Hannah Rose Kirk, Bertie Vidgen, Paul Röttger, Scott A. Hale
{"title":"根据个人情况个性化调整大型语言模型的益处、风险和界限","authors":"Hannah Rose Kirk, Bertie Vidgen, Paul Röttger, Scott A. Hale","doi":"10.1038/s42256-024-00820-y","DOIUrl":null,"url":null,"abstract":"Large language models (LLMs) undergo ‘alignment’ so that they better reflect human values or preferences, and are safer or more useful. However, alignment is intrinsically difficult because the hundreds of millions of people who now interact with LLMs have different preferences for language and conversational norms, operate under disparate value systems and hold diverse political beliefs. Typically, few developers or researchers dictate alignment norms, risking the exclusion or under-representation of various groups. Personalization is a new frontier in LLM development, whereby models are tailored to individuals. In principle, this could minimize cultural hegemony, enhance usefulness and broaden access. However, unbounded personalization poses risks such as large-scale profiling, privacy infringement, bias reinforcement and exploitation of the vulnerable. Defining the bounds of responsible and socially acceptable personalization is a non-trivial task beset with normative challenges. This article explores ‘personalized alignment’, whereby LLMs adapt to user-specific data, and highlights recent shifts in the LLM ecosystem towards a greater degree of personalization. Our main contribution explores the potential impact of personalized LLMs via a taxonomy of risks and benefits for individuals and society at large. We lastly discuss a key open question: what are appropriate bounds of personalization and who decides? Answering this normative question enables users to benefit from personalized alignment while safeguarding against harmful impacts for individuals and society. Tailoring the alignment of large language models (LLMs) to individuals is a new frontier in generative AI, but unbounded personalization can bring potential harm, such as large-scale profiling, privacy infringement and bias reinforcement. Kirk et al. develop a taxonomy for risks and benefits of personalized LLMs and discuss the need for normative decisions on what are acceptable bounds of personalization.","PeriodicalId":48533,"journal":{"name":"Nature Machine Intelligence","volume":"6 4","pages":"383-392"},"PeriodicalIF":23.9000,"publicationDate":"2024-04-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"The benefits, risks and bounds of personalizing the alignment of large language models to individuals\",\"authors\":\"Hannah Rose Kirk, Bertie Vidgen, Paul Röttger, Scott A. Hale\",\"doi\":\"10.1038/s42256-024-00820-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Large language models (LLMs) undergo ‘alignment’ so that they better reflect human values or preferences, and are safer or more useful. However, alignment is intrinsically difficult because the hundreds of millions of people who now interact with LLMs have different preferences for language and conversational norms, operate under disparate value systems and hold diverse political beliefs. Typically, few developers or researchers dictate alignment norms, risking the exclusion or under-representation of various groups. Personalization is a new frontier in LLM development, whereby models are tailored to individuals. In principle, this could minimize cultural hegemony, enhance usefulness and broaden access. However, unbounded personalization poses risks such as large-scale profiling, privacy infringement, bias reinforcement and exploitation of the vulnerable. Defining the bounds of responsible and socially acceptable personalization is a non-trivial task beset with normative challenges. This article explores ‘personalized alignment’, whereby LLMs adapt to user-specific data, and highlights recent shifts in the LLM ecosystem towards a greater degree of personalization. Our main contribution explores the potential impact of personalized LLMs via a taxonomy of risks and benefits for individuals and society at large. We lastly discuss a key open question: what are appropriate bounds of personalization and who decides? Answering this normative question enables users to benefit from personalized alignment while safeguarding against harmful impacts for individuals and society. Tailoring the alignment of large language models (LLMs) to individuals is a new frontier in generative AI, but unbounded personalization can bring potential harm, such as large-scale profiling, privacy infringement and bias reinforcement. Kirk et al. develop a taxonomy for risks and benefits of personalized LLMs and discuss the need for normative decisions on what are acceptable bounds of personalization.\",\"PeriodicalId\":48533,\"journal\":{\"name\":\"Nature Machine Intelligence\",\"volume\":\"6 4\",\"pages\":\"383-392\"},\"PeriodicalIF\":23.9000,\"publicationDate\":\"2024-04-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Nature Machine Intelligence\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.nature.com/articles/s42256-024-00820-y\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Nature Machine Intelligence","FirstCategoryId":"94","ListUrlMain":"https://www.nature.com/articles/s42256-024-00820-y","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
The benefits, risks and bounds of personalizing the alignment of large language models to individuals
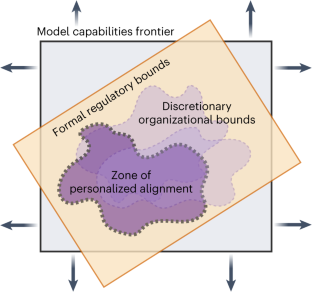
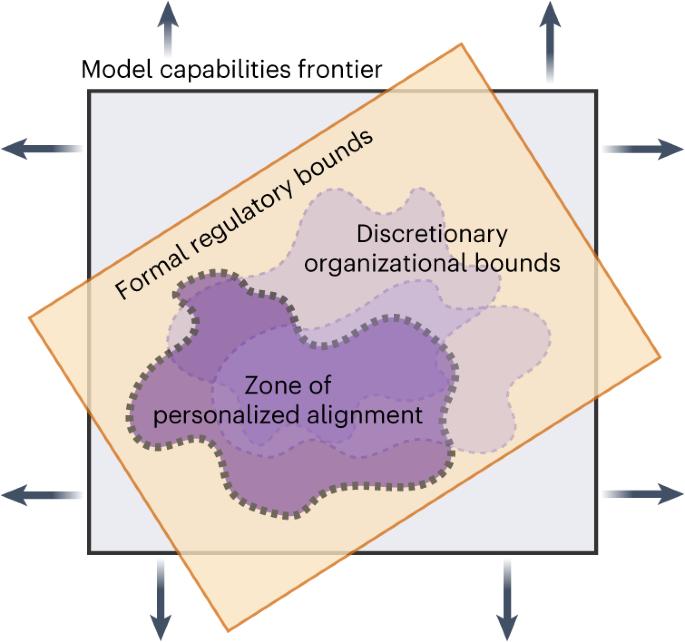
Large language models (LLMs) undergo ‘alignment’ so that they better reflect human values or preferences, and are safer or more useful. However, alignment is intrinsically difficult because the hundreds of millions of people who now interact with LLMs have different preferences for language and conversational norms, operate under disparate value systems and hold diverse political beliefs. Typically, few developers or researchers dictate alignment norms, risking the exclusion or under-representation of various groups. Personalization is a new frontier in LLM development, whereby models are tailored to individuals. In principle, this could minimize cultural hegemony, enhance usefulness and broaden access. However, unbounded personalization poses risks such as large-scale profiling, privacy infringement, bias reinforcement and exploitation of the vulnerable. Defining the bounds of responsible and socially acceptable personalization is a non-trivial task beset with normative challenges. This article explores ‘personalized alignment’, whereby LLMs adapt to user-specific data, and highlights recent shifts in the LLM ecosystem towards a greater degree of personalization. Our main contribution explores the potential impact of personalized LLMs via a taxonomy of risks and benefits for individuals and society at large. We lastly discuss a key open question: what are appropriate bounds of personalization and who decides? Answering this normative question enables users to benefit from personalized alignment while safeguarding against harmful impacts for individuals and society. Tailoring the alignment of large language models (LLMs) to individuals is a new frontier in generative AI, but unbounded personalization can bring potential harm, such as large-scale profiling, privacy infringement and bias reinforcement. Kirk et al. develop a taxonomy for risks and benefits of personalized LLMs and discuss the need for normative decisions on what are acceptable bounds of personalization.
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.




 分享
分享
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式: 扫码关注我们
扫码关注我们
