Mohamad Zulfikrie Abas, Ken Li, Noran Naqiah Hairi, Wan Yuen Choo, Kim Sui Wan
{"title":"基于机器学习的 2 型糖尿病并发症预测模型(使用马来西亚国家糖尿病登记册):研究方案。","authors":"Mohamad Zulfikrie Abas, Ken Li, Noran Naqiah Hairi, Wan Yuen Choo, Kim Sui Wan","doi":"10.1177/22799036241231786","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The prevalence of diabetes in Malaysia is increasing, and identifying patients with higher risk of complications is crucial for effective management. The use of machine learning (ML) to develop prediction models has been shown to outperform non-ML models. This study aims to develop predictive models for Type 2 Diabetes (T2D) complications in Malaysia using ML techniques.</p><p><strong>Design and methods: </strong>This 10-year retrospective cohort study uses clinical audit datasets from Malaysian National Diabetes Registry from 2011 to 2021. T2D patients who received treatment in public health clinics in the southern region of Malaysia with at least two data points in 10 years are included. Patients with diabetes complications at baseline are excluded to ensure temporality between predictors and the target variable. Appropriate methods are used to address issues related to data cleaning, missing data imputation, data splitting, feature selection, and class imbalance. The study uses 7 ML algorithms, including logistic regression, support vector machine, <i>k</i>-nearest neighbours, decision tree, random forest, extreme gradient boosting, and light gradient boosting machine, to develop predictive models for four target variables: nephropathy, retinopathy, ischaemic heart disease, and stroke. Hyperparameter tuning is performed for each algorithm. The model training is performed using a stratified <i>k</i>-fold cross-validation technique. The best model for each algorithm is evaluated on a hold-out dataset using multiple metrics.</p><p><strong>Expected impact of the study on public health: </strong>The prediction model may be a valuable tool for diabetes management and secondary prevention by enabling earlier interventions and optimal resource allocation, leading to better health outcomes.</p>","PeriodicalId":45958,"journal":{"name":"Journal of Public Health Research","volume":"13 1","pages":"22799036241231786"},"PeriodicalIF":1.8000,"publicationDate":"2024-02-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10906050/pdf/","citationCount":"0","resultStr":"{\"title\":\"Machine learning based predictive model of Type 2 diabetes complications using Malaysian National Diabetes Registry: A study protocol.\",\"authors\":\"Mohamad Zulfikrie Abas, Ken Li, Noran Naqiah Hairi, Wan Yuen Choo, Kim Sui Wan\",\"doi\":\"10.1177/22799036241231786\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The prevalence of diabetes in Malaysia is increasing, and identifying patients with higher risk of complications is crucial for effective management. The use of machine learning (ML) to develop prediction models has been shown to outperform non-ML models. This study aims to develop predictive models for Type 2 Diabetes (T2D) complications in Malaysia using ML techniques.</p><p><strong>Design and methods: </strong>This 10-year retrospective cohort study uses clinical audit datasets from Malaysian National Diabetes Registry from 2011 to 2021. T2D patients who received treatment in public health clinics in the southern region of Malaysia with at least two data points in 10 years are included. Patients with diabetes complications at baseline are excluded to ensure temporality between predictors and the target variable. Appropriate methods are used to address issues related to data cleaning, missing data imputation, data splitting, feature selection, and class imbalance. The study uses 7 ML algorithms, including logistic regression, support vector machine, <i>k</i>-nearest neighbours, decision tree, random forest, extreme gradient boosting, and light gradient boosting machine, to develop predictive models for four target variables: nephropathy, retinopathy, ischaemic heart disease, and stroke. Hyperparameter tuning is performed for each algorithm. The model training is performed using a stratified <i>k</i>-fold cross-validation technique. The best model for each algorithm is evaluated on a hold-out dataset using multiple metrics.</p><p><strong>Expected impact of the study on public health: </strong>The prediction model may be a valuable tool for diabetes management and secondary prevention by enabling earlier interventions and optimal resource allocation, leading to better health outcomes.</p>\",\"PeriodicalId\":45958,\"journal\":{\"name\":\"Journal of Public Health Research\",\"volume\":\"13 1\",\"pages\":\"22799036241231786\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-02-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10906050/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Public Health Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1177/22799036241231786\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/1/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"PUBLIC, ENVIRONMENTAL & OCCUPATIONAL HEALTH\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Public Health Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1177/22799036241231786","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/1/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"PUBLIC, ENVIRONMENTAL & OCCUPATIONAL HEALTH","Score":null,"Total":0}
引用次数: 0
摘要
背景:马来西亚的糖尿病发病率正在上升,识别并发症风险较高的患者对有效管理至关重要。使用机器学习(ML)开发预测模型已被证明优于非ML模型。本研究旨在利用ML技术开发马来西亚2型糖尿病(T2D)并发症的预测模型:这项为期 10 年的回顾性队列研究使用了 2011 年至 2021 年马来西亚国家糖尿病登记处的临床审计数据集。研究对象包括在马来西亚南部地区公共卫生诊所接受治疗的 T2D 患者,10 年内至少有两个数据点。不包括基线糖尿病并发症患者,以确保预测因素与目标变量之间的时间性。采用适当的方法解决数据清理、缺失数据估算、数据分割、特征选择和类不平衡等相关问题。研究使用了 7 种 ML 算法,包括逻辑回归、支持向量机、k-近邻、决策树、随机森林、极梯度提升和轻梯度提升机,为肾病、视网膜病变、缺血性心脏病和中风这四个目标变量开发预测模型。每种算法都要进行超参数调整。模型训练采用分层 k 倍交叉验证技术。研究对公共卫生的预期影响:该预测模型将成为糖尿病管理和二级预防的重要工具,可实现早期干预和优化资源分配,从而改善健康状况。
Machine learning based predictive model of Type 2 diabetes complications using Malaysian National Diabetes Registry: A study protocol.
Background: The prevalence of diabetes in Malaysia is increasing, and identifying patients with higher risk of complications is crucial for effective management. The use of machine learning (ML) to develop prediction models has been shown to outperform non-ML models. This study aims to develop predictive models for Type 2 Diabetes (T2D) complications in Malaysia using ML techniques.
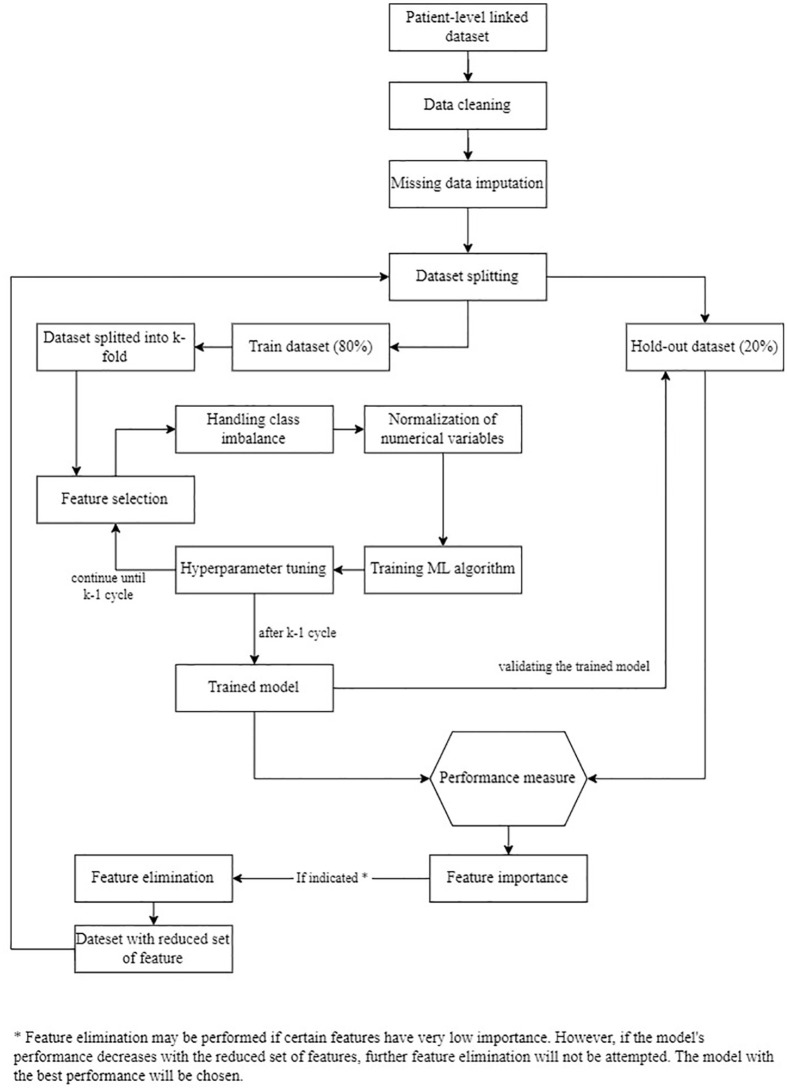
Design and methods: This 10-year retrospective cohort study uses clinical audit datasets from Malaysian National Diabetes Registry from 2011 to 2021. T2D patients who received treatment in public health clinics in the southern region of Malaysia with at least two data points in 10 years are included. Patients with diabetes complications at baseline are excluded to ensure temporality between predictors and the target variable. Appropriate methods are used to address issues related to data cleaning, missing data imputation, data splitting, feature selection, and class imbalance. The study uses 7 ML algorithms, including logistic regression, support vector machine, k-nearest neighbours, decision tree, random forest, extreme gradient boosting, and light gradient boosting machine, to develop predictive models for four target variables: nephropathy, retinopathy, ischaemic heart disease, and stroke. Hyperparameter tuning is performed for each algorithm. The model training is performed using a stratified k-fold cross-validation technique. The best model for each algorithm is evaluated on a hold-out dataset using multiple metrics.
Expected impact of the study on public health: The prediction model may be a valuable tool for diabetes management and secondary prevention by enabling earlier interventions and optimal resource allocation, leading to better health outcomes.
期刊介绍:
The Journal of Public Health Research (JPHR) is an online Open Access, peer-reviewed journal in the field of public health science. The aim of the journal is to stimulate debate and dissemination of knowledge in the public health field in order to improve efficacy, effectiveness and efficiency of public health interventions to improve health outcomes of populations. This aim can only be achieved by adopting a global and multidisciplinary approach. The Journal of Public Health Research publishes contributions from both the “traditional'' disciplines of public health, including hygiene, epidemiology, health education, environmental health, occupational health, health policy, hospital management, health economics, law and ethics as well as from the area of new health care fields including social science, communication science, eHealth and mHealth philosophy, health technology assessment, genetics research implications, population-mental health, gender and disparity issues, global and migration-related themes. In support of this approach, JPHR strongly encourages the use of real multidisciplinary approaches and analyses in the manuscripts submitted to the journal. In addition to Original research, Systematic Review, Meta-analysis, Meta-synthesis and Perspectives and Debate articles, JPHR publishes newsworthy Brief Reports, Letters and Study Protocols related to public health and public health management activities.






 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
