Massimiliano Datres, Elisa Paolazzi, Marco Chierici, Matteo Pozzi, Antonio Colangelo, Marcello Dorian Donzella, Giuseppe Jurman
{"title":"基于内窥镜的IBD量化深度学习管道识别。","authors":"Massimiliano Datres, Elisa Paolazzi, Marco Chierici, Matteo Pozzi, Antonio Colangelo, Marcello Dorian Donzella, Giuseppe Jurman","doi":"10.1186/s13040-023-00350-0","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Discrimination between patients affected by inflammatory bowel diseases and healthy controls on the basis of endoscopic imaging is an challenging problem for machine learning models. Such task is used here as the testbed for a novel deep learning classification pipeline, powered by a set of solutions enhancing characterising elements such as reproducibility, interpretability, reduced computational workload, bias-free modeling and careful image preprocessing.</p><p><strong>Results: </strong>First, an automatic preprocessing procedure is devised, aimed to remove artifacts from clinical data, feeding then the resulting images to an aggregated per-patient model to mimic the clinicians decision process. The predictions are based on multiple snapshots obtained through resampling, reducing the risk of misleading outcomes by removing the low confidence predictions. Each patient's outcome is explained by returning the images the prediction is based upon, supporting clinicians in verifying diagnoses without the need for evaluating the full set of endoscopic images. As a major theoretical contribution, quantization is employed to reduce the complexity and the computational cost of the model, allowing its deployment on small power devices with an almost negligible 3% performance degradation. Such quantization procedure holds relevance not only in the context of per-patient models but also for assessing its feasibility in providing real-time support to clinicians even in low-resources environments. The pipeline is demonstrated on a private dataset of endoscopic images of 758 IBD patients and 601 healthy controls, achieving Matthews Correlation Coefficient 0.9 as top performance on test set.</p><p><strong>Conclusion: </strong>We highlighted how a comprehensive pre-processing pipeline plays a crucial role in identifying and removing artifacts from data, solving one of the principal challenges encountered when working with clinical data. Furthermore, we constructively showed how it is possible to emulate clinicians decision process and how it offers significant advantages, particularly in terms of explainability and trust within the healthcare context. Last but not least, we proved that quantization can be a useful tool to reduce the time and resources consumption with an acceptable degradation of the model performs. The quantization study proposed in this work points up the potential development of real-time quantized algorithms as valuable tools to support clinicians during endoscopy procedures.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"33"},"PeriodicalIF":6.1000,"publicationDate":"2023-11-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10675910/pdf/","citationCount":"0","resultStr":"{\"title\":\"Endoscopy-based IBD identification by a quantized deep learning pipeline.\",\"authors\":\"Massimiliano Datres, Elisa Paolazzi, Marco Chierici, Matteo Pozzi, Antonio Colangelo, Marcello Dorian Donzella, Giuseppe Jurman\",\"doi\":\"10.1186/s13040-023-00350-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Discrimination between patients affected by inflammatory bowel diseases and healthy controls on the basis of endoscopic imaging is an challenging problem for machine learning models. Such task is used here as the testbed for a novel deep learning classification pipeline, powered by a set of solutions enhancing characterising elements such as reproducibility, interpretability, reduced computational workload, bias-free modeling and careful image preprocessing.</p><p><strong>Results: </strong>First, an automatic preprocessing procedure is devised, aimed to remove artifacts from clinical data, feeding then the resulting images to an aggregated per-patient model to mimic the clinicians decision process. The predictions are based on multiple snapshots obtained through resampling, reducing the risk of misleading outcomes by removing the low confidence predictions. Each patient's outcome is explained by returning the images the prediction is based upon, supporting clinicians in verifying diagnoses without the need for evaluating the full set of endoscopic images. As a major theoretical contribution, quantization is employed to reduce the complexity and the computational cost of the model, allowing its deployment on small power devices with an almost negligible 3% performance degradation. Such quantization procedure holds relevance not only in the context of per-patient models but also for assessing its feasibility in providing real-time support to clinicians even in low-resources environments. The pipeline is demonstrated on a private dataset of endoscopic images of 758 IBD patients and 601 healthy controls, achieving Matthews Correlation Coefficient 0.9 as top performance on test set.</p><p><strong>Conclusion: </strong>We highlighted how a comprehensive pre-processing pipeline plays a crucial role in identifying and removing artifacts from data, solving one of the principal challenges encountered when working with clinical data. Furthermore, we constructively showed how it is possible to emulate clinicians decision process and how it offers significant advantages, particularly in terms of explainability and trust within the healthcare context. Last but not least, we proved that quantization can be a useful tool to reduce the time and resources consumption with an acceptable degradation of the model performs. The quantization study proposed in this work points up the potential development of real-time quantized algorithms as valuable tools to support clinicians during endoscopy procedures.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"16 1\",\"pages\":\"33\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2023-11-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10675910/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-023-00350-0\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00350-0","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Endoscopy-based IBD identification by a quantized deep learning pipeline.
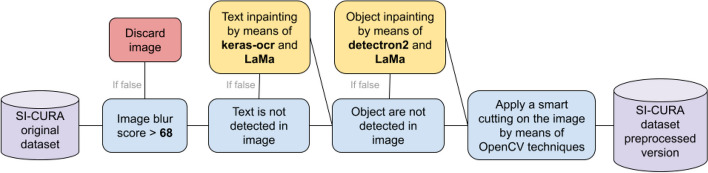
Background: Discrimination between patients affected by inflammatory bowel diseases and healthy controls on the basis of endoscopic imaging is an challenging problem for machine learning models. Such task is used here as the testbed for a novel deep learning classification pipeline, powered by a set of solutions enhancing characterising elements such as reproducibility, interpretability, reduced computational workload, bias-free modeling and careful image preprocessing.
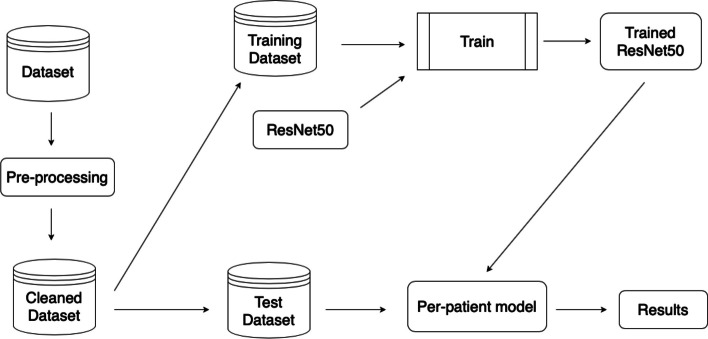
Results: First, an automatic preprocessing procedure is devised, aimed to remove artifacts from clinical data, feeding then the resulting images to an aggregated per-patient model to mimic the clinicians decision process. The predictions are based on multiple snapshots obtained through resampling, reducing the risk of misleading outcomes by removing the low confidence predictions. Each patient's outcome is explained by returning the images the prediction is based upon, supporting clinicians in verifying diagnoses without the need for evaluating the full set of endoscopic images. As a major theoretical contribution, quantization is employed to reduce the complexity and the computational cost of the model, allowing its deployment on small power devices with an almost negligible 3% performance degradation. Such quantization procedure holds relevance not only in the context of per-patient models but also for assessing its feasibility in providing real-time support to clinicians even in low-resources environments. The pipeline is demonstrated on a private dataset of endoscopic images of 758 IBD patients and 601 healthy controls, achieving Matthews Correlation Coefficient 0.9 as top performance on test set.
Conclusion: We highlighted how a comprehensive pre-processing pipeline plays a crucial role in identifying and removing artifacts from data, solving one of the principal challenges encountered when working with clinical data. Furthermore, we constructively showed how it is possible to emulate clinicians decision process and how it offers significant advantages, particularly in terms of explainability and trust within the healthcare context. Last but not least, we proved that quantization can be a useful tool to reduce the time and resources consumption with an acceptable degradation of the model performs. The quantization study proposed in this work points up the potential development of real-time quantized algorithms as valuable tools to support clinicians during endoscopy procedures.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
