{"title":"基于深度强化学习的人群疏散路径规划方法","authors":"Xiangdong Meng, Hong Liu, Wenhao Li","doi":"10.1007/s12652-024-04787-x","DOIUrl":null,"url":null,"abstract":"<p>Deep reinforcement learning (DRL) is suitable for solving complex path-planning problems due to its excellent ability to make continuous decisions in a complex environment. However, the increase in the population size in the crowd evacuation path-planning problem causes a substantial computational burden for the algorithm, which leads to an unsatisfactory efficiency of the current DRL algorithm. This paper presents a path planning method based on DRL for crowd evacuation to solve the problem. First, we divide crowds into groups based on their relationship and distance from each other and select leaders from them. Next, we expand the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) to propose an Optimized Multi-Agent Deep Deterministic Policy Gradient (OMADDPG) algorithm to obtain the global evacuation path. The OMADDPG algorithm uses the Cross-Entropy Method (CEM) to optimize policy and improve the neural network’s training efficiency by applying the Data Pruning (DP) algorithm. In addition, the social force model is improved, incorporating the relationship between individuals and psychological factors into the model. Finally, this paper combines the improved social force model and the OMADDPG algorithm. The OMADDPG algorithm transmits the path information to the leaders. Pedestrians in the environment are driven by the improved social force model to follow the leaders to complete the evacuation simulation. The method can use a leader to guide pedestrians safely arrive the exit and reduce evacuation time in different environments. The simulation results prove the efficiency of the path planning method.</p>","PeriodicalId":14959,"journal":{"name":"Journal of Ambient Intelligence and Humanized Computing","volume":"75 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-04-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A path planning method based on deep reinforcement learning for crowd evacuation\",\"authors\":\"Xiangdong Meng, Hong Liu, Wenhao Li\",\"doi\":\"10.1007/s12652-024-04787-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Deep reinforcement learning (DRL) is suitable for solving complex path-planning problems due to its excellent ability to make continuous decisions in a complex environment. However, the increase in the population size in the crowd evacuation path-planning problem causes a substantial computational burden for the algorithm, which leads to an unsatisfactory efficiency of the current DRL algorithm. This paper presents a path planning method based on DRL for crowd evacuation to solve the problem. First, we divide crowds into groups based on their relationship and distance from each other and select leaders from them. Next, we expand the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) to propose an Optimized Multi-Agent Deep Deterministic Policy Gradient (OMADDPG) algorithm to obtain the global evacuation path. The OMADDPG algorithm uses the Cross-Entropy Method (CEM) to optimize policy and improve the neural network’s training efficiency by applying the Data Pruning (DP) algorithm. In addition, the social force model is improved, incorporating the relationship between individuals and psychological factors into the model. Finally, this paper combines the improved social force model and the OMADDPG algorithm. The OMADDPG algorithm transmits the path information to the leaders. Pedestrians in the environment are driven by the improved social force model to follow the leaders to complete the evacuation simulation. The method can use a leader to guide pedestrians safely arrive the exit and reduce evacuation time in different environments. The simulation results prove the efficiency of the path planning method.</p>\",\"PeriodicalId\":14959,\"journal\":{\"name\":\"Journal of Ambient Intelligence and Humanized Computing\",\"volume\":\"75 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-04-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Ambient Intelligence and Humanized Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s12652-024-04787-x\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Ambient Intelligence and Humanized Computing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s12652-024-04787-x","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
A path planning method based on deep reinforcement learning for crowd evacuation
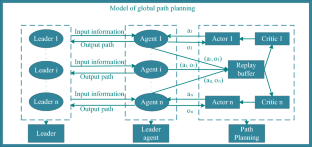
Deep reinforcement learning (DRL) is suitable for solving complex path-planning problems due to its excellent ability to make continuous decisions in a complex environment. However, the increase in the population size in the crowd evacuation path-planning problem causes a substantial computational burden for the algorithm, which leads to an unsatisfactory efficiency of the current DRL algorithm. This paper presents a path planning method based on DRL for crowd evacuation to solve the problem. First, we divide crowds into groups based on their relationship and distance from each other and select leaders from them. Next, we expand the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) to propose an Optimized Multi-Agent Deep Deterministic Policy Gradient (OMADDPG) algorithm to obtain the global evacuation path. The OMADDPG algorithm uses the Cross-Entropy Method (CEM) to optimize policy and improve the neural network’s training efficiency by applying the Data Pruning (DP) algorithm. In addition, the social force model is improved, incorporating the relationship between individuals and psychological factors into the model. Finally, this paper combines the improved social force model and the OMADDPG algorithm. The OMADDPG algorithm transmits the path information to the leaders. Pedestrians in the environment are driven by the improved social force model to follow the leaders to complete the evacuation simulation. The method can use a leader to guide pedestrians safely arrive the exit and reduce evacuation time in different environments. The simulation results prove the efficiency of the path planning method.
期刊介绍:
The purpose of JAIHC is to provide a high profile, leading edge forum for academics, industrial professionals, educators and policy makers involved in the field to contribute, to disseminate the most innovative researches and developments of all aspects of ambient intelligence and humanized computing, such as intelligent/smart objects, environments/spaces, and systems. The journal discusses various technical, safety, personal, social, physical, political, artistic and economic issues. The research topics covered by the journal are (but not limited to):
Pervasive/Ubiquitous Computing and Applications
Cognitive wireless sensor network
Embedded Systems and Software
Mobile Computing and Wireless Communications
Next Generation Multimedia Systems
Security, Privacy and Trust
Service and Semantic Computing
Advanced Networking Architectures
Dependable, Reliable and Autonomic Computing
Embedded Smart Agents
Context awareness, social sensing and inference
Multi modal interaction design
Ergonomics and product prototyping
Intelligent and self-organizing transportation networks & services
Healthcare Systems
Virtual Humans & Virtual Worlds
Wearables sensors and actuators




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
