{"title":"利用 FPGA 实现可重新配置的并行前馈神经网络","authors":"Mohamed El-Sharkawy , Miran Wael , Maggie Mashaly , Eman Azab","doi":"10.1016/j.vlsi.2024.102176","DOIUrl":null,"url":null,"abstract":"<div><p>This paper proposes a novel hardware architecture for a Feed-Forward Neural Network (FFNN) with the objective of minimizing the number of execution clock cycles needed for the network’s computation. The proposed architecture depends mainly on using two physical layers that are multiplexed and reused during the computation of the FFNN to achieve an efficient parallel design. Two physical layers are designed to handle the computation of different sizes of Neural Networks (NN). The proposed FFNN architecture hardware resources are independent of the NN’s number of layers, instead, they depend only on the number of neurons in the largest layer. This versatile architecture serves as an accelerator in Deep Neural Network (DNN) computations as it exploits parallelism by making the two physical layers work in parallel through the computations. The proposed implementation was implemented with 18-bit fixed point representation reaching 200 MHz clock speed on a Spartan7 FPGA. Furthermore, the proposed architecture achieves a lower neuron computation factor compared to previous works in the literature.</p></div>","PeriodicalId":54973,"journal":{"name":"Integration-The Vlsi Journal","volume":"97 ","pages":"Article 102176"},"PeriodicalIF":2.5000,"publicationDate":"2024-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Re-configurable parallel Feed-Forward Neural Network implementation using FPGA\",\"authors\":\"Mohamed El-Sharkawy , Miran Wael , Maggie Mashaly , Eman Azab\",\"doi\":\"10.1016/j.vlsi.2024.102176\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>This paper proposes a novel hardware architecture for a Feed-Forward Neural Network (FFNN) with the objective of minimizing the number of execution clock cycles needed for the network’s computation. The proposed architecture depends mainly on using two physical layers that are multiplexed and reused during the computation of the FFNN to achieve an efficient parallel design. Two physical layers are designed to handle the computation of different sizes of Neural Networks (NN). The proposed FFNN architecture hardware resources are independent of the NN’s number of layers, instead, they depend only on the number of neurons in the largest layer. This versatile architecture serves as an accelerator in Deep Neural Network (DNN) computations as it exploits parallelism by making the two physical layers work in parallel through the computations. The proposed implementation was implemented with 18-bit fixed point representation reaching 200 MHz clock speed on a Spartan7 FPGA. Furthermore, the proposed architecture achieves a lower neuron computation factor compared to previous works in the literature.</p></div>\",\"PeriodicalId\":54973,\"journal\":{\"name\":\"Integration-The Vlsi Journal\",\"volume\":\"97 \",\"pages\":\"Article 102176\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2024-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Integration-The Vlsi Journal\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0167926024000397\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/3/4 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Integration-The Vlsi Journal","FirstCategoryId":"5","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0167926024000397","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/3/4 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
Re-configurable parallel Feed-Forward Neural Network implementation using FPGA
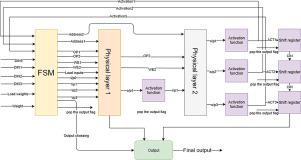
This paper proposes a novel hardware architecture for a Feed-Forward Neural Network (FFNN) with the objective of minimizing the number of execution clock cycles needed for the network’s computation. The proposed architecture depends mainly on using two physical layers that are multiplexed and reused during the computation of the FFNN to achieve an efficient parallel design. Two physical layers are designed to handle the computation of different sizes of Neural Networks (NN). The proposed FFNN architecture hardware resources are independent of the NN’s number of layers, instead, they depend only on the number of neurons in the largest layer. This versatile architecture serves as an accelerator in Deep Neural Network (DNN) computations as it exploits parallelism by making the two physical layers work in parallel through the computations. The proposed implementation was implemented with 18-bit fixed point representation reaching 200 MHz clock speed on a Spartan7 FPGA. Furthermore, the proposed architecture achieves a lower neuron computation factor compared to previous works in the literature.
期刊介绍:
Integration''s aim is to cover every aspect of the VLSI area, with an emphasis on cross-fertilization between various fields of science, and the design, verification, test and applications of integrated circuits and systems, as well as closely related topics in process and device technologies. Individual issues will feature peer-reviewed tutorials and articles as well as reviews of recent publications. The intended coverage of the journal can be assessed by examining the following (non-exclusive) list of topics:
Specification methods and languages; Analog/Digital Integrated Circuits and Systems; VLSI architectures; Algorithms, methods and tools for modeling, simulation, synthesis and verification of integrated circuits and systems of any complexity; Embedded systems; High-level synthesis for VLSI systems; Logic synthesis and finite automata; Testing, design-for-test and test generation algorithms; Physical design; Formal verification; Algorithms implemented in VLSI systems; Systems engineering; Heterogeneous systems.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
