{"title":"利用基因组数据和电子健康记录的机器学习方法识别抗核抗体阳性患者的系统性红斑狼疮。","authors":"Chih-Wei Chung, Seng-Cho Chou, Tzu-Hung Hsiao, Grace Joyce Zhang, Yu-Fang Chung, Yi-Ming Chen","doi":"10.1186/s13040-023-00352-y","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Although the 2019 EULAR/ACR classification criteria for systemic lupus erythematosus (SLE) has required at least a positive anti-nuclear antibody (ANA) titer (≥ 1:80), it remains challenging for clinicians to identify patients with SLE. This study aimed to develop a machine learning (ML) approach to assist in the detection of SLE patients using genomic data and electronic health records.</p><p><strong>Methods: </strong>Participants with a positive ANA (≥ 1:80) were enrolled from the Taiwan Precision Medicine Initiative cohort. The Taiwan Biobank version 2 array was used to detect single nucleotide polymorphism (SNP) data. Six ML models, Logistic Regression, Random Forest (RF), Support Vector Machine, Light Gradient Boosting Machine, Gradient Tree Boosting, and Extreme Gradient Boosting (XGB), were used to identify SLE patients. The importance of the clinical and genetic features was determined by Shapley Additive Explanation (SHAP) values. A logistic regression model was applied to identify genetic variations associated with SLE in the subset of patients with an ANA equal to or exceeding 1:640.</p><p><strong>Results: </strong>A total of 946 SLE and 1,892 non-SLE controls were included in this analysis. Among the six ML models, RF and XGB demonstrated superior performance in the differentiation of SLE from non-SLE. The leading features in the SHAP diagram were anti-double strand DNA antibodies, ANA titers, AC4 ANA pattern, polygenic risk scores, complement levels, and SNPs. Additionally, in the subgroup with a high ANA titer (≥ 1:640), six SNPs positively associated with SLE and five SNPs negatively correlated with SLE were discovered.</p><p><strong>Conclusions: </strong>ML approaches offer the potential to assist in diagnosing SLE and uncovering novel SNPs in a group of patients with autoimmunity.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"17 1","pages":"1"},"PeriodicalIF":6.1000,"publicationDate":"2024-01-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10770905/pdf/","citationCount":"0","resultStr":"{\"title\":\"Machine learning approaches to identify systemic lupus erythematosus in anti-nuclear antibody-positive patients using genomic data and electronic health records.\",\"authors\":\"Chih-Wei Chung, Seng-Cho Chou, Tzu-Hung Hsiao, Grace Joyce Zhang, Yu-Fang Chung, Yi-Ming Chen\",\"doi\":\"10.1186/s13040-023-00352-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Although the 2019 EULAR/ACR classification criteria for systemic lupus erythematosus (SLE) has required at least a positive anti-nuclear antibody (ANA) titer (≥ 1:80), it remains challenging for clinicians to identify patients with SLE. This study aimed to develop a machine learning (ML) approach to assist in the detection of SLE patients using genomic data and electronic health records.</p><p><strong>Methods: </strong>Participants with a positive ANA (≥ 1:80) were enrolled from the Taiwan Precision Medicine Initiative cohort. The Taiwan Biobank version 2 array was used to detect single nucleotide polymorphism (SNP) data. Six ML models, Logistic Regression, Random Forest (RF), Support Vector Machine, Light Gradient Boosting Machine, Gradient Tree Boosting, and Extreme Gradient Boosting (XGB), were used to identify SLE patients. The importance of the clinical and genetic features was determined by Shapley Additive Explanation (SHAP) values. A logistic regression model was applied to identify genetic variations associated with SLE in the subset of patients with an ANA equal to or exceeding 1:640.</p><p><strong>Results: </strong>A total of 946 SLE and 1,892 non-SLE controls were included in this analysis. Among the six ML models, RF and XGB demonstrated superior performance in the differentiation of SLE from non-SLE. The leading features in the SHAP diagram were anti-double strand DNA antibodies, ANA titers, AC4 ANA pattern, polygenic risk scores, complement levels, and SNPs. Additionally, in the subgroup with a high ANA titer (≥ 1:640), six SNPs positively associated with SLE and five SNPs negatively correlated with SLE were discovered.</p><p><strong>Conclusions: </strong>ML approaches offer the potential to assist in diagnosing SLE and uncovering novel SNPs in a group of patients with autoimmunity.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"17 1\",\"pages\":\"1\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2024-01-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10770905/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-023-00352-y\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00352-y","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
背景:尽管2019年EULAR/ACR系统性红斑狼疮(SLE)分类标准要求抗核抗体(ANA)滴度至少为阳性(≥1:80),但临床医生识别SLE患者仍面临挑战。本研究旨在开发一种机器学习(ML)方法,利用基因组数据和电子健康记录协助检测系统性红斑狼疮患者:方法:从台湾精准医疗计划队列中选取ANA阳性(≥ 1:80)的参与者。使用台湾生物库第二版阵列检测单核苷酸多态性(SNP)数据。研究人员使用逻辑回归、随机森林(RF)、支持向量机、轻梯度提升机、梯度树提升和极端梯度提升(XGB)等六种多重L模型来识别系统性红斑狼疮患者。临床和遗传特征的重要性由夏普利加性解释(SHAP)值决定。在 ANA 等于或超过 1:640 的患者子集中,采用逻辑回归模型确定与系统性红斑狼疮相关的遗传变异:结果:共有 946 名系统性红斑狼疮患者和 1,892 名非系统性红斑狼疮对照患者参与了此次分析。在六个 ML 模型中,RF 和 XGB 在区分系统性红斑狼疮和非系统性红斑狼疮方面表现优异。SHAP图中的主要特征是抗双链DNA抗体、ANA滴度、AC4 ANA模式、多基因风险评分、补体水平和SNPs。此外,在 ANA 滴度较高(≥ 1:640)的亚组中,发现了 6 个与系统性红斑狼疮正相关的 SNPs 和 5 个与系统性红斑狼疮负相关的 SNPs:ML方法有可能帮助诊断系统性红斑狼疮,并在一组自身免疫患者中发现新的SNPs。
Machine learning approaches to identify systemic lupus erythematosus in anti-nuclear antibody-positive patients using genomic data and electronic health records.
Background: Although the 2019 EULAR/ACR classification criteria for systemic lupus erythematosus (SLE) has required at least a positive anti-nuclear antibody (ANA) titer (≥ 1:80), it remains challenging for clinicians to identify patients with SLE. This study aimed to develop a machine learning (ML) approach to assist in the detection of SLE patients using genomic data and electronic health records.
Methods: Participants with a positive ANA (≥ 1:80) were enrolled from the Taiwan Precision Medicine Initiative cohort. The Taiwan Biobank version 2 array was used to detect single nucleotide polymorphism (SNP) data. Six ML models, Logistic Regression, Random Forest (RF), Support Vector Machine, Light Gradient Boosting Machine, Gradient Tree Boosting, and Extreme Gradient Boosting (XGB), were used to identify SLE patients. The importance of the clinical and genetic features was determined by Shapley Additive Explanation (SHAP) values. A logistic regression model was applied to identify genetic variations associated with SLE in the subset of patients with an ANA equal to or exceeding 1:640.
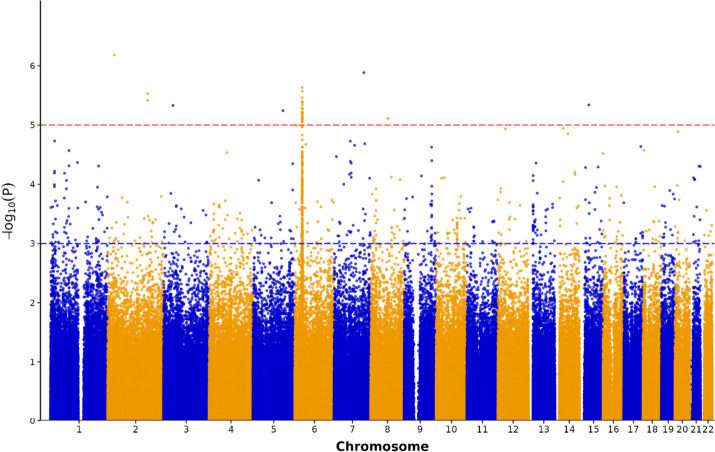
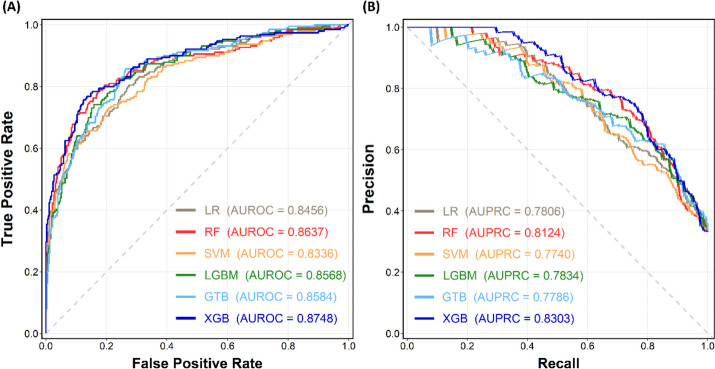
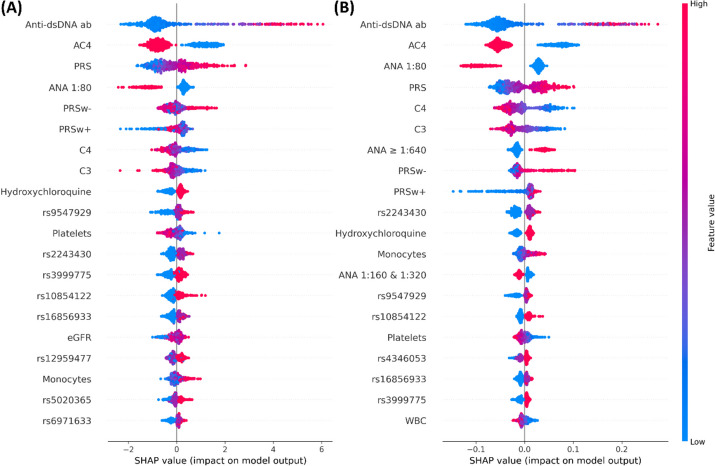
Results: A total of 946 SLE and 1,892 non-SLE controls were included in this analysis. Among the six ML models, RF and XGB demonstrated superior performance in the differentiation of SLE from non-SLE. The leading features in the SHAP diagram were anti-double strand DNA antibodies, ANA titers, AC4 ANA pattern, polygenic risk scores, complement levels, and SNPs. Additionally, in the subgroup with a high ANA titer (≥ 1:640), six SNPs positively associated with SLE and five SNPs negatively correlated with SLE were discovered.
Conclusions: ML approaches offer the potential to assist in diagnosing SLE and uncovering novel SNPs in a group of patients with autoimmunity.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
