Pub Date : 2024-05-14DOI: 10.1017/s1351324924000032
Robert Dale
The technical and mainstream media’s headline coverage of AI invariably centers around the often astounding abilities demonstrated by large language models. That’s hardly surprising, since to all intents and purposes that’s where the newsworthy magic of generative AI lies. But it takes a village to raise a child: behind the scenes, there’s an entire ecosystem that supports the development and deployment of these models and the applications that are built on top of them. Some parts of that ecosystem are dominated by the Big Tech incumbents, but there are also many niches where start-ups are aiming to gain a foothold. We take a look at some components of that ecosystem, with a particular focus on ideas that have led to investment in start-ups over the last year or so.
{"title":"Start-up activity in the LLM ecosystem","authors":"Robert Dale","doi":"10.1017/s1351324924000032","DOIUrl":"https://doi.org/10.1017/s1351324924000032","url":null,"abstract":"<p>The technical and mainstream media’s headline coverage of AI invariably centers around the often astounding abilities demonstrated by large language models. That’s hardly surprising, since to all intents and purposes that’s where the newsworthy magic of generative AI lies. But it takes a village to raise a child: behind the scenes, there’s an entire ecosystem that supports the development and deployment of these models and the applications that are built on top of them. Some parts of that ecosystem are dominated by the Big Tech incumbents, but there are also many niches where start-ups are aiming to gain a foothold. We take a look at some components of that ecosystem, with a particular focus on ideas that have led to investment in start-ups over the last year or so.</p>","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"147 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2024-05-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"140931060","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-25DOI: 10.1017/s135132492300058x
Jens Dörpinghaus
Here we present an improved approach for automated annotation of New Testament corpora with cross-lingual semantic concordance based on Strong’s numbers. Based on already annotated texts, they provide references to the original Greek words. Since scientific editions and translations of biblical texts are often not available for scientific purposes and are rarely freely available, there is a lack of up-to-date training data. In addition, since annotation, curation, and quality control of alignments between these texts are expensive, there is a lack of available biblical resources for scholars. We present two improved approaches to the problem, based on dictionaries and already annotated biblical texts. We provide a detailed evaluation of annotated and unannotated translations. We also discuss a proof of concept based on English and German New Testament translations. The results presented in this paper are novel and, to our knowledge, unique. They show promising performance, although further research is needed.
{"title":"Automated annotation of parallel bible corpora with cross-lingual semantic concordance","authors":"Jens Dörpinghaus","doi":"10.1017/s135132492300058x","DOIUrl":"https://doi.org/10.1017/s135132492300058x","url":null,"abstract":"<p>Here we present an improved approach for automated annotation of New Testament corpora with cross-lingual semantic concordance based on Strong’s numbers. Based on already annotated texts, they provide references to the original Greek words. Since scientific editions and translations of biblical texts are often not available for scientific purposes and are rarely freely available, there is a lack of up-to-date training data. In addition, since annotation, curation, and quality control of alignments between these texts are expensive, there is a lack of available biblical resources for scholars. We present two improved approaches to the problem, based on dictionaries and already annotated biblical texts. We provide a detailed evaluation of annotated and unannotated translations. We also discuss a proof of concept based on English and German New Testament translations. The results presented in this paper are novel and, to our knowledge, unique. They show promising performance, although further research is needed.</p>","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"10 3 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2024-01-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139553565","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-25DOI: 10.1017/s1351324924000019
Feng Hou, Ruili Wang, See-Kiong Ng, Fangyi Zhu, Michael Witbrock, Steven F. Cahan, Lily Chen, Xiaoyun Jia
Coreference resolution is the task of identifying and clustering mentions that refer to the same entity in a document. Based on state-of-the-art deep learning approaches, end-to-end coreference resolution considers all spans as candidate mentions and tackles mention detection and coreference resolution simultaneously. Recently, researchers have attempted to incorporate document-level context using higher-order inference (HOI) to improve end-to-end coreference resolution. However, HOI methods have been shown to have marginal or even negative impact on coreference resolution. In this paper, we reveal the reasons for the negative impact of HOI coreference resolution. Contextualized representations (e.g., those produced by BERT) for building span embeddings have been shown to be highly anisotropic. We show that HOI actually increases and thus worsens the anisotropy of span embeddings and makes it difficult to distinguish between related but distinct entities (e.g., pilots and flight attendants). Instead of using HOI, we propose two methods, Less-Anisotropic Internal Representations (LAIR) and Data Augmentation with Document Synthesis and Mention Swap (DSMS), to learn less-anisotropic span embeddings for coreference resolution. LAIR uses a linear aggregation of the first layer and the topmost layer of contextualized embeddings. DSMS generates more diversified examples of related but distinct entities by synthesizing documents and by mention swapping. Our experiments show that less-anisotropic span embeddings improve the performance significantly (+2.8 F1 gain on the OntoNotes benchmark) reaching new state-of-the-art performance on the GAP dataset.
核心参照解析是对文档中指向同一实体的提及进行识别和聚类的任务。端到端核心参照解析基于最先进的深度学习方法,将所有跨度视为候选提及,并同时处理提及检测和核心参照解析。最近,研究人员尝试使用高阶推理(HOI)将文档级上下文纳入其中,以改进端到端的核心参照解析。然而,HOI 方法对核心参照解析的影响微乎其微,甚至是负面的。在本文中,我们将揭示 HOI 核心参照解析产生负面影响的原因。用于构建跨度嵌入的语境化表征(例如由 BERT 生成的表征)已被证明具有高度各向异性。我们的研究表明,HOI 实际上会增加跨度嵌入的各向异性,从而使其恶化,并使相关但不同的实体(如飞行员和空乘人员)难以区分。我们没有使用 HOI,而是提出了两种方法,即各向异性较小的内部表示法(LAIR)和使用文档合成和提及交换的数据增强法(DSMS),来学习各向异性较小的跨度嵌入,以解决核心参照问题。LAIR 使用第一层和最顶层上下文嵌入的线性聚合。DSMS 通过综合文档和提及交换生成相关但不同实体的更多样化示例。我们的实验表明,各向异性较小的跨度嵌入显著提高了性能(在 OntoNotes 基准上的 F1 增益为 +2.8),在 GAP 数据集上达到了新的一流性能。
{"title":"Anisotropic span embeddings and the negative impact of higher-order inference for coreference resolution: An empirical analysis","authors":"Feng Hou, Ruili Wang, See-Kiong Ng, Fangyi Zhu, Michael Witbrock, Steven F. Cahan, Lily Chen, Xiaoyun Jia","doi":"10.1017/s1351324924000019","DOIUrl":"https://doi.org/10.1017/s1351324924000019","url":null,"abstract":"<p>Coreference resolution is the task of identifying and clustering mentions that refer to the same entity in a document. Based on state-of-the-art deep learning approaches, end-to-end coreference resolution considers all spans as candidate mentions and tackles mention detection and coreference resolution simultaneously. Recently, researchers have attempted to incorporate document-level context using higher-order inference (HOI) to improve end-to-end coreference resolution. However, HOI methods have been shown to have marginal or even negative impact on coreference resolution. In this paper, we reveal the reasons for the negative impact of HOI coreference resolution. Contextualized representations (e.g., those produced by BERT) for building span embeddings have been shown to be highly anisotropic. We show that HOI actually increases and thus worsens the anisotropy of span embeddings and makes it difficult to distinguish between related but distinct entities (e.g., <span>pilots</span> and <span>flight attendants</span>). Instead of using HOI, we propose two methods, Less-Anisotropic Internal Representations (LAIR) and Data Augmentation with Document Synthesis and Mention Swap (DSMS), to learn less-anisotropic span embeddings for coreference resolution. LAIR uses a linear aggregation of the first layer and the topmost layer of contextualized embeddings. DSMS generates more diversified examples of related but distinct entities by synthesizing documents and by mention swapping. Our experiments show that less-anisotropic span embeddings improve the performance significantly (+2.8 F1 gain on the OntoNotes benchmark) reaching new state-of-the-art performance on the GAP dataset.</p>","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"10 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2024-01-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139553422","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-23DOI: 10.1017/s1351324923000566
Zihao Li, Matthew Shardlow
Recent work on text simplification has focused on the use of control tokens to further the state-of-the-art. However, it is not easy to further improve without an in-depth comprehension of the mechanisms underlying control tokens. One unexplored factor is the tokenization strategy, which we also explore. In this paper, we (1) reimplemented AudienCe-CEntric Sentence Simplification, (2) explored the effects and interactions of varying control tokens, (3) tested the influences of different tokenization strategies, (4) demonstrated how separate control tokens affect performance and (5) proposed new methods to predict the value of control tokens. We show variations of performance in the four control tokens separately. We also uncover how the design of control tokens could influence performance and give some suggestions for designing control tokens. We show the newly proposed method with higher performance in both SARI (a common scoring metric in text simplificaiton) and BERTScore (a score derived from the BERT language model) and potential in real applications.
{"title":"How do control tokens affect natural language generation tasks like text simplification","authors":"Zihao Li, Matthew Shardlow","doi":"10.1017/s1351324923000566","DOIUrl":"https://doi.org/10.1017/s1351324923000566","url":null,"abstract":"Recent work on text simplification has focused on the use of control tokens to further the state-of-the-art. However, it is not easy to further improve without an in-depth comprehension of the mechanisms underlying control tokens. One unexplored factor is the tokenization strategy, which we also explore. In this paper, we (1) reimplemented AudienCe-CEntric Sentence Simplification, (2) explored the effects and interactions of varying control tokens, (3) tested the influences of different tokenization strategies, (4) demonstrated how separate control tokens affect performance and (5) proposed new methods to predict the value of control tokens. We show variations of performance in the four control tokens separately. We also uncover how the design of control tokens could influence performance and give some suggestions for designing control tokens. We show the newly proposed method with higher performance in both SARI (a common scoring metric in text simplificaiton) and BERTScore (a score derived from the BERT language model) and potential in real applications.","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"56 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2024-01-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139553455","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-16DOI: 10.1017/s1351324923000578
Kenneth Church
Usage of large language models and chat bots will almost surely continue to grow, since they are so easy to use, and so (incredibly) credible. I would be more comfortable with this reality if we encouraged more evaluations with humans-in-the-loop to come up with a better characterization of when the machine can be trusted and when humans should intervene. This article will describe a homework assignment, where I asked my students to use tools such as chat bots and web search to write a number of essays. Even after considerable discussion in class on hallucinations, many of the essays were full of misinformation that should have been fact-checked. Apparently, it is easier to believe ChatGPT than to be skeptical. Fact-checking and web search are too much trouble.
{"title":"Emerging trends: When can users trust GPT, and when should they intervene?","authors":"Kenneth Church","doi":"10.1017/s1351324923000578","DOIUrl":"https://doi.org/10.1017/s1351324923000578","url":null,"abstract":"<p>Usage of large language models and chat bots will almost surely continue to grow, since they are so easy to use, and so (incredibly) credible. I would be more comfortable with this reality if we encouraged more evaluations with humans-in-the-loop to come up with a better characterization of when the machine can be trusted and when humans should intervene. This article will describe a homework assignment, where I asked my students to use tools such as chat bots and web search to write a number of essays. Even after considerable discussion in class on hallucinations, many of the essays were full of misinformation that should have been fact-checked. Apparently, it is easier to believe ChatGPT than to be skeptical. Fact-checking and web search are too much trouble.</p>","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"294 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2024-01-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139475363","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-12DOI: 10.1017/s1351324923000542
Omid Rohanian, Mohammadmahdi Nouriborji, Hannah Jauncey, Samaneh Kouchaki, Farhad Nooralahzadeh, ISARIC Clinical Characterisation Group, Lei Clifton, Laura Merson, David A. Clifton
Specialised pre-trained language models are becoming more frequent in Natural language Processing (NLP) since they can potentially outperform models trained on generic texts. BioBERT (Sanh et al., Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv: 1910.01108, 2019) and BioClinicalBERT (Alsentzer et al., Publicly available clinical bert embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pp. 72–78, 2019) are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like knowledge distillation, it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries, etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from $15$ million to $65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
专业的预训练语言模型在自然语言处理(NLP)领域越来越常见,因为它们有可能超越在通用文本上训练的模型。BioBERT(Sanh等人,Distilbert,Bert的蒸馏版本:更小、更快、更便宜、更轻。ArXiv预印本arXiv:1910.01108,2019)和BioClinicalBERT(Alsentzer等人,公开可用的临床Bert嵌入。In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pp.这些模型中有很多都是过度参数化和资源密集型的,但由于采用了知识提炼等技术,我们有可能创建出性能几乎与大型模型相当的小型模型。在这项工作中,我们特别关注开发用于处理临床文本(即病程进展记录、出院摘要等)的紧凑型语言模型。我们利用知识提炼和持续学习技术开发了许多高效的轻量级临床转换器,参数数量从 1,500 万美元到 6,500 万美元不等。这些模型的性能可与 BioBERT 和 ClinicalBioBERT 等大型模型相媲美,而且明显优于其他基于一般或生物医学数据训练的紧凑型模型。我们在多个标准数据集上进行了广泛的评估,涵盖了一系列临床文本挖掘任务,包括自然语言推理、关系提取、命名实体识别和序列分类。据我们所知,这是第一项专门针对临床 NLP 任务创建高效紧凑转换器的综合性研究。本研究中使用的模型和代码可分别在我们的 Huggingface 简介 https://huggingface.co/nlpie 和 Github 页面 https://github.com/nlpie-research/Lightweight-Clinical-Transformers 上找到,从而提高了我们研究成果的可重复性。
{"title":"Lightweight transformers for clinical natural language processing","authors":"Omid Rohanian, Mohammadmahdi Nouriborji, Hannah Jauncey, Samaneh Kouchaki, Farhad Nooralahzadeh, ISARIC Clinical Characterisation Group, Lei Clifton, Laura Merson, David A. Clifton","doi":"10.1017/s1351324923000542","DOIUrl":"https://doi.org/10.1017/s1351324923000542","url":null,"abstract":"<p>Specialised pre-trained language models are becoming more frequent in Natural language Processing (NLP) since they can potentially outperform models trained on generic texts. BioBERT (Sanh et al., Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. <span>arXiv preprint arXiv: 1910.01108</span>, 2019) and BioClinicalBERT (Alsentzer et al., Publicly available clinical bert embeddings. In <span>Proceedings of the 2nd Clinical Natural Language Processing Workshop</span>, pp. 72–78, 2019) are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like knowledge distillation, it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries, etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from <span><span><img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240111120239472-0609:S1351324923000542:S1351324923000542_inline1.png\"><span data-mathjax-type=\"texmath\"><span>$15$</span></span></img></span></span> million to <span><span><img data-mimesubtype=\"png\" data-type=\"\" src=\"https://static.cambridge.org/binary/version/id/urn:cambridge.org:id:binary:20240111120239472-0609:S1351324923000542:S1351324923000542_inline2.png\"><span data-mathjax-type=\"texmath\"><span>$65$</span></span></img></span></span> million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.</p>","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"165 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2024-01-12","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139462167","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-09DOI: 10.1017/s1351324923000372
Michael Higgins, Dominic Widdows, Beth Ann Hockey, Akshay Hazare, Kristen Howell, Gwen Christian, Sujit Mathi, Chris Brew, Andrew Maurer, George Bonev, Matthew Dunn, Joseph Bradley
Automatic dialog systems have become a mainstream part of online customer service. Many such systems are built, maintained, and improved by customer service specialists, rather than dialog systems engineers and computer programmers. As conversations between people and machines become commonplace, it is critical to understand what is working, what is not, and what actions can be taken to reduce the frequency of inappropriate system responses. These analyses and recommendations need to be presented in terms that directly reflect the user experience rather than the internal dialog processing. This paper introduces and explains the use of Actionable Conversational Quality Indicators (ACQIs), which are used both to recognize parts of dialogs that can be improved and to recommend how to improve them. This combines benefits of previous approaches, some of which have focused on producing dialog quality scoring while others have sought to categorize the types of errors the dialog system is making. We demonstrate the effectiveness of using ACQIs on LivePerson internal dialog systems used in commercial customer service applications and on the publicly available LEGOv2 conversational dataset. We report on the annotation and analysis of conversational datasets showing which ACQIs are important to fix in various situations. The annotated datasets are then used to build a predictive model which uses a turn-based vector embedding of the message texts and achieves a 79% weighted average f1-measure at the task of finding the correct ACQI for a given conversation. We predict that if such a model worked perfectly, the range of potential improvement actions a bot-builder must consider at each turn could be reduced by an average of 81%.
{"title":"Actionable conversational quality indicators for improving task-oriented dialog systems","authors":"Michael Higgins, Dominic Widdows, Beth Ann Hockey, Akshay Hazare, Kristen Howell, Gwen Christian, Sujit Mathi, Chris Brew, Andrew Maurer, George Bonev, Matthew Dunn, Joseph Bradley","doi":"10.1017/s1351324923000372","DOIUrl":"https://doi.org/10.1017/s1351324923000372","url":null,"abstract":"Automatic dialog systems have become a mainstream part of online customer service. Many such systems are built, maintained, and improved by customer service specialists, rather than dialog systems engineers and computer programmers. As conversations between people and machines become commonplace, it is critical to understand what is working, what is not, and what actions can be taken to reduce the frequency of inappropriate system responses. These analyses and recommendations need to be presented in terms that directly reflect the user experience rather than the internal dialog processing. This paper introduces and explains the use of Actionable Conversational Quality Indicators (ACQIs), which are used both to recognize parts of dialogs that can be improved and to recommend how to improve them. This combines benefits of previous approaches, some of which have focused on producing dialog quality scoring while others have sought to categorize the types of errors the dialog system is making. We demonstrate the effectiveness of using ACQIs on LivePerson internal dialog systems used in commercial customer service applications and on the publicly available LEGOv2 conversational dataset. We report on the annotation and analysis of conversational datasets showing which ACQIs are important to fix in various situations. The annotated datasets are then used to build a predictive model which uses a turn-based vector embedding of the message texts and achieves a 79% weighted average f1-measure at the task of finding the correct ACQI for a given conversation. We predict that if such a model worked perfectly, the range of potential improvement actions a bot-builder must consider at each turn could be reduced by an average of 81%.","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"151 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2024-01-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139410430","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2024-01-08DOI: 10.1017/s1351324923000554
Robert Dale
A lot has happened since OpenAI released ChatGPT to the public in November 2022. We review how things unfolded over the course of the year, tracking significant events and announcements from the tech giants leading the generative AI race and from other players of note; along the way we note the wider impacts of the technology’s progress.
{"title":"A year’s a long time in generative AI","authors":"Robert Dale","doi":"10.1017/s1351324923000554","DOIUrl":"https://doi.org/10.1017/s1351324923000554","url":null,"abstract":"<p>A lot has happened since OpenAI released ChatGPT to the public in November 2022. We review how things unfolded over the course of the year, tracking significant events and announcements from the tech giants leading the generative AI race and from other players of note; along the way we note the wider impacts of the technology’s progress.</p>","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"22 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2024-01-08","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"139397505","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
Pub Date : 2023-12-06DOI: 10.1017/s1351324923000517
Marcos Zampieri, Sara Rosenthal, Preslav Nakov, Alphaeus Dmonte, Tharindu Ranasinghe
The OffensEval shared tasks organized as part of SemEval-2019–2020 were very popular, attracting over 1300 participating teams. The two editions of the shared task helped advance the state of the art in offensive language identification by providing the community with benchmark datasets in Arabic, Danish, English, Greek, and Turkish. The datasets were annotated using the OLID hierarchical taxonomy, which since then has become the de facto standard in general offensive language identification research and was widely used beyond OffensEval. We present a survey of OffensEval and related competitions, and we discuss the main lessons learned. We further evaluate the performance of Large Language Models (LLMs), which have recently revolutionalized the field of Natural Language Processing. We use zero-shot prompting with six popular LLMs and zero-shot learning with two task-specific fine-tuned BERT models, and we compare the results against those of the top-performing teams at the OffensEval competitions. Our results show that while some LMMs such as Flan-T5 achieve competitive performance, in general LLMs lag behind the best OffensEval systems.
{"title":"OffensEval 2023: Offensive language identification in the age of Large Language Models","authors":"Marcos Zampieri, Sara Rosenthal, Preslav Nakov, Alphaeus Dmonte, Tharindu Ranasinghe","doi":"10.1017/s1351324923000517","DOIUrl":"https://doi.org/10.1017/s1351324923000517","url":null,"abstract":"<p>The OffensEval shared tasks organized as part of SemEval-2019–2020 were very popular, attracting over 1300 participating teams. The two editions of the shared task helped advance the state of the art in offensive language identification by providing the community with benchmark datasets in Arabic, Danish, English, Greek, and Turkish. The datasets were annotated using the OLID hierarchical taxonomy, which since then has become the <span>de facto</span> standard in general offensive language identification research and was widely used beyond OffensEval. We present a survey of OffensEval and related competitions, and we discuss the main lessons learned. We further evaluate the performance of Large Language Models (LLMs), which have recently revolutionalized the field of Natural Language Processing. We use zero-shot prompting with six popular LLMs and zero-shot learning with two task-specific fine-tuned BERT models, and we compare the results against those of the top-performing teams at the OffensEval competitions. Our results show that while some LMMs such as Flan-T5 achieve competitive performance, in general LLMs lag behind the best OffensEval systems.</p>","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"187 ","pages":""},"PeriodicalIF":2.5,"publicationDate":"2023-12-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"138506470","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
We are delighted to present the Special Issue on NLP Approaches to Offensive Content Online published in the Journal of Natural Language Engineering issue 29.6. We are happy to have received a total of 26 submissions to the special issue evidencing the interest of the NLP community in this topic. Our guest editorial board comprised of international experts in the field has worked hard to review all submissions over multiple rounds of peer review. Ultimately, we accepted nine articles to appear in this special issue.
{"title":"Preface: Special issue on NLP approaches to offensive content online","authors":"Marcos Zampieri, Isabelle Augenstein, Siddharth Krishnan, Joshua Melton, Preslav Nakov","doi":"10.1017/s1351324923000499","DOIUrl":"https://doi.org/10.1017/s1351324923000499","url":null,"abstract":"We are delighted to present the Special Issue on NLP Approaches to Offensive Content Online published in the Journal of Natural Language Engineering issue 29.6. We are happy to have received a total of 26 submissions to the special issue evidencing the interest of the NLP community in this topic. Our guest editorial board comprised of international experts in the field has worked hard to review all submissions over multiple rounds of peer review. Ultimately, we accepted nine articles to appear in this special issue.","PeriodicalId":49143,"journal":{"name":"Natural Language Engineering","volume":"16 1","pages":""},"PeriodicalIF":2.5,"publicationDate":"2023-12-06","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":null,"resultStr":null,"platform":"Semanticscholar","paperid":"138543432","PeriodicalName":null,"FirstCategoryId":null,"ListUrlMain":null,"RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":"","EPubDate":null,"PubModel":null,"JCR":null,"JCRName":null,"Score":null,"Total":0}
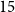
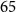
 扫码关注我们
扫码关注我们
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:
