{"title":"使用交叉验证方法选择时间序列模型:承诺和缺陷。","authors":"Siwei Liu, Di Jody Zhou","doi":"10.1111/bmsp.12330","DOIUrl":null,"url":null,"abstract":"<p>Vector autoregressive (VAR) modelling is widely employed in psychology for time series analyses of dynamic processes. However, the typically short time series in psychological studies can lead to overfitting of VAR models, impairing their predictive ability on unseen samples. Cross-validation (CV) methods are commonly recommended for assessing the predictive ability of statistical models. However, it is unclear how the performance of CV is affected by characteristics of time series data and the fitted models. In this simulation study, we examine the ability of two CV methods, namely,10-fold CV and blocked CV, in estimating the prediction errors of three time series models with increasing complexity (person-mean, AR, and VAR), and evaluate how their performance is affected by data characteristics. We then compare these CV methods to the traditional methods using the Akaike (AIC) and Bayesian (BIC) information criteria in their accuracy of selecting the most predictive models. We find that CV methods tend to underestimate prediction errors of simpler models, but overestimate prediction errors of VAR models, particularly when the number of observations is small. Nonetheless, CV methods, especially blocked CV, generally outperform the AIC and BIC. We conclude our study with a discussion on the implications of the findings and provide helpful guidelines for practice.</p>","PeriodicalId":55322,"journal":{"name":"British Journal of Mathematical & Statistical Psychology","volume":"77 2","pages":"337-355"},"PeriodicalIF":1.9000,"publicationDate":"2023-12-07","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/bmsp.12330","citationCount":"0","resultStr":"{\"title\":\"Using cross-validation methods to select time series models: Promises and pitfalls\",\"authors\":\"Siwei Liu, Di Jody Zhou\",\"doi\":\"10.1111/bmsp.12330\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Vector autoregressive (VAR) modelling is widely employed in psychology for time series analyses of dynamic processes. However, the typically short time series in psychological studies can lead to overfitting of VAR models, impairing their predictive ability on unseen samples. Cross-validation (CV) methods are commonly recommended for assessing the predictive ability of statistical models. However, it is unclear how the performance of CV is affected by characteristics of time series data and the fitted models. In this simulation study, we examine the ability of two CV methods, namely,10-fold CV and blocked CV, in estimating the prediction errors of three time series models with increasing complexity (person-mean, AR, and VAR), and evaluate how their performance is affected by data characteristics. We then compare these CV methods to the traditional methods using the Akaike (AIC) and Bayesian (BIC) information criteria in their accuracy of selecting the most predictive models. We find that CV methods tend to underestimate prediction errors of simpler models, but overestimate prediction errors of VAR models, particularly when the number of observations is small. Nonetheless, CV methods, especially blocked CV, generally outperform the AIC and BIC. We conclude our study with a discussion on the implications of the findings and provide helpful guidelines for practice.</p>\",\"PeriodicalId\":55322,\"journal\":{\"name\":\"British Journal of Mathematical & Statistical Psychology\",\"volume\":\"77 2\",\"pages\":\"337-355\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2023-12-07\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/bmsp.12330\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"British Journal of Mathematical & Statistical Psychology\",\"FirstCategoryId\":\"102\",\"ListUrlMain\":\"https://bpspsychub.onlinelibrary.wiley.com/doi/10.1111/bmsp.12330\",\"RegionNum\":3,\"RegionCategory\":\"心理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"British Journal of Mathematical & Statistical Psychology","FirstCategoryId":"102","ListUrlMain":"https://bpspsychub.onlinelibrary.wiley.com/doi/10.1111/bmsp.12330","RegionNum":3,"RegionCategory":"心理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICS, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Using cross-validation methods to select time series models: Promises and pitfalls
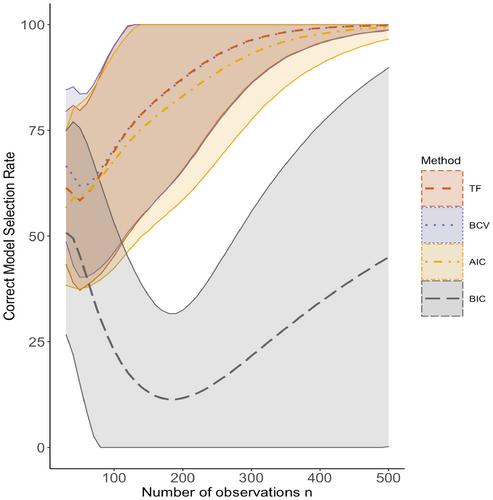
Vector autoregressive (VAR) modelling is widely employed in psychology for time series analyses of dynamic processes. However, the typically short time series in psychological studies can lead to overfitting of VAR models, impairing their predictive ability on unseen samples. Cross-validation (CV) methods are commonly recommended for assessing the predictive ability of statistical models. However, it is unclear how the performance of CV is affected by characteristics of time series data and the fitted models. In this simulation study, we examine the ability of two CV methods, namely,10-fold CV and blocked CV, in estimating the prediction errors of three time series models with increasing complexity (person-mean, AR, and VAR), and evaluate how their performance is affected by data characteristics. We then compare these CV methods to the traditional methods using the Akaike (AIC) and Bayesian (BIC) information criteria in their accuracy of selecting the most predictive models. We find that CV methods tend to underestimate prediction errors of simpler models, but overestimate prediction errors of VAR models, particularly when the number of observations is small. Nonetheless, CV methods, especially blocked CV, generally outperform the AIC and BIC. We conclude our study with a discussion on the implications of the findings and provide helpful guidelines for practice.
期刊介绍:
The British Journal of Mathematical and Statistical Psychology publishes articles relating to areas of psychology which have a greater mathematical or statistical aspect of their argument than is usually acceptable to other journals including:
• mathematical psychology
• statistics
• psychometrics
• decision making
• psychophysics
• classification
• relevant areas of mathematics, computing and computer software
These include articles that address substantitive psychological issues or that develop and extend techniques useful to psychologists. New models for psychological processes, new approaches to existing data, critiques of existing models and improved algorithms for estimating the parameters of a model are examples of articles which may be favoured.




 分享
分享

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
