Omid Rohanian, Mohammadmahdi Nouriborji, Hannah Jauncey, Samaneh Kouchaki, Farhad Nooralahzadeh, ISARIC Clinical Characterisation Group, Lei Clifton, Laura Merson, David A. Clifton
{"title":"用于临床自然语言处理的轻量级转换器","authors":"Omid Rohanian, Mohammadmahdi Nouriborji, Hannah Jauncey, Samaneh Kouchaki, Farhad Nooralahzadeh, ISARIC Clinical Characterisation Group, Lei Clifton, Laura Merson, David A. Clifton","doi":"10.1017/s1351324923000542","DOIUrl":null,"url":null,"abstract":"<p>Specialised pre-trained language models are becoming more frequent in Natural language Processing (NLP) since they can potentially outperform models trained on generic texts. BioBERT (Sanh et al., Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. <span>arXiv preprint arXiv: 1910.01108</span>, 2019) and BioClinicalBERT (Alsentzer et al., Publicly available clinical bert embeddings. In <span>Proceedings of the 2nd Clinical Natural Language Processing Workshop</span>, pp. 72–78, 2019) are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like knowledge distillation, it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries, etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from <span><span><img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240111120239472-0609:S1351324923000542:S1351324923000542_inline1.png\"><span data-mathjax-type=\"texmath\"><span>$15$</span></span></img></span></span> million to <span><span><img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240111120239472-0609:S1351324923000542:S1351324923000542_inline2.png\"><span data-mathjax-type=\"texmath\"><span>$65$</span></span></img></span></span> million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.</p>","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"165 1","pages":""},"PeriodicalIF":1.9000,"publicationDate":"2024-01-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Lightweight transformers for clinical natural language processing\",\"authors\":\"Omid Rohanian, Mohammadmahdi Nouriborji, Hannah Jauncey, Samaneh Kouchaki, Farhad Nooralahzadeh, ISARIC Clinical Characterisation Group, Lei Clifton, Laura Merson, David A. Clifton\",\"doi\":\"10.1017/s1351324923000542\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Specialised pre-trained language models are becoming more frequent in Natural language Processing (NLP) since they can potentially outperform models trained on generic texts. BioBERT (Sanh et al., Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. <span>arXiv preprint arXiv: 1910.01108</span>, 2019) and BioClinicalBERT (Alsentzer et al., Publicly available clinical bert embeddings. In <span>Proceedings of the 2nd Clinical Natural Language Processing Workshop</span>, pp. 72–78, 2019) are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like knowledge distillation, it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries, etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from <span><span><img data-mimesubtype=\\\"png\\\" data-type=\\\"\\\" src=\\\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240111120239472-0609:S1351324923000542:S1351324923000542_inline1.png\\\"><span data-mathjax-type=\\\"texmath\\\"><span>$15$</span></span></img></span></span> million to <span><span><img data-mimesubtype=\\\"png\\\" data-type=\\\"\\\" src=\\\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240111120239472-0609:S1351324923000542:S1351324923000542_inline2.png\\\"><span data-mathjax-type=\\\"texmath\\\"><span>$65$</span></span></img></span></span> million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.</p>\",\"PeriodicalId\":49143,\"journal\":{\"name\":\"Natural Language Engineering\",\"volume\":\"165 1\",\"pages\":\"\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2024-01-12\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Natural Language Engineering\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1017/s1351324923000542\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Natural Language Engineering","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1017/s1351324923000542","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
专业的预训练语言模型在自然语言处理(NLP)领域越来越常见,因为它们有可能超越在通用文本上训练的模型。BioBERT(Sanh等人,Distilbert,Bert的蒸馏版本:更小、更快、更便宜、更轻。ArXiv预印本arXiv:1910.01108,2019)和BioClinicalBERT(Alsentzer等人,公开可用的临床Bert嵌入。In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pp.这些模型中有很多都是过度参数化和资源密集型的,但由于采用了知识提炼等技术,我们有可能创建出性能几乎与大型模型相当的小型模型。在这项工作中,我们特别关注开发用于处理临床文本(即病程进展记录、出院摘要等)的紧凑型语言模型。我们利用知识提炼和持续学习技术开发了许多高效的轻量级临床转换器,参数数量从 1,500 万美元到 6,500 万美元不等。这些模型的性能可与 BioBERT 和 ClinicalBioBERT 等大型模型相媲美,而且明显优于其他基于一般或生物医学数据训练的紧凑型模型。我们在多个标准数据集上进行了广泛的评估,涵盖了一系列临床文本挖掘任务,包括自然语言推理、关系提取、命名实体识别和序列分类。据我们所知,这是第一项专门针对临床 NLP 任务创建高效紧凑转换器的综合性研究。本研究中使用的模型和代码可分别在我们的 Huggingface 简介 https://huggingface.co/nlpie 和 Github 页面 https://github.com/nlpie-research/Lightweight-Clinical-Transformers 上找到,从而提高了我们研究成果的可重复性。
Lightweight transformers for clinical natural language processing
Specialised pre-trained language models are becoming more frequent in Natural language Processing (NLP) since they can potentially outperform models trained on generic texts. BioBERT (Sanh et al., Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv: 1910.01108, 2019) and BioClinicalBERT (Alsentzer et al., Publicly available clinical bert embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pp. 72–78, 2019) are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like knowledge distillation, it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries, etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from $15$ million to $65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
期刊介绍:
Natural Language Engineering meets the needs of professionals and researchers working in all areas of computerised language processing, whether from the perspective of theoretical or descriptive linguistics, lexicology, computer science or engineering. Its aim is to bridge the gap between traditional computational linguistics research and the implementation of practical applications with potential real-world use. As well as publishing research articles on a broad range of topics - from text analysis, machine translation, information retrieval and speech analysis and generation to integrated systems and multi modal interfaces - it also publishes special issues on specific areas and technologies within these topics, an industry watch column and book reviews.
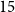 $15$ million to
$15$ million to 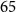 $65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
$65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.



 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
