Betzy Clariza Torres-Zegarra, Wagner Rios-Garcia, Alvaro Micael Ñaña-Cordova, Karen Fatima Arteaga-Cisneros, Xiomara Cristina Benavente Chalco, Marina Atena Bustamante Ordoñez, Carlos Jesus Gutierrez Rios, Carlos Alberto Ramos Godoy, Kristell Luisa Teresa Panta Quezada, Jesus Daniel Gutierrez-Arratia, Javier Alejandro Flores-Cohaila
{"title":"ChatGPT、Bard、Claude和Bing在秘鲁国家执照医学考试中的表现:一项横断面研究。","authors":"Betzy Clariza Torres-Zegarra, Wagner Rios-Garcia, Alvaro Micael Ñaña-Cordova, Karen Fatima Arteaga-Cisneros, Xiomara Cristina Benavente Chalco, Marina Atena Bustamante Ordoñez, Carlos Jesus Gutierrez Rios, Carlos Alberto Ramos Godoy, Kristell Luisa Teresa Panta Quezada, Jesus Daniel Gutierrez-Arratia, Javier Alejandro Flores-Cohaila","doi":"10.3352/jeehp.2023.20.30","DOIUrl":null,"url":null,"abstract":"<p><strong>Purpose: </strong>We aimed to describe the performance and evaluate the educational value of justifications provided by artificial intelligence chatbots, including GPT-3.5, GPT-4, Bard, Claude, and Bing, on the Peruvian National Medical Licensing Examination (P-NLME).</p><p><strong>Methods: </strong>This was a cross-sectional analytical study. On July 25, 2023, each multiple-choice question (MCQ) from the P-NLME was entered into each chatbot (GPT-3, GPT-4, Bing, Bard, and Claude) 3 times. Then, 4 medical educators categorized the MCQs in terms of medical area, item type, and whether the MCQ required Peru-specific knowledge. They assessed the educational value of the justifications from the 2 top performers (GPT-4 and Bing).</p><p><strong>Results: </strong>GPT-4 scored 86.7% and Bing scored 82.2%, followed by Bard and Claude, and the historical performance of Peruvian examinees was 55%. Among the factors associated with correct answers, only MCQs that required Peru-specific knowledge had lower odds (odds ratio, 0.23; 95% confidence interval, 0.09-0.61), whereas the remaining factors showed no associations. In assessing the educational value of justifications provided by GPT-4 and Bing, neither showed any significant differences in certainty, usefulness, or potential use in the classroom.</p><p><strong>Conclusion: </strong>Among chatbots, GPT-4 and Bing were the top performers, with Bing performing better at Peru-specific MCQs. Moreover, the educational value of justifications provided by the GPT-4 and Bing could be deemed appropriate. However, it is essential to start addressing the educational value of these chatbots, rather than merely their performance on examinations.</p>","PeriodicalId":46098,"journal":{"name":"Journal of Educational Evaluation for Health Professions","volume":"20 ","pages":"30"},"PeriodicalIF":3.7000,"publicationDate":"2023-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11009012/pdf/","citationCount":"0","resultStr":"{\"title\":\"Performance of ChatGPT, Bard, Claude, and Bing on the Peruvian National Licensing Medical Examination: a cross-sectional study.\",\"authors\":\"Betzy Clariza Torres-Zegarra, Wagner Rios-Garcia, Alvaro Micael Ñaña-Cordova, Karen Fatima Arteaga-Cisneros, Xiomara Cristina Benavente Chalco, Marina Atena Bustamante Ordoñez, Carlos Jesus Gutierrez Rios, Carlos Alberto Ramos Godoy, Kristell Luisa Teresa Panta Quezada, Jesus Daniel Gutierrez-Arratia, Javier Alejandro Flores-Cohaila\",\"doi\":\"10.3352/jeehp.2023.20.30\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Purpose: </strong>We aimed to describe the performance and evaluate the educational value of justifications provided by artificial intelligence chatbots, including GPT-3.5, GPT-4, Bard, Claude, and Bing, on the Peruvian National Medical Licensing Examination (P-NLME).</p><p><strong>Methods: </strong>This was a cross-sectional analytical study. On July 25, 2023, each multiple-choice question (MCQ) from the P-NLME was entered into each chatbot (GPT-3, GPT-4, Bing, Bard, and Claude) 3 times. Then, 4 medical educators categorized the MCQs in terms of medical area, item type, and whether the MCQ required Peru-specific knowledge. They assessed the educational value of the justifications from the 2 top performers (GPT-4 and Bing).</p><p><strong>Results: </strong>GPT-4 scored 86.7% and Bing scored 82.2%, followed by Bard and Claude, and the historical performance of Peruvian examinees was 55%. Among the factors associated with correct answers, only MCQs that required Peru-specific knowledge had lower odds (odds ratio, 0.23; 95% confidence interval, 0.09-0.61), whereas the remaining factors showed no associations. In assessing the educational value of justifications provided by GPT-4 and Bing, neither showed any significant differences in certainty, usefulness, or potential use in the classroom.</p><p><strong>Conclusion: </strong>Among chatbots, GPT-4 and Bing were the top performers, with Bing performing better at Peru-specific MCQs. Moreover, the educational value of justifications provided by the GPT-4 and Bing could be deemed appropriate. However, it is essential to start addressing the educational value of these chatbots, rather than merely their performance on examinations.</p>\",\"PeriodicalId\":46098,\"journal\":{\"name\":\"Journal of Educational Evaluation for Health Professions\",\"volume\":\"20 \",\"pages\":\"30\"},\"PeriodicalIF\":3.7000,\"publicationDate\":\"2023-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11009012/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Educational Evaluation for Health Professions\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3352/jeehp.2023.20.30\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2023/11/20 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"EDUCATION, SCIENTIFIC DISCIPLINES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Educational Evaluation for Health Professions","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3352/jeehp.2023.20.30","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2023/11/20 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"EDUCATION, SCIENTIFIC DISCIPLINES","Score":null,"Total":0}
Performance of ChatGPT, Bard, Claude, and Bing on the Peruvian National Licensing Medical Examination: a cross-sectional study.
Purpose: We aimed to describe the performance and evaluate the educational value of justifications provided by artificial intelligence chatbots, including GPT-3.5, GPT-4, Bard, Claude, and Bing, on the Peruvian National Medical Licensing Examination (P-NLME).
Methods: This was a cross-sectional analytical study. On July 25, 2023, each multiple-choice question (MCQ) from the P-NLME was entered into each chatbot (GPT-3, GPT-4, Bing, Bard, and Claude) 3 times. Then, 4 medical educators categorized the MCQs in terms of medical area, item type, and whether the MCQ required Peru-specific knowledge. They assessed the educational value of the justifications from the 2 top performers (GPT-4 and Bing).
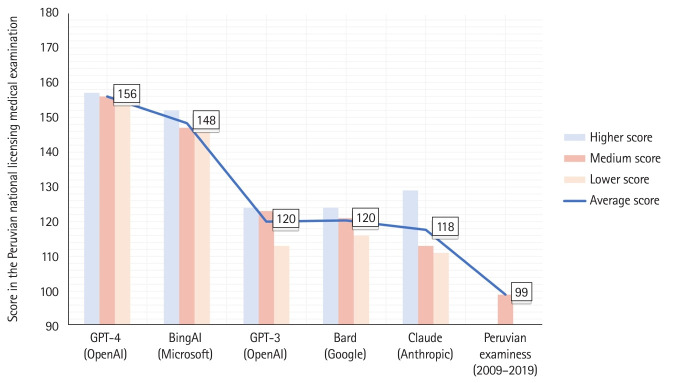
Results: GPT-4 scored 86.7% and Bing scored 82.2%, followed by Bard and Claude, and the historical performance of Peruvian examinees was 55%. Among the factors associated with correct answers, only MCQs that required Peru-specific knowledge had lower odds (odds ratio, 0.23; 95% confidence interval, 0.09-0.61), whereas the remaining factors showed no associations. In assessing the educational value of justifications provided by GPT-4 and Bing, neither showed any significant differences in certainty, usefulness, or potential use in the classroom.
Conclusion: Among chatbots, GPT-4 and Bing were the top performers, with Bing performing better at Peru-specific MCQs. Moreover, the educational value of justifications provided by the GPT-4 and Bing could be deemed appropriate. However, it is essential to start addressing the educational value of these chatbots, rather than merely their performance on examinations.
期刊介绍:
Journal of Educational Evaluation for Health Professions aims to provide readers the state-of-the art practical information on the educational evaluation for health professions so that to increase the quality of undergraduate, graduate, and continuing education. It is specialized in educational evaluation including adoption of measurement theory to medical health education, promotion of high stakes examination such as national licensing examinations, improvement of nationwide or international programs of education, computer-based testing, computerized adaptive testing, and medical health regulatory bodies. Its field comprises a variety of professions that address public medical health as following but not limited to: Care workers Dental hygienists Dental technicians Dentists Dietitians Emergency medical technicians Health educators Medical record technicians Medical technologists Midwives Nurses Nursing aides Occupational therapists Opticians Oriental medical doctors Oriental medicine dispensers Oriental pharmacists Pharmacists Physical therapists Physicians Prosthetists and Orthotists Radiological technologists Rehabilitation counselor Sanitary technicians Speech-language therapists.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
