","volume":"11 1","pages":"0"},"PeriodicalIF":1.8000,"publicationDate":"2023-09-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A semi-supervised method to generate a persian dataset for suggestion classification\",\"authors\":\"Leila Safari, Zanyar Mohammady\",\"doi\":\"10.1007/s10579-023-09688-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Suggestion mining has become a popular subject in the field of natural language processing (NLP) that is useful in areas like a service/product improvement. The purpose of this study is to provide an automated machine learning (ML) based approach to extract suggestions from Persian text. In this research, first, a novel two-step semi-supervised method has been proposed to generate a Persian dataset called ParsSugg, which is then used in the automatic classification of the user’s suggestions. The first step is manual labeling of data based on a proposed guideline, followed by a data augmentation phase. In the second step, using pre-trained Persian Bidirectional Encoder Representations from Transformers (ParsBERT) as a classifier and the data from the previous step, more data were labeled. The performance of various ML models, including Support Vector Machine (SVM), Random Forest (RF), Convolutional Neural Networks (CNN), Long Short Term Memory (LSTM), and the ParsBERT language model has been examined on the generated dataset. The F-score value of 97.27 for ParsBERT and about 94.5 for SVM and CNN classifiers were obtained for the suggestion class which is a promising result as the first research on suggestion classification on Persian texts. Also, the proposed guideline can be used for other NLP tasks, and the generated dataset can be used in other suggestion classification tasks.\",\"PeriodicalId\":49927,\"journal\":{\"name\":\"Language Resources and Evaluation\",\"volume\":\"11 1\",\"pages\":\"0\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2023-09-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Language Resources and Evaluation\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s10579-023-09688-7\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Language Resources and Evaluation","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s10579-023-09688-7","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
A semi-supervised method to generate a persian dataset for suggestion classification
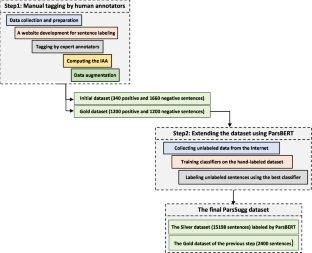
Suggestion mining has become a popular subject in the field of natural language processing (NLP) that is useful in areas like a service/product improvement. The purpose of this study is to provide an automated machine learning (ML) based approach to extract suggestions from Persian text. In this research, first, a novel two-step semi-supervised method has been proposed to generate a Persian dataset called ParsSugg, which is then used in the automatic classification of the user’s suggestions. The first step is manual labeling of data based on a proposed guideline, followed by a data augmentation phase. In the second step, using pre-trained Persian Bidirectional Encoder Representations from Transformers (ParsBERT) as a classifier and the data from the previous step, more data were labeled. The performance of various ML models, including Support Vector Machine (SVM), Random Forest (RF), Convolutional Neural Networks (CNN), Long Short Term Memory (LSTM), and the ParsBERT language model has been examined on the generated dataset. The F-score value of 97.27 for ParsBERT and about 94.5 for SVM and CNN classifiers were obtained for the suggestion class which is a promising result as the first research on suggestion classification on Persian texts. Also, the proposed guideline can be used for other NLP tasks, and the generated dataset can be used in other suggestion classification tasks.
期刊介绍:
Language Resources and Evaluation is the first publication devoted to the acquisition, creation, annotation, and use of language resources, together with methods for evaluation of resources, technologies, and applications.
Language resources include language data and descriptions in machine readable form used to assist and augment language processing applications, such as written or spoken corpora and lexica, multimodal resources, grammars, terminology or domain specific databases and dictionaries, ontologies, multimedia databases, etc., as well as basic software tools for their acquisition, preparation, annotation, management, customization, and use.
Evaluation of language resources concerns assessing the state-of-the-art for a given technology, comparing different approaches to a given problem, assessing the availability of resources and technologies for a given application, benchmarking, and assessing system usability and user satisfaction.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
